 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Stack Scanning can Improve AI Detection of Mitosis: A Case Study of Meningiomas
Jan 27, 2025



Z-stack scanning is an emerging whole slide imaging technology that captures multiple focal planes alongside the z-axis of a glass slide. Because z-stacking can offer enhanced depth information compared to the single-layer whole slide imaging, this technology can be particularly useful in analyzing small-scaled histopathological patterns. However, its actual clinical impact remains debated with mixed results. To clarify this, we investigate the effect of z-stack scanning on artificial intelligence (AI) mitosis detection of meningiomas. With the same set of 22 Hematoxylin and Eosin meningioma glass slides scanned by three different digital pathology scanners, we tested the performance of three AI pipelines on both single-layer and z-stacked whole slide images (WSIs). Results showed that in all scanner-AI combinations, z-stacked WSIs significantly increased AI's sensitivity (+17.14%) on the mitosis detection with only a marginal impact on precision. Our findings provide quantitative evidence that highlights z-stack scanning as a promising technique for AI mitosis detection, paving the way for more reliable AI-assisted pathology workflows, which can ultimately benefit patient management.
Traffic Scenario Logic: A Spatial-Temporal Logic for Modeling and Reasoning of Urban Traffic Scenarios
May 22, 2024



Formal representations of traffic scenarios can be used to generate test cases for the safety verification of autonomous driving. However, most existing methods are limited in highway or highly simplified intersection scenarios due to the intricacy and diversity of traffic scenarios. In response, we propose Traffic Scenario Logic (TSL), which is a spatial-temporal logic designed for modeling and reasoning of urban pedestrian-free traffic scenarios. TSL provides a formal representation of the urban road network that can be derived from OpenDRIVE, i.e., the de facto industry standard of high-definition maps for autonomous driving, enabling the representation of a broad range of traffic scenarios. We implemented the reasoning of TSL using Telingo, i.e., a solver for temporal programs based on the Answer Set Programming, and tested it on different urban road layouts. Demonstrations show the effectiveness of TSL in test scenario generation and its potential value in areas like decision-making and control verification of autonomous driving.
Safe and Personalizable Logical Guidance for Trajectory Planning of Autonomous Driving
May 22, 2024



Autonomous vehicles necessitate a delicate balance between safety, efficiency, and user preferences in trajectory planning. Existing traditional or learning-based methods face challenges in adequately addressing all these aspects. In response, this paper proposes a novel component termed the Logical Guidance Layer (LGL), designed for seamless integration into autonomous driving trajectory planning frameworks, specifically tailored for highway scenarios. The LGL guides the trajectory planning with a local target area determined through scenario reasoning, scenario evaluation, and guidance area calculation. Integrating the Responsibility-Sensitive Safety (RSS) model, the LGL ensures formal safety guarantees while accommodating various user preferences defined by logical formulae. Experimental validation demonstrates the effectiveness of the LGL in achieving a balance between safety and efficiency, and meeting user preferences in autonomous highway driving scenarios.
Revamp: Enhancing Accessible Information Seeking Experience of Online Shopping for Blind or Low Vision Users
Feb 01, 2021
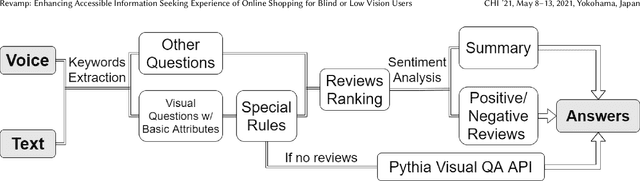

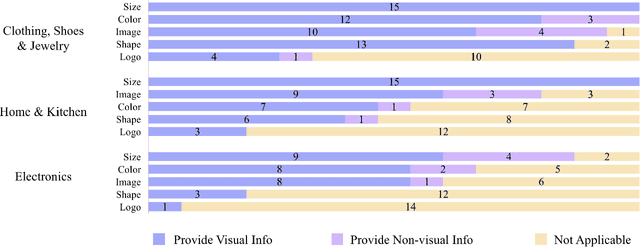
Online shopping has become a valuable modern convenience, but blind or low vision (BLV) users still face significant challenges using it, because of: 1) inadequate image descriptions and 2) the inability to filter large amounts of information using screen readers. To address those challenges, we propose Revamp, a system that leverages customer reviews for interactive information retrieval. Revamp is a browser integration that supports review-based question-answering interactions on a reconstructed product page. From our interview, we identified four main aspects (color, logo, shape, and size) that are vital for BLV users to understand the visual appearance of a product. Based on the findings, we formulated syntactic rules to extract review snippets, which were used to generate image descriptions and responses to users' queries. Evaluations with eight BLV users showed that Revamp 1) provided useful descriptive information for understanding product appearance and 2) helped the participants locate key information efficiently.
NEARL: Non-Explicit Action Reinforcement Learning for Robotic Control
Nov 02, 2020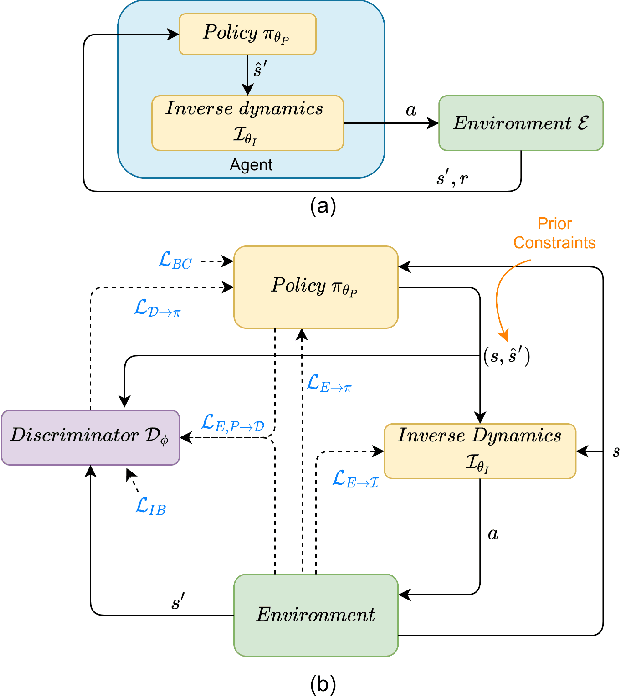
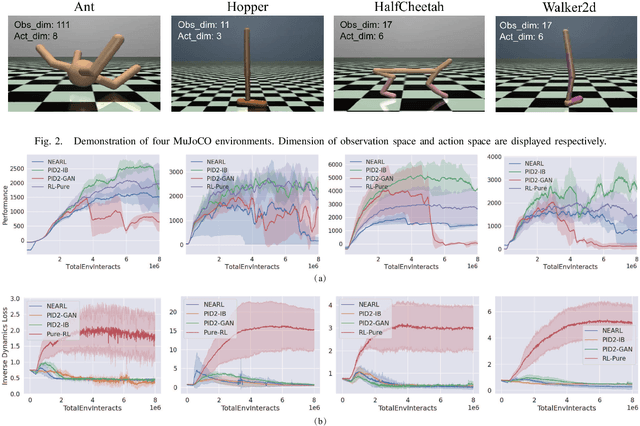
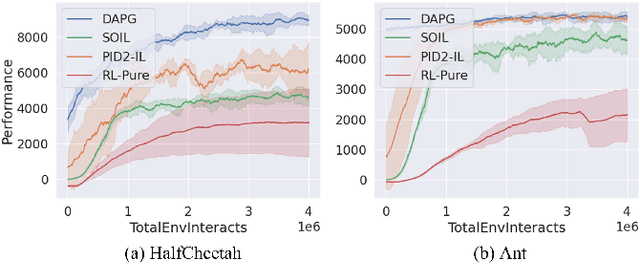
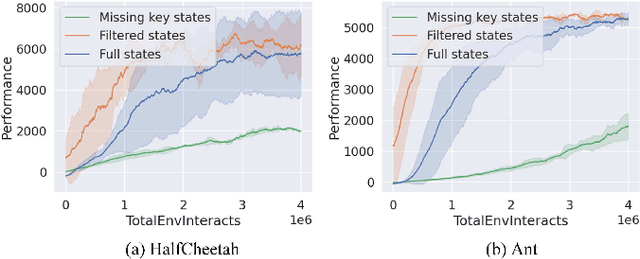
Traditionally, reinforcement learning methods predict the next action based on the current state. However, in many situations, directly applying actions to control systems or robots is dangerous and may lead to unexpected behaviors because action is rather low-level. In this paper, we propose a novel hierarchical reinforcement learning framework without explicit action. Our meta policy tries to manipulate the next optimal state and actual action is produced by the inverse dynamics model. To stabilize the training process, we integrate adversarial learning and information bottleneck into our framework. Under our framework, widely available state-only demonstrations can be exploited effectively for imitation learning. Also, prior knowledge and constraints can be applied to meta policy. We test our algorithm in simulation tasks and its combination with imitation learning. The experimental results show the reliability and robustness of our algorithms.
Generating Adjacency Matrix for Video-Query based Video Moment Retrieval
Aug 19, 2020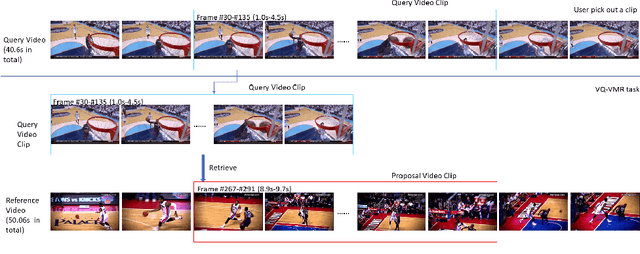
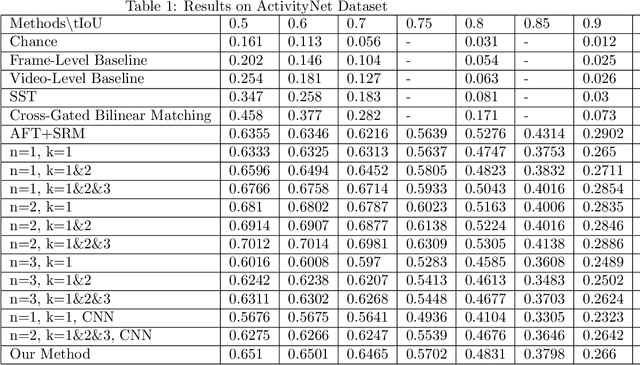

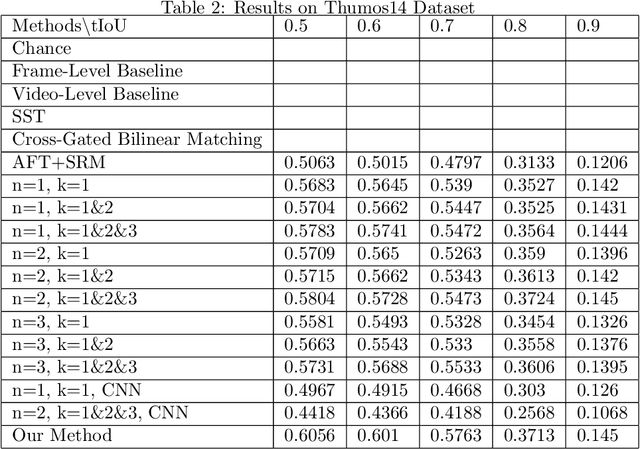
In this paper, we continue our work on Video-Query based Video Moment retrieval task. Based on using graph convolution to extract intra-video and inter-video frame features, we improve the method by using similarity-metric based graph convolution, whose weighted adjacency matrix is achieved by calculating similarity metric between features of any two different timesteps in the graph. Experiments on ActivityNet v1.2 and Thumos14 dataset shows the effectiveness of this improvement, and it outperforms the state-of-the-art methods.
Graph Neural Network for Video-Query based Video Moment Retrieval
Jul 20, 2020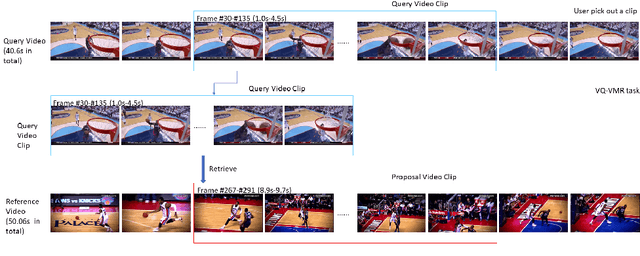
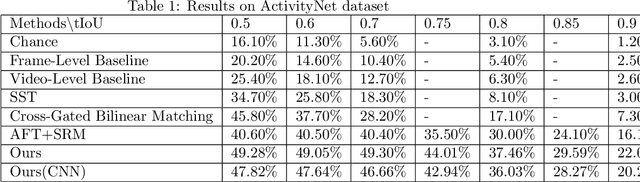
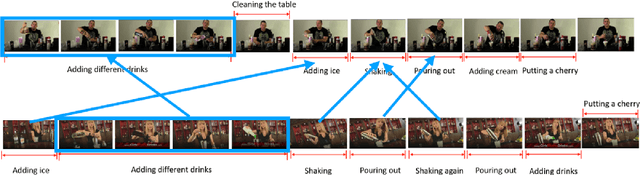
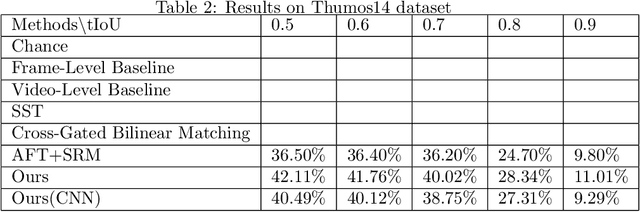
In this paper, we focus on Video Query based Video Moment Retrieval (VQ-VMR) task, which uses a query video clip as input to retrieve a semantic relative video clip in another untrimmed long video. we find that in VQ-VMR datasets, there exists a phenomenon showing that there does not exist consistent relationship between feature similarity by frame and feature similarity by video, which affects the feature fusion among frames. However, existing VQ-VMR methods do not fully consider it. Taking this phenomenon into account, in this article, we treat video features as a graph by concatenating the query video feature and proposal video feature along time dimension, where each timestep is treated as a node, each row of the feature matrix is treated as feature of each node. Then, with the power of graph neural networks, we propose a Multi-Graph Feature Fusion Module to fuse the relation feature of this graph. After evaluating our method on ActivityNet v1.2 dataset and Thumos14 dataset, we find that our proposed method outperforms the state of art methods.