 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Sensing for Time-Varying Channels in ISAC Systems
Apr 21, 2025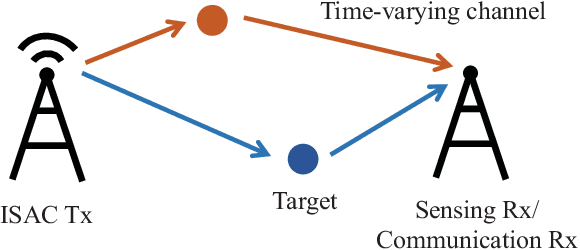
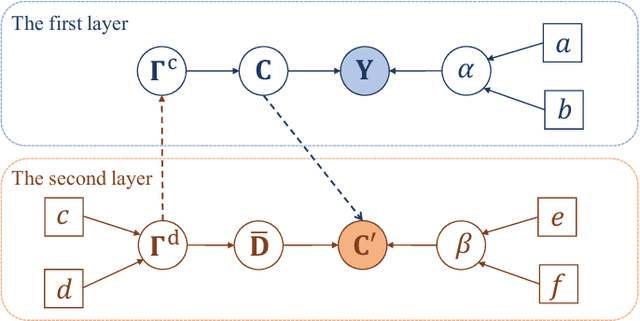
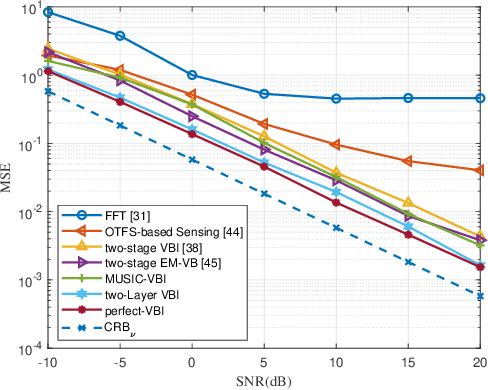
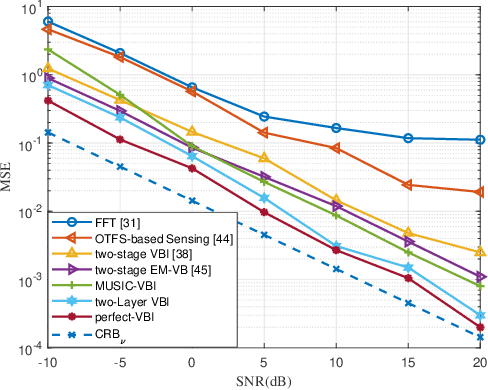
Future mobile networks are projected to support integrated sensing and communications in high-speed communication scenarios. Nevertheless, large Doppler shifts induced by time-varying channels may cause severe inter-carrier interference (ICI). Frequency domain shows the potential of reducing ISAC complexity as compared with other domains. However, parameter mismatching issue still exists for such sensing. In this paper, we develop a novel sensing scheme based on sparse Bayesian framework, where the delay and Doppler estimation problem in time-varying channels is formulated as a 3D multiple measurement-sparse signal recovery (MM-SSR) problem. We then propose a novel two-layer variational Bayesian inference (VBI) method to decompose the 3D MM-SSR problem into two layers and estimate the Doppler in the first layer and the delay in the second layer alternatively. Subsequently, as is benefited from newly unveiled signal construction, a simplified two-stage multiple signal classification (MUSIC)-based VBI method is proposed, where the delay and the Doppler are estimated by MUSIC and VBI, respectively. Additionally, the Cram\'er-Rao bound (CRB) of the considered sensing parameters is derived to characterize the lower bound for the proposed estimators. Corroborated by extensive simulation results, our proposed method can achieve improved mean square error (MSE) than its conventional counterparts and is robust against the target number and target speed, thereby validating its wide applicability and advantages over prior arts.
Multi-Carrier Faster-Than-Nyquist Signaling for OTFS Systems
Jan 12, 2025



Orthogonal time frequency space (OTFS) modulation technique is promising for high-mobility applications to achieve reliable communications. However, the capacity of OTFS systems is generally limited by the Nyquist criterion, requiring orthogonal pulses in both time and frequency domains. In this paper, we propose a novel multi-carrier faster-than-Nyquist (MC-FTN) signaling scheme for OTFS systems. By adopting non-orthogonal pulses in both time and frequency domains, our scheme significantly improves the capacity of OTFS systems. Specifically, we firstly develop the signal models for both single-input single-output (SISO) and multiple-input multiple-output (MIMO) OTFS systems. Then, we optimize the delay-Doppler (DD) domain precoding matrix at the transmitter to suppress both the inter-symbol interference (ISI) and inter-carrier interference (ICI) introduced by the MC-FTN signaling. For SISO systems, we develop an eigenvalue decomposition (EVD) precoding scheme with optimal power allocation (PA) for achieving the maximum capacity. For MIMO systems, we develop a successive interference cancellation (SIC)-based precoding scheme via decomposing the capacity maximization problem into multiple sub-capacity maximization problems with largely reduced dimensions of optimization variables. Numerical results demonstrate that our proposed MC-FTN-OTFS signaling scheme achieves significantly higher capacity than traditional Nyquist-criterion-based OTFS systems. Moreover, the SIC-based precoding scheme can effectively reduce the complexity of MIMO capacity maximization, while attaining performance close to the optimal EVD-based precoding scheme.
Towards Grouping in Large Scenes with Occlusion-aware Spatio-temporal Transformers
Oct 30, 2023Group detection, especially for large-scale scenes, has many potential applications for public safety and smart cities. Existing methods fail to cope with frequent occlusions in large-scale scenes with multiple people, and are difficult to effectively utilize spatio-temporal information. In this paper, we propose an end-to-end framework,GroupTransformer, for group detection in large-scale scenes. To deal with the frequent occlusions caused by multiple people, we design an occlusion encoder to detect and suppress severely occluded person crops. To explore the potential spatio-temporal relationship, we propose spatio-temporal transformers to simultaneously extract trajectory information and fuse inter-person features in a hierarchical manner. Experimental results on both large-scale and small-scale scenes demonstrate that our method achieves better performance compared with state-of-the-art methods. On large-scale scenes, our method significantly boosts the performance in terms of precision and F1 score by more than 10%. On small-scale scenes, our method still improves the performance of F1 score by more than 5%. The project page with code can be found at http://cic.tju.edu.cn/faculty/likun/projects/GroupTrans.
* 11 pages, 5 figures
Modeling the Trade-off of Privacy Preservation and Activity Recognition on Low-Resolution Images
Mar 18, 2023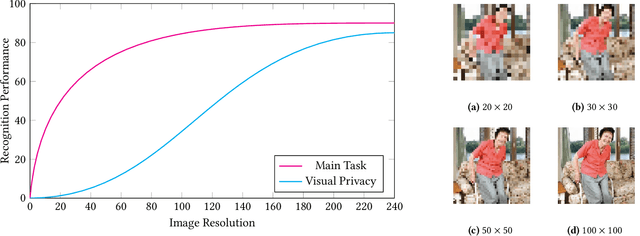
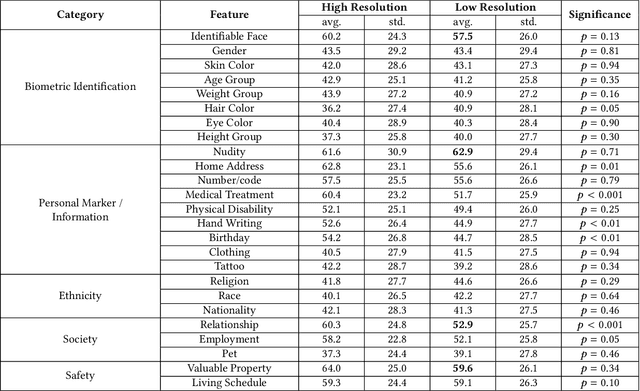
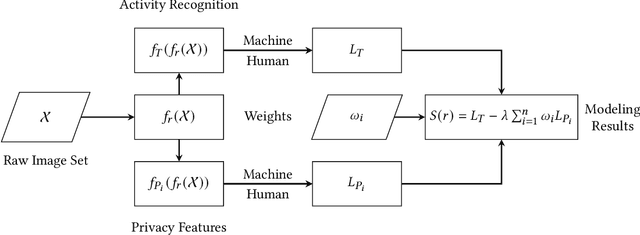
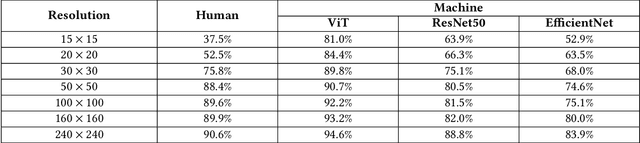
A computer vision system using low-resolution image sensors can provide intelligent services (e.g., activity recognition) but preserve unnecessary visual privacy information from the hardware level. However, preserving visual privacy and enabling accurate machine recognition have adversarial needs on image resolution. Modeling the trade-off of privacy preservation and machine recognition performance can guide future privacy-preserving computer vision systems using low-resolution image sensors. In this paper, using the at-home activity of daily livings (ADLs) as the scenario, we first obtained the most important visual privacy features through a user survey. Then we quantified and analyzed the effects of image resolution on human and machine recognition performance in activity recognition and privacy awareness tasks. We also investigated how modern image super-resolution techniques influence these effects. Based on the results, we proposed a method for modeling the trade-off of privacy preservation and activity recognition on low-resolution images.
PANDA: A Gigapixel-level Human-centric Video Dataset
Mar 10, 2020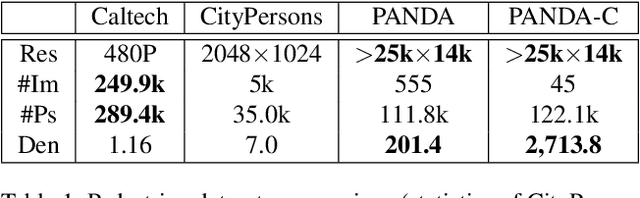

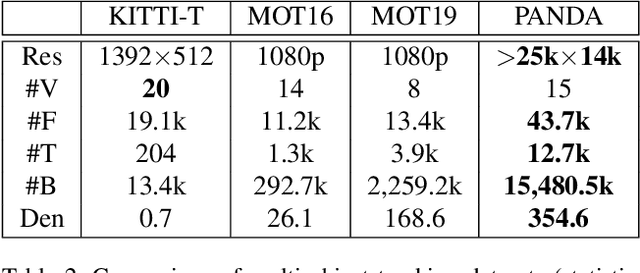
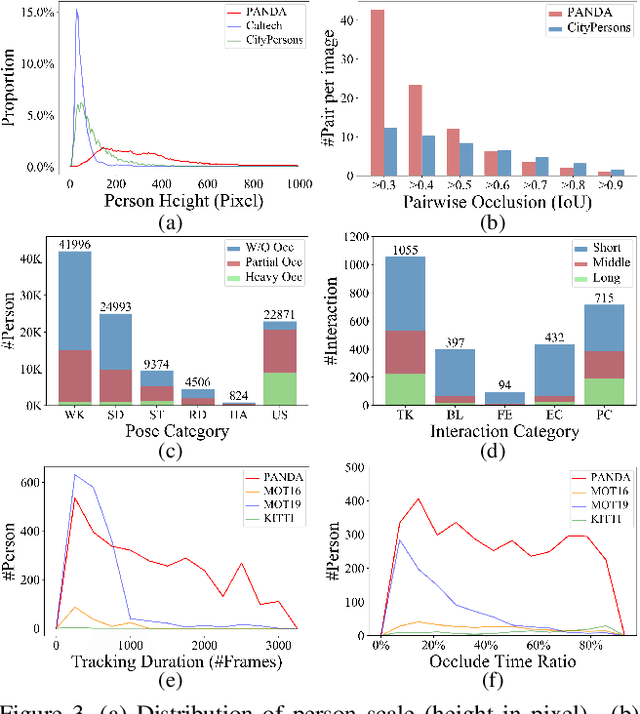
We present PANDA, the first gigaPixel-level humAN-centric viDeo dAtaset, for large-scale, long-term, and multi-object visual analysis. The videos in PANDA were captured by a gigapixel camera and cover real-world scenes with both wide field-of-view (~1 square kilometer area) and high-resolution details (~gigapixel-level/frame). The scenes may contain 4k head counts with over 100x scale variation. PANDA provides enriched and hierarchical ground-truth annotations, including 15,974.6k bounding boxes, 111.8k fine-grained attribute labels, 12.7k trajectories, 2.2k groups and 2.9k interactions. We benchmark the human detection and tracking tasks. Due to the vast variance of pedestrian pose, scale, occlusion and trajectory, existing approaches are challenged by both accuracy and efficiency. Given the uniqueness of PANDA with both wide FoV and high resolution, a new task of interaction-aware group detection is introduced. We design a 'global-to-local zoom-in' framework, where global trajectories and local interactions are simultaneously encoded, yielding promising results. We believe PANDA will contribute to the community of artificial intelligence and praxeology by understanding human behaviors and interactions in large-scale real-world scenes. PANDA Website: http://www.panda-dataset.com.