 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA safety realignment framework via subspace-oriented model fusion for large language models
Paper and Code
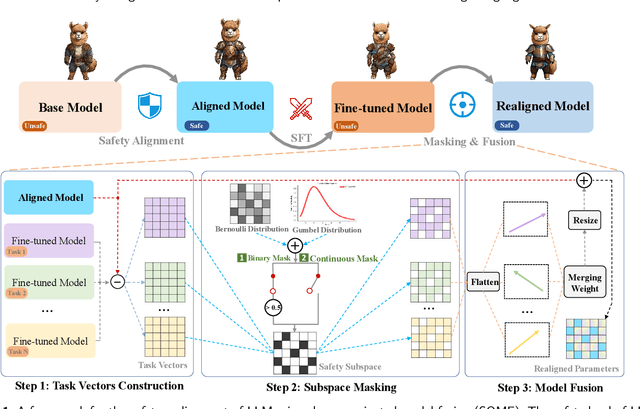
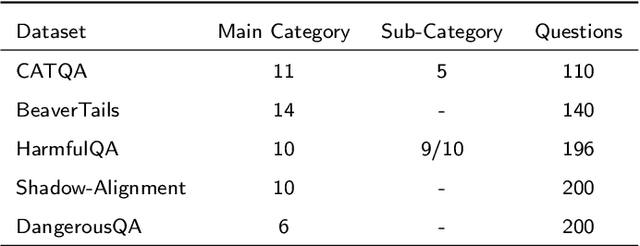
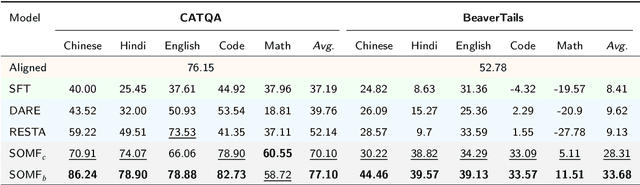
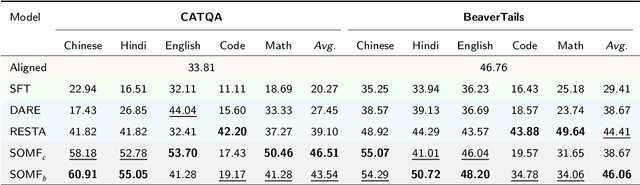
The current safeguard mechanisms for large language models (LLMs) are indeed susceptible to jailbreak attacks, making them inherently fragile. Even the process of fine-tuning on apparently benign data for downstream tasks can jeopardize safety. One potential solution is to conduct safety fine-tuning subsequent to downstream fine-tuning. However, there's a risk of catastrophic forgetting during safety fine-tuning, where LLMs may regain safety measures but lose the task-specific knowledge acquired during downstream fine-tuning. In this paper, we introduce a safety realignment framework through subspace-oriented model fusion (SOMF), aiming to combine the safeguard capabilities of initially aligned model and the current fine-tuned model into a realigned model. Our approach begins by disentangling all task vectors from the weights of each fine-tuned model. We then identify safety-related regions within these vectors by subspace masking techniques. Finally, we explore the fusion of the initial safely aligned LLM with all task vectors based on the identified safety subspace. We validate that our safety realignment framework satisfies the safety requirements of a single fine-tuned model as well as multiple models during their fusion. Our findings confirm that SOMF preserves safety without notably compromising performance on downstream tasks, including instruction following in Chinese, English, and Hindi, as well as problem-solving capabilities in Code and Math.