 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiSync: Spatio-Temporally Aligning Hand Motion from Wearable IMU and On-Robot Camera for Command Source Identification in Long-Range HRI
Mar 12, 2026Long-range Human-Robot Interaction (HRI) remains underexplored. Within it, Command Source Identification (CSI) - determining who issued a command - is especially challenging due to multi-user and distance-induced sensor ambiguity. We introduce HiSync, an optical-inertial fusion framework that treats hand motion as binding cues by aligning robot-mounted camera optical flow with hand-worn IMU signals. We first elicit a user-defined (N=12) gesture set and collect a multimodal command gesture dataset (N=38) in long-range multi-user HRI scenarios. Next, HiSync extracts frequency-domain hand motion features from both camera and IMU data, and a learned CSINet denoises IMU readings, temporally aligns modalities, and performs distance-aware multi-window fusion to compute cross-modal similarity of subtle, natural gestures, enabling robust CSI. In three-person scenes up to 34m, HiSync achieves 92.32% CSI accuracy, outperforming the prior SOTA by 48.44%. HiSync is also validated on real-robot deployment. By making CSI reliable and natural, HiSync provides a practical primitive and design guidance for public-space HRI.
Multivariate Diffusion Transformer with Decoupled Attention for High-Fidelity Mask-Text Collaborative Facial Generation
Nov 16, 2025While significant progress has been achieved in multimodal facial generation using semantic masks and textual descriptions, conventional feature fusion approaches often fail to enable effective cross-modal interactions, thereby leading to suboptimal generation outcomes. To address this challenge, we introduce MDiTFace--a customized diffusion transformer framework that employs a unified tokenization strategy to process semantic mask and text inputs, eliminating discrepancies between heterogeneous modality representations. The framework facilitates comprehensive multimodal feature interaction through stacked, newly designed multivariate transformer blocks that process all conditions synchronously. Additionally, we design a novel decoupled attention mechanism by dissociating implicit dependencies between mask tokens and temporal embeddings. This mechanism segregates internal computations into dynamic and static pathways, enabling caching and reuse of features computed in static pathways after initial calculation, thereby reducing additional computational overhead introduced by mask condition by over 94% while maintaining performance. Extensive experiments demonstrate that MDiTFace significantly outperforms other competing methods in terms of both facial fidelity and conditional consistency.
TaskSense: Cognitive Chain Modeling and Difficulty Estimation for GUI Tasks
Nov 12, 2025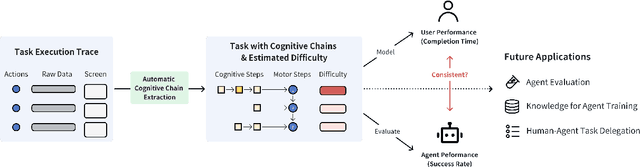
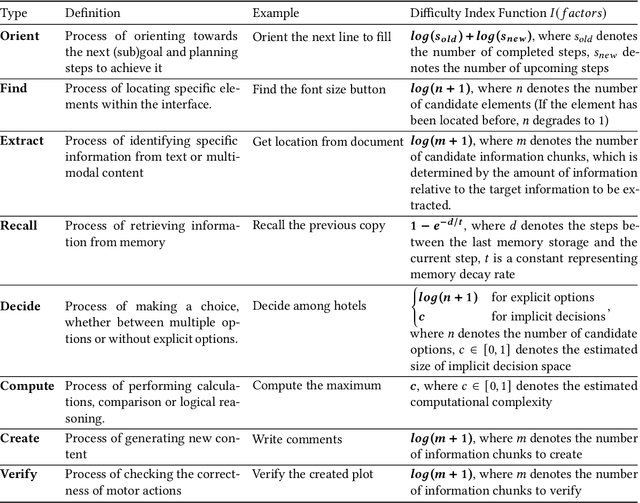
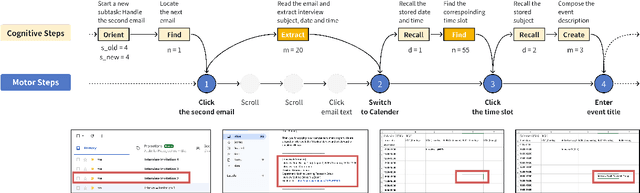

Measuring GUI task difficulty is crucial for user behavior analysis and agent capability evaluation. Yet, existing benchmarks typically quantify difficulty based on motor actions (e.g., step counts), overlooking the cognitive demands underlying task completion. In this work, we propose Cognitive Chain, a novel framework that models task difficulty from a cognitive perspective. A cognitive chain decomposes the cognitive processes preceding a motor action into a sequence of cognitive steps (e.g., finding, deciding, computing), each with a difficulty index grounded in information theories. We develop an LLM-based method to automatically extract cognitive chains from task execution traces. Validation with linear regression shows that our estimated cognitive difficulty correlates well with user completion time (step-level R-square=0.46 after annotation). Assessment of state-of-the-art GUI agents shows reduced success on cognitively demanding tasks, revealing capability gaps and Human-AI consistency patterns. We conclude by discussing potential applications in agent training, capability assessment, and human-agent delegation optimization.
TextOnly: A Unified Function Portal for Text-Related Functions on Smartphones
Aug 23, 2025Text boxes serve as portals to diverse functionalities in today's smartphone applications. However, when it comes to specific functionalities, users always need to navigate through multiple steps to access particular text boxes for input. We propose TextOnly, a unified function portal that enables users to access text-related functions from various applications by simply inputting text into a sole text box. For instance, entering a restaurant name could trigger a Google Maps search, while a greeting could initiate a conversation in WhatsApp. Despite their brevity, TextOnly maximizes the utilization of these raw text inputs, which contain rich information, to interpret user intentions effectively. TextOnly integrates large language models(LLM) and a BERT model. The LLM consistently provides general knowledge, while the BERT model can continuously learn user-specific preferences and enable quicker predictions. Real-world user studies demonstrated TextOnly's effectiveness with a top-1 accuracy of 71.35%, and its ability to continuously improve both its accuracy and inference speed. Participants perceived TextOnly as having satisfactory usability and expressed a preference for TextOnly over manual executions. Compared with voice assistants, TextOnly supports a greater range of text-related functions and allows for more concise inputs.
MOAT: Evaluating LMMs for Capability Integration and Instruction Grounding
Mar 12, 2025Large multimodal models (LMMs) have demonstrated significant potential as generalists in vision-language (VL) tasks. However, there remains a significant gap between state-of-the-art LMMs and human performance when it comes to complex tasks that require a combination of fundamental VL capabilities, as well as tasks involving the grounding of complex instructions. To thoroughly investigate the human-LMM gap and its underlying causes, we propose MOAT, a diverse benchmark with complex real-world VL tasks that are challenging for LMMs. Specifically, the tasks in MOAT require LMMs to engage in generalist problem solving by integrating fundamental VL capabilities such as reading text, counting, understanding spatial relations, grounding textual and visual instructions, etc. All these abilities fit into a taxonomy proposed by us that contains 10 fundamental VL capabilities, enabling MOAT to provide a fine-grained view of LMMs' strengths and weaknesses. Besides, MOAT is the first benchmark to explicitly evaluate LMMs' ability to ground complex text and visual instructions, which is essential to many real-world applications. We evaluate over 20 proprietary and open source LMMs, as well as humans, on MOAT, and found that humans achieved 82.7% accuracy while the best performing LMM (OpenAI o1) achieved only 38.8%. To guide future model development, we analyze common trends in our results and discuss the underlying causes of observed performance gaps between LMMs and humans, focusing on which VL capability forms the bottleneck in complex tasks, whether test time scaling improves performance on MOAT, and how tiling harms LMMs' capability to count. Code and data are available at https://cambrian-yzt.github.io/MOAT.
PoseAugment: Generative Human Pose Data Augmentation with Physical Plausibility for IMU-based Motion Capture
Sep 21, 2024The data scarcity problem is a crucial factor that hampers the model performance of IMU-based human motion capture. However, effective data augmentation for IMU-based motion capture is challenging, since it has to capture the physical relations and constraints of the human body, while maintaining the data distribution and quality. We propose PoseAugment, a novel pipeline incorporating VAE-based pose generation and physical optimization. Given a pose sequence, the VAE module generates infinite poses with both high fidelity and diversity, while keeping the data distribution. The physical module optimizes poses to satisfy physical constraints with minimal motion restrictions. High-quality IMU data are then synthesized from the augmented poses for training motion capture models. Experiments show that PoseAugment outperforms previous data augmentation and pose generation methods in terms of motion capture accuracy, revealing a strong potential of our method to alleviate the data collection burden for IMU-based motion capture and related tasks driven by human poses.
G-VOILA: Gaze-Facilitated Information Querying in Daily Scenarios
May 13, 2024Modern information querying systems are progressively incorporating multimodal inputs like vision and audio. However, the integration of gaze -- a modality deeply linked to user intent and increasingly accessible via gaze-tracking wearables -- remains underexplored. This paper introduces a novel gaze-facilitated information querying paradigm, named G-VOILA, which synergizes users' gaze, visual field, and voice-based natural language queries to facilitate a more intuitive querying process. In a user-enactment study involving 21 participants in 3 daily scenarios (p = 21, scene = 3), we revealed the ambiguity in users' query language and a gaze-voice coordination pattern in users' natural query behaviors with G-VOILA. Based on the quantitative and qualitative findings, we developed a design framework for the G-VOILA paradigm, which effectively integrates the gaze data with the in-situ querying context. Then we implemented a G-VOILA proof-of-concept using cutting-edge deep learning techniques. A follow-up user study (p = 16, scene = 2) demonstrates its effectiveness by achieving both higher objective score and subjective score, compared to a baseline without gaze data. We further conducted interviews and provided insights for future gaze-facilitated information querying systems.
GestureGPT: Zero-shot Interactive Gesture Understanding and Grounding with Large Language Model Agents
Oct 30, 2023



Current gesture recognition systems primarily focus on identifying gestures within a predefined set, leaving a gap in connecting these gestures to interactive GUI elements or system functions (e.g., linking a 'thumb-up' gesture to a 'like' button). We introduce GestureGPT, a novel zero-shot gesture understanding and grounding framework leveraging large language models (LLMs). Gesture descriptions are formulated based on hand landmark coordinates from gesture videos and fed into our dual-agent dialogue system. A gesture agent deciphers these descriptions and queries about the interaction context (e.g., interface, history, gaze data), which a context agent organizes and provides. Following iterative exchanges, the gesture agent discerns user intent, grounding it to an interactive function. We validated the gesture description module using public first-view and third-view gesture datasets and tested the whole system in two real-world settings: video streaming and smart home IoT control. The highest zero-shot Top-5 grounding accuracies are 80.11% for video streaming and 90.78% for smart home tasks, showing potential of the new gesture understanding paradigm.
MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Intervention
Sep 28, 2023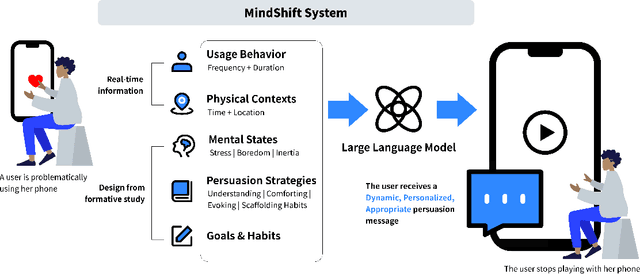

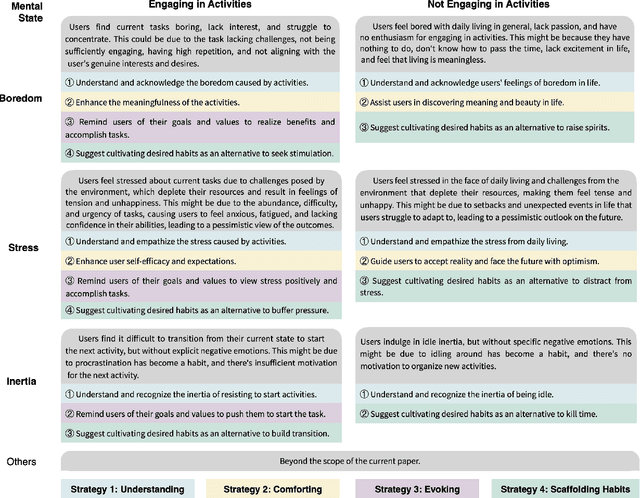
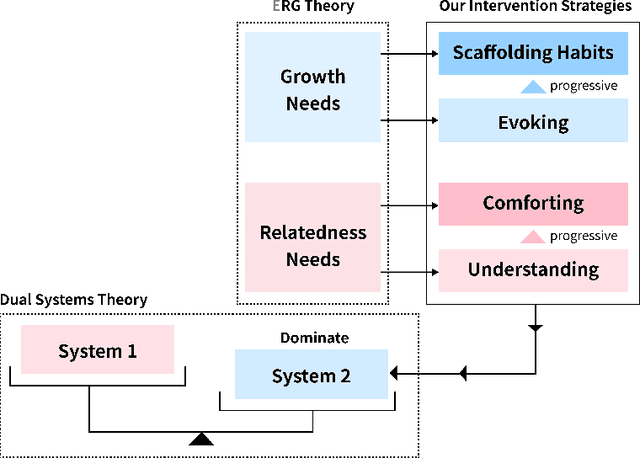
Problematic smartphone use negatively affects physical and mental health. Despite the wide range of prior research, existing persuasive techniques are not flexible enough to provide dynamic persuasion content based on users' physical contexts and mental states. We first conduct a Wizard-of-Oz study (N=12) and an interview study (N=10) to summarize the mental states behind problematic smartphone use: boredom, stress, and inertia. This informs our design of four persuasion strategies: understanding, comforting, evoking, and scaffolding habits. We leverage large language models (LLMs) to enable the automatic and dynamic generation of effective persuasion content. We develop MindShift, a novel LLM-powered problematic smartphone use intervention technique. MindShift takes users' in-the-moment physical contexts, mental states, app usage behaviors, users' goals & habits as input, and generates high-quality and flexible persuasive content with appropriate persuasion strategies. We conduct a 5-week field experiment (N=25) to compare MindShift with baseline techniques. The results show that MindShift significantly improves intervention acceptance rates by 17.8-22.5% and reduces smartphone use frequency by 12.1-14.4%. Moreover, users have a significant drop in smartphone addiction scale scores and a rise in self-efficacy. Our study sheds light on the potential of leveraging LLMs for context-aware persuasion in other behavior change domains.
Modeling the Trade-off of Privacy Preservation and Activity Recognition on Low-Resolution Images
Mar 18, 2023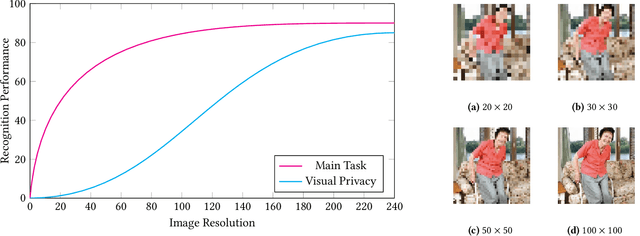
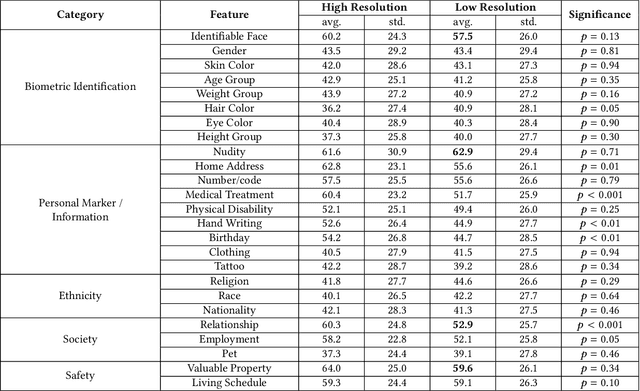
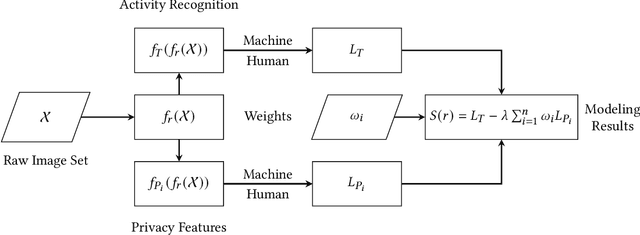
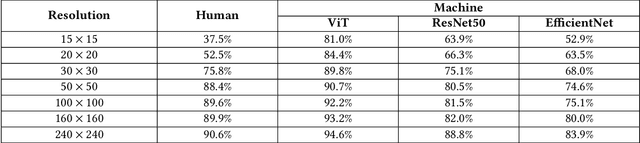
A computer vision system using low-resolution image sensors can provide intelligent services (e.g., activity recognition) but preserve unnecessary visual privacy information from the hardware level. However, preserving visual privacy and enabling accurate machine recognition have adversarial needs on image resolution. Modeling the trade-off of privacy preservation and machine recognition performance can guide future privacy-preserving computer vision systems using low-resolution image sensors. In this paper, using the at-home activity of daily livings (ADLs) as the scenario, we first obtained the most important visual privacy features through a user survey. Then we quantified and analyzed the effects of image resolution on human and machine recognition performance in activity recognition and privacy awareness tasks. We also investigated how modern image super-resolution techniques influence these effects. Based on the results, we proposed a method for modeling the trade-off of privacy preservation and activity recognition on low-resolution images.