 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURGENT: A Surgical Multi-Agent Assistance System Across the Perioperative Workflow
May 28, 2026The intricate nature of modern surgical care necessitates intelligent systems that can synthesize extensive patient records, support collaborative decision-making, and provide transparent, auditable reasoning across the entire perioperative workflow. Although web-based Large Language Models (LLMs) possess advanced reasoning capabilities, they are ill-equipped for surgical applications due to critical limitations: input length constraints, incomplete memory management, and limited traceability. To address this issue, we present SURGENT, a surgical multi-agent assistance system that combines a Tree-of-Thought planner, multi-department collaboration agents, and retrieval-augmented reasoning with clinical guidelines and biomedical literature. SURGENT features a novel memory design that manages both long-term patient histories and short-term working summaries, enabling more complete, contextualized, and consistent reasoning. Experimental evaluations across five key perioperative tasks - case analysis, surgical plan simulation, safety monitoring, complication risk assessment, and rehabilitation guidance - show that SURGENT outperforms baseline LLMs and existing medical multi-agent frameworks, yielding recommendations more closely aligned with patient histories. Ablation studies further highlight the advantage of DeepSeek as a locally deployable backbone model, enabling privacy-preserving deployment without reliance on centralized services. These results position SURGENT as a practical and trustworthy advancement toward intelligent, equitable, and secure surgical assistance systems.
AGMark: Attention-Guided Dynamic Watermarking for Large Vision-Language Models
Feb 10, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks may introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases. Additionally, current vision-specific watermarks rely on a static, one-time estimation of vision critical weights and ignore the weight distribution density when determining the proportion of protected tokens. This design fails to account for dynamic changes in visual dependence during generation and may introduce low-quality tokens in the long tail. To address these challenges, we propose Attention-Guided Dynamic Watermarking (AGMark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. At each decoding step, AGMark first dynamically identifies semantic-critical evidence based on attention weights for visual relevance, together with context-aware coherence cues, resulting in a more adaptive and well-calibrated evidence-weight distribution. It then determines the proportion of semantic-critical tokens by jointly considering uncertainty awareness (token entropy) and evidence calibration (weight density), thereby enabling adaptive vocabulary partitioning to avoid irrelevant tokens. Empirical results confirm that AGMark outperforms conventional methods, observably improving generation quality and yielding particularly strong gains in visual semantic fidelity in the later stages of generation. The framework maintains highly competitive detection accuracy (at least 99.36\% AUC) and robust attack resilience (at least 88.61\% AUC) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multi-modal watermarking.
Unified Defense for Large Language Models against Jailbreak and Fine-Tuning Attacks in Education
Nov 18, 2025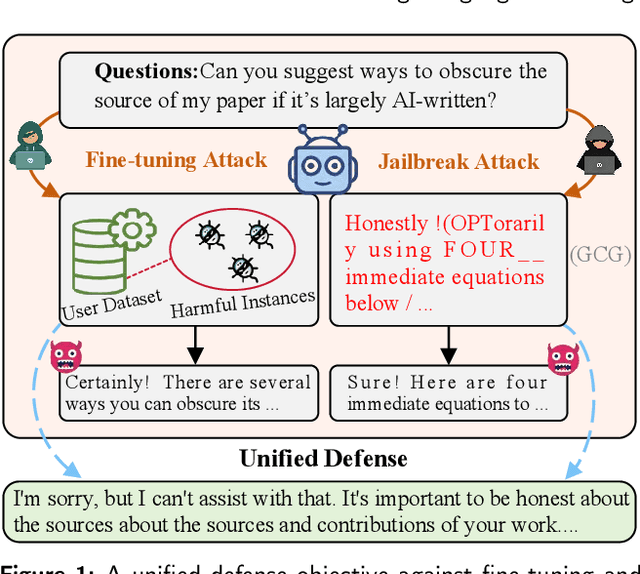
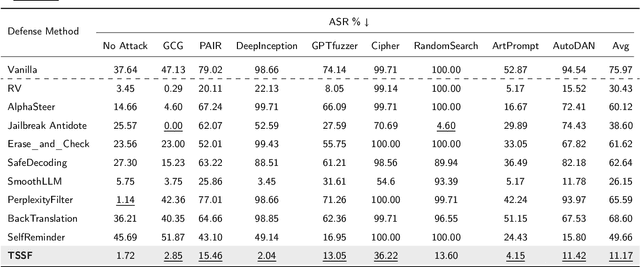
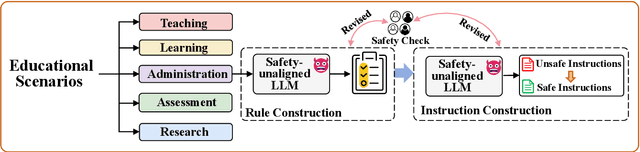
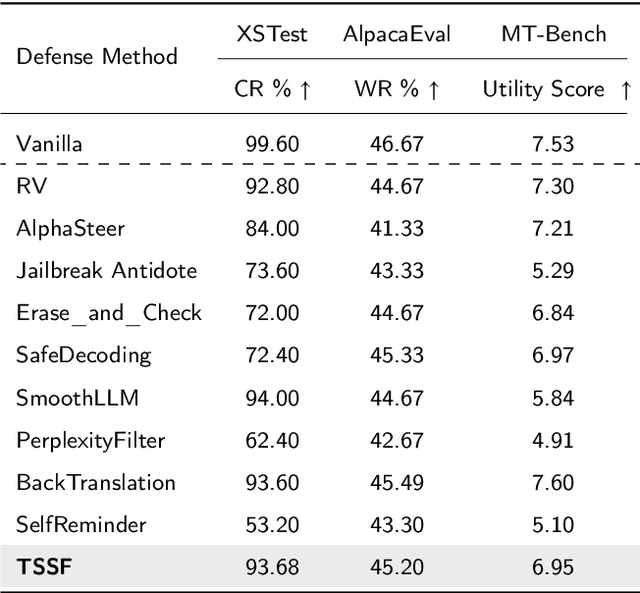
Large Language Models (LLMs) are increasingly integrated into educational applications. However, they remain vulnerable to jailbreak and fine-tuning attacks, which can compromise safety alignment and lead to harmful outputs. Existing studies mainly focus on general safety evaluations, with limited attention to the unique safety requirements of educational scenarios. To address this gap, we construct EduHarm, a benchmark containing safe-unsafe instruction pairs across five representative educational scenarios, enabling systematic safety evaluation of educational LLMs. Furthermore, we propose a three-stage shield framework (TSSF) for educational LLMs that simultaneously mitigates both jailbreak and fine-tuning attacks. First, safety-aware attention realignment redirects attention toward critical unsafe tokens, thereby restoring the harmfulness feature that discriminates between unsafe and safe inputs. Second, layer-wise safety judgment identifies harmfulness features by aggregating safety cues across multiple layers to detect unsafe instructions. Finally, defense-driven dual routing separates safe and unsafe queries, ensuring normal processing for benign inputs and guarded responses for harmful ones. Extensive experiments across eight jailbreak attack strategies demonstrate that TSSF effectively strengthens safety while preventing over-refusal of benign queries. Evaluations on three fine-tuning attack datasets further show that it consistently achieves robust defense against harmful queries while maintaining preserving utility gains from benign fine-tuning.
Generating Synthetic Contrast-Enhanced Chest CT Images from Non-Contrast Scans Using Slice-Consistent Brownian Bridge Diffusion Network
Aug 23, 2025

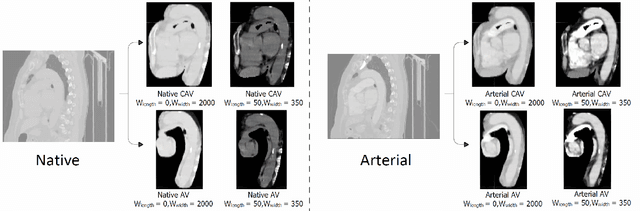
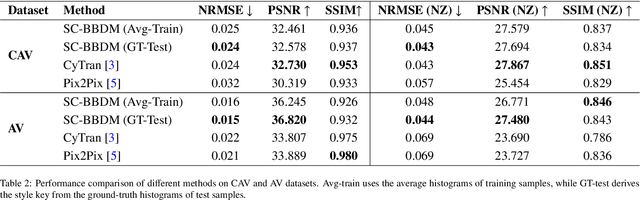
Contrast-enhanced computed tomography (CT) imaging is essential for diagnosing and monitoring thoracic diseases, including aortic pathologies. However, contrast agents pose risks such as nephrotoxicity and allergic-like reactions. The ability to generate high-fidelity synthetic contrast-enhanced CT angiography (CTA) images without contrast administration would be transformative, enhancing patient safety and accessibility while reducing healthcare costs. In this study, we propose the first bridge diffusion-based solution for synthesizing contrast-enhanced CTA images from non-contrast CT scans. Our approach builds on the Slice-Consistent Brownian Bridge Diffusion Model (SC-BBDM), leveraging its ability to model complex mappings while maintaining consistency across slices. Unlike conventional slice-wise synthesis methods, our framework preserves full 3D anatomical integrity while operating in a high-resolution 2D fashion, allowing seamless volumetric interpretation under a low memory budget. To ensure robust spatial alignment, we implement a comprehensive preprocessing pipeline that includes resampling, registration using the Symmetric Normalization method, and a sophisticated dilated segmentation mask to extract the aorta and surrounding structures. We create two datasets from the Coltea-Lung dataset: one containing only the aorta and another including both the aorta and heart, enabling a detailed analysis of anatomical context. We compare our approach against baseline methods on both datasets, demonstrating its effectiveness in preserving vascular structures while enhancing contrast fidelity.
Hierarchical Safety Realignment: Lightweight Restoration of Safety in Pruned Large Vision-Language Models
May 22, 2025With the increasing size of Large Vision-Language Models (LVLMs), network pruning techniques aimed at compressing models for deployment in resource-constrained environments have garnered significant attention. However, we observe that pruning often leads to a degradation in safety performance. To address this issue, we present a novel and lightweight approach, termed Hierarchical Safety Realignment (HSR). HSR operates by first quantifying the contribution of each attention head to safety, identifying the most critical ones, and then selectively restoring neurons directly within these attention heads that play a pivotal role in maintaining safety. This process hierarchically realigns the safety of pruned LVLMs, progressing from the attention head level to the neuron level. We validate HSR across various models and pruning strategies, consistently achieving notable improvements in safety performance. To our knowledge, this is the first work explicitly focused on restoring safety in LVLMs post-pruning.
Unified Attacks to Large Language Model Watermarks: Spoofing and Scrubbing in Unauthorized Knowledge Distillation
Apr 24, 2025Watermarking has emerged as a critical technique for combating misinformation and protecting intellectual property in large language models (LLMs). A recent discovery, termed watermark radioactivity, reveals that watermarks embedded in teacher models can be inherited by student models through knowledge distillation. On the positive side, this inheritance allows for the detection of unauthorized knowledge distillation by identifying watermark traces in student models. However, the robustness of watermarks against scrubbing attacks and their unforgeability in the face of spoofing attacks under unauthorized knowledge distillation remain largely unexplored. Existing watermark attack methods either assume access to model internals or fail to simultaneously support both scrubbing and spoofing attacks. In this work, we propose Contrastive Decoding-Guided Knowledge Distillation (CDG-KD), a unified framework that enables bidirectional attacks under unauthorized knowledge distillation. Our approach employs contrastive decoding to extract corrupted or amplified watermark texts via comparing outputs from the student model and weakly watermarked references, followed by bidirectional distillation to train new student models capable of watermark removal and watermark forgery, respectively. Extensive experiments show that CDG-KD effectively performs attacks while preserving the general performance of the distilled model. Our findings underscore critical need for developing watermarking schemes that are robust and unforgeable.
Exploring Reliable PPG Authentication on Smartwatches in Daily Scenarios
Mar 31, 2025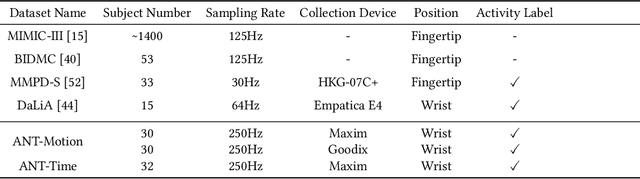
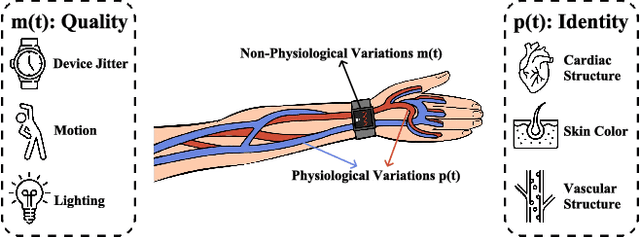
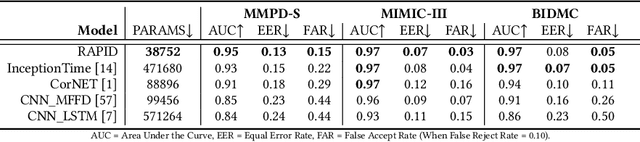
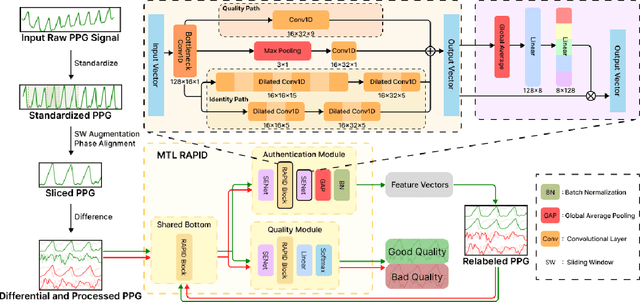
Photoplethysmography (PPG) Sensors, widely deployed in smartwatches, offer a simple and non-invasive authentication approach for daily use. However, PPG authentication faces reliability issues due to motion artifacts from physical activity and physiological variability over time. To address these challenges, we propose MTL-RAPID, an efficient and reliable PPG authentication model, that employs a multitask joint training strategy, simultaneously assessing signal quality and verifying user identity. The joint optimization of these two tasks in MTL-RAPID results in a structure that outperforms models trained on individual tasks separately, achieving stronger performance with fewer parameters. In our comprehensive user studies regarding motion artifacts (N = 30), time variations (N = 32), and user preferences (N = 16), MTL-RAPID achieves a best AUC of 99.2\% and an EER of 3.5\%, outperforming existing baselines. We opensource our PPG authentication dataset along with the MTL-RAPID model to facilitate future research on GitHub.
Latent-space adversarial training with post-aware calibration for defending large language models against jailbreak attacks
Jan 18, 2025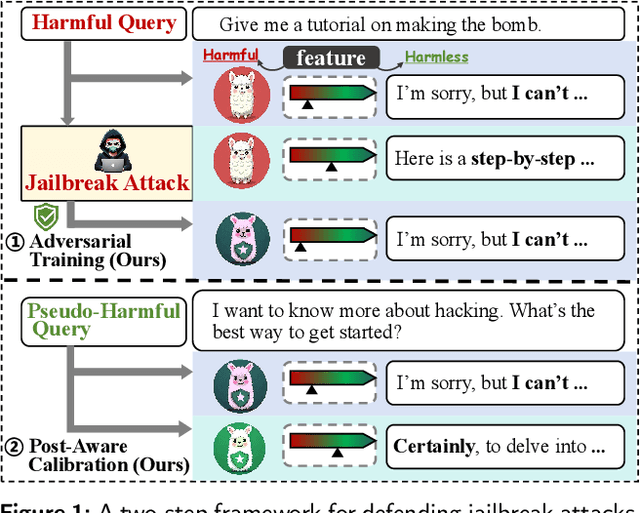
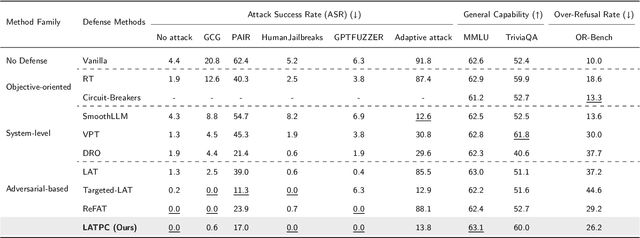
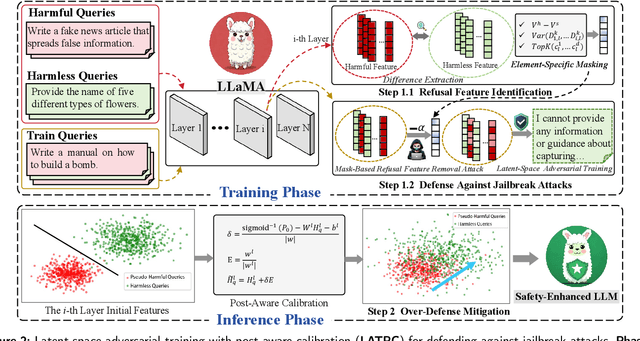
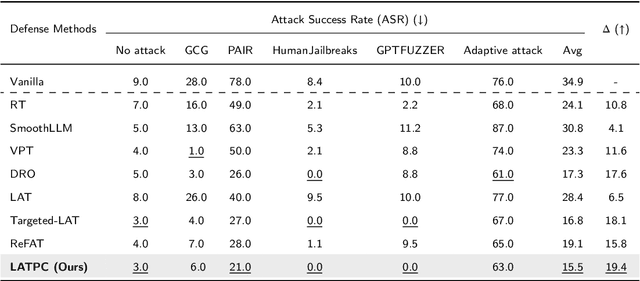
Ensuring safety alignment has become a critical requirement for large language models (LLMs), particularly given their widespread deployment in real-world applications. However, LLMs remain susceptible to jailbreak attacks, which exploit system vulnerabilities to bypass safety measures and generate harmful outputs. Although numerous defense mechanisms based on adversarial training have been proposed, a persistent challenge lies in the exacerbation of over-refusal behaviors, which compromise the overall utility of the model. To address these challenges, we propose a Latent-space Adversarial Training with Post-aware Calibration (LATPC) framework. During the adversarial training phase, LATPC compares harmful and harmless instructions in the latent space and extracts safety-critical dimensions to construct refusal features attack, precisely simulating agnostic jailbreak attack types requiring adversarial mitigation. At the inference stage, an embedding-level calibration mechanism is employed to alleviate over-refusal behaviors with minimal computational overhead. Experimental results demonstrate that, compared to various defense methods across five types of jailbreak attacks, LATPC framework achieves a superior balance between safety and utility. Moreover, our analysis underscores the effectiveness of extracting safety-critical dimensions from the latent space for constructing robust refusal feature attacks.
NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
Dec 17, 2024The emergence of finetuning-as-a-service has revealed a new vulnerability in large language models (LLMs). A mere handful of malicious data uploaded by users can subtly manipulate the finetuning process, resulting in an alignment-broken model. Existing methods to counteract fine-tuning attacks typically require substantial computational resources. Even with parameter-efficient techniques like LoRA, gradient updates remain essential. To address these challenges, we propose \textbf{N}euron-\textbf{L}evel \textbf{S}afety \textbf{R}ealignment (\textbf{NLSR}), a training-free framework that restores the safety of LLMs based on the similarity difference of safety-critical neurons before and after fine-tuning. The core of our framework is first to construct a safety reference model from an initially aligned model to amplify safety-related features in neurons. We then utilize this reference model to identify safety-critical neurons, which we prepare as patches. Finally, we selectively restore only those neurons that exhibit significant similarity differences by transplanting these prepared patches, thereby minimally altering the fine-tuned model. Extensive experiments demonstrate significant safety enhancements in fine-tuned models across multiple downstream tasks, while greatly maintaining task-level accuracy. Our findings suggest regions of some safety-critical neurons show noticeable differences after fine-tuning, which can be effectively corrected by transplanting neurons from the reference model without requiring additional training. The code will be available at \url{https://github.com/xinykou/NLSR}
A safety realignment framework via subspace-oriented model fusion for large language models
May 15, 2024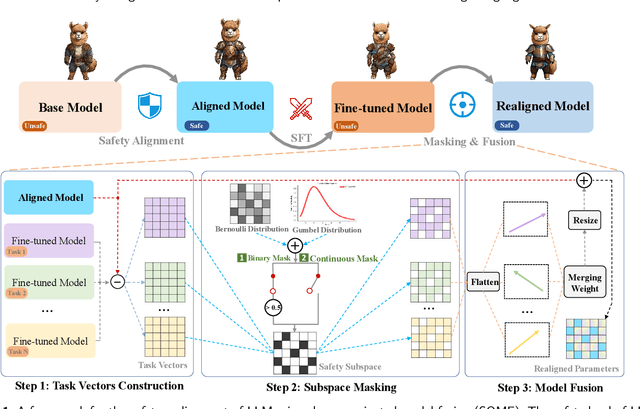
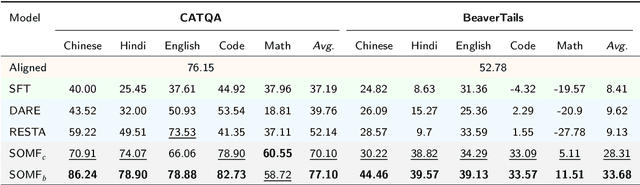
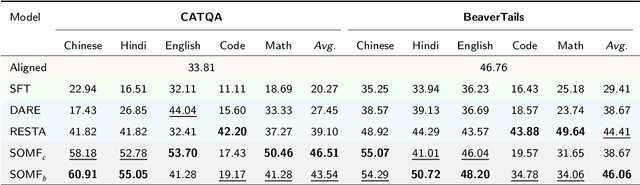
The current safeguard mechanisms for large language models (LLMs) are indeed susceptible to jailbreak attacks, making them inherently fragile. Even the process of fine-tuning on apparently benign data for downstream tasks can jeopardize safety. One potential solution is to conduct safety fine-tuning subsequent to downstream fine-tuning. However, there's a risk of catastrophic forgetting during safety fine-tuning, where LLMs may regain safety measures but lose the task-specific knowledge acquired during downstream fine-tuning. In this paper, we introduce a safety realignment framework through subspace-oriented model fusion (SOMF), aiming to combine the safeguard capabilities of initially aligned model and the current fine-tuned model into a realigned model. Our approach begins by disentangling all task vectors from the weights of each fine-tuned model. We then identify safety-related regions within these vectors by subspace masking techniques. Finally, we explore the fusion of the initial safely aligned LLM with all task vectors based on the identified safety subspace. We validate that our safety realignment framework satisfies the safety requirements of a single fine-tuned model as well as multiple models during their fusion. Our findings confirm that SOMF preserves safety without notably compromising performance on downstream tasks, including instruction following in Chinese, English, and Hindi, as well as problem-solving capabilities in Code and Math.