 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Ensemble Forecasts of Abnormally Deflecting Tropical Cyclones with Fused Atmosphere-Ocean-Terrain Data
Apr 02, 2026Deep learning-based tropical cyclone (TC) forecasting methods have demonstrated significant potential and application advantages, as they feature much lower computational cost and faster operation speed than numerical weather prediction models. However, existing deep learning methods still have key limitations: they can only process a single type of sequential trajectory data or homogeneous meteorological variables, and fail to achieve accurate forecasting of abnormal deflected TCs. To address these challenges, we present two groundbreaking contributions. First, we have constructed a multimodal and multi-source dataset named AOT-TCs for TC forecasting in the Northwest Pacific basin. As the first dataset of its kind, it innovatively integrates heterogeneous variables from the atmosphere, ocean, and land, thus obtaining a comprehensive and information-rich meteorological dataset. Second, based on the AOT-TCs dataset, we propose a forecasting model that can handle both normal and abnormally deflected TCs. This is the first TC forecasting model to adopt an explicit atmosphere-ocean-terrain coupling architecture, enabling it to effectively capture complex interactions across physical domains. Extensive experiments on all TC cases in the Northwest Pacific from 2017 to 2024 show that our model achieves state-of-the-art performance in TC forecasting: it not only significantly improves the forecasting accuracy of normal TCs but also breaks through the technical bottleneck in forecasting abnormally deflected TCs.
Full-attention based Neural Architecture Search using Context Auto-regression
Nov 13, 2021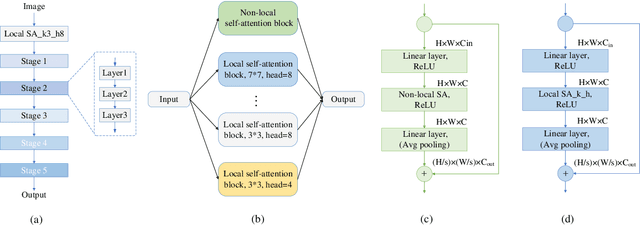
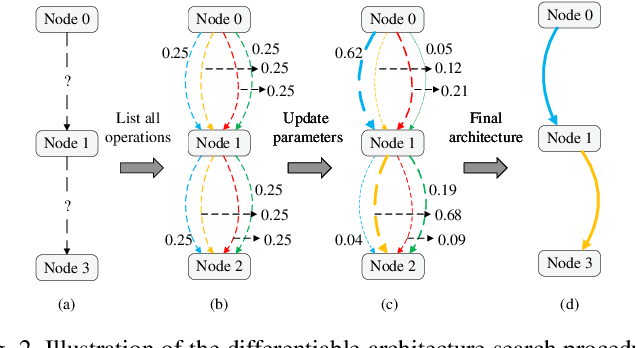

Self-attention architectures have emerged as a recent advancement for improving the performance of vision tasks. Manual determination of the architecture for self-attention networks relies on the experience of experts and cannot automatically adapt to various scenarios. Meanwhile, neural architecture search (NAS) has significantly advanced the automatic design of neural architectures. Thus, it is appropriate to consider using NAS methods to discover a better self-attention architecture automatically. However, it is challenging to directly use existing NAS methods to search attention networks because of the uniform cell-based search space and the lack of long-term content dependencies. To address this issue, we propose a full-attention based NAS method. More specifically, a stage-wise search space is constructed that allows various attention operations to be adopted for different layers of a network. To extract global features, a self-supervised search algorithm is proposed that uses context auto-regression to discover the full-attention architecture. To verify the efficacy of the proposed methods, we conducted extensive experiments on various learning tasks, including image classification, fine-grained image recognition, and zero-shot image retrieval. The empirical results show strong evidence that our method is capable of discovering high-performance, full-attention architectures while guaranteeing the required search efficiency.
Generating Adjacency Matrix for Video-Query based Video Moment Retrieval
Aug 19, 2020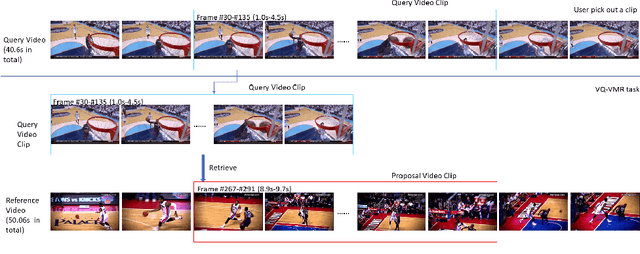
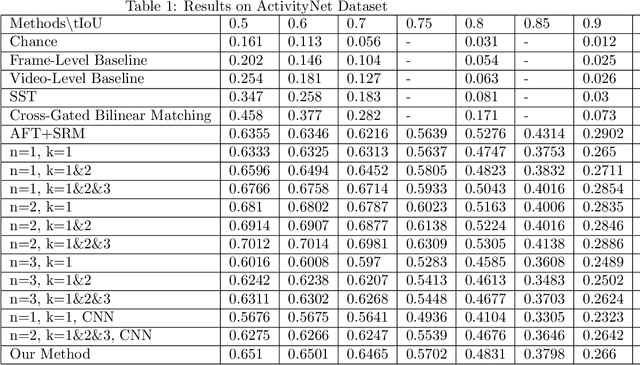

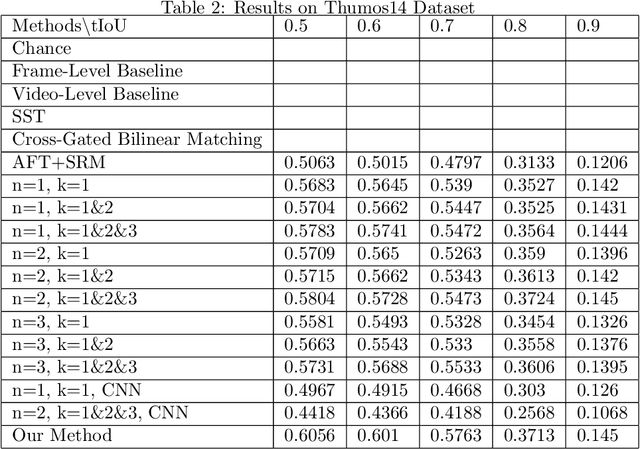
In this paper, we continue our work on Video-Query based Video Moment retrieval task. Based on using graph convolution to extract intra-video and inter-video frame features, we improve the method by using similarity-metric based graph convolution, whose weighted adjacency matrix is achieved by calculating similarity metric between features of any two different timesteps in the graph. Experiments on ActivityNet v1.2 and Thumos14 dataset shows the effectiveness of this improvement, and it outperforms the state-of-the-art methods.
Graph Neural Network for Video-Query based Video Moment Retrieval
Jul 20, 2020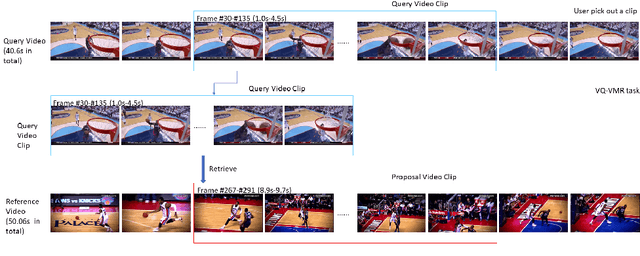
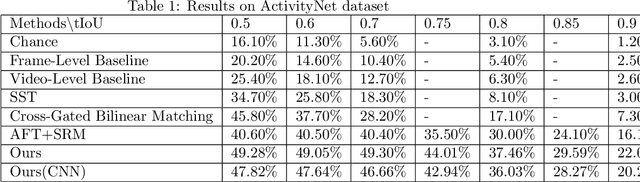
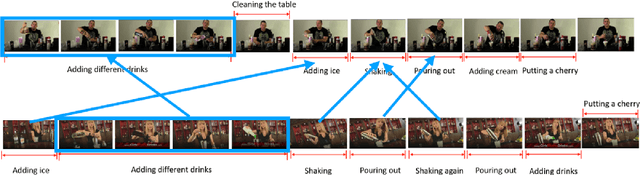
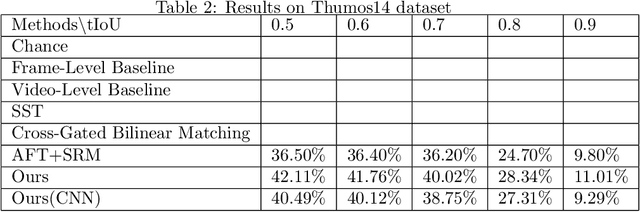
In this paper, we focus on Video Query based Video Moment Retrieval (VQ-VMR) task, which uses a query video clip as input to retrieve a semantic relative video clip in another untrimmed long video. we find that in VQ-VMR datasets, there exists a phenomenon showing that there does not exist consistent relationship between feature similarity by frame and feature similarity by video, which affects the feature fusion among frames. However, existing VQ-VMR methods do not fully consider it. Taking this phenomenon into account, in this article, we treat video features as a graph by concatenating the query video feature and proposal video feature along time dimension, where each timestep is treated as a node, each row of the feature matrix is treated as feature of each node. Then, with the power of graph neural networks, we propose a Multi-Graph Feature Fusion Module to fuse the relation feature of this graph. After evaluating our method on ActivityNet v1.2 dataset and Thumos14 dataset, we find that our proposed method outperforms the state of art methods.
Soft-Root-Sign Activation Function
Mar 01, 2020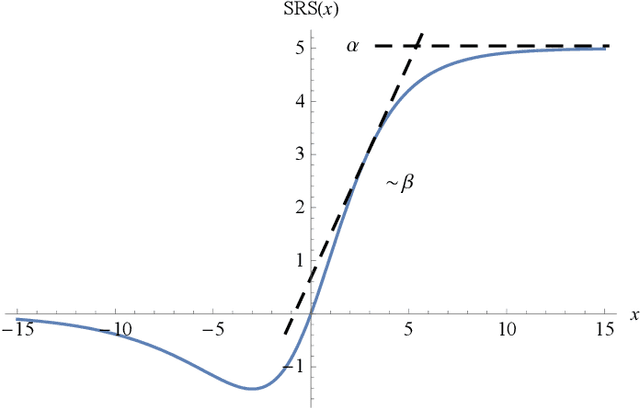
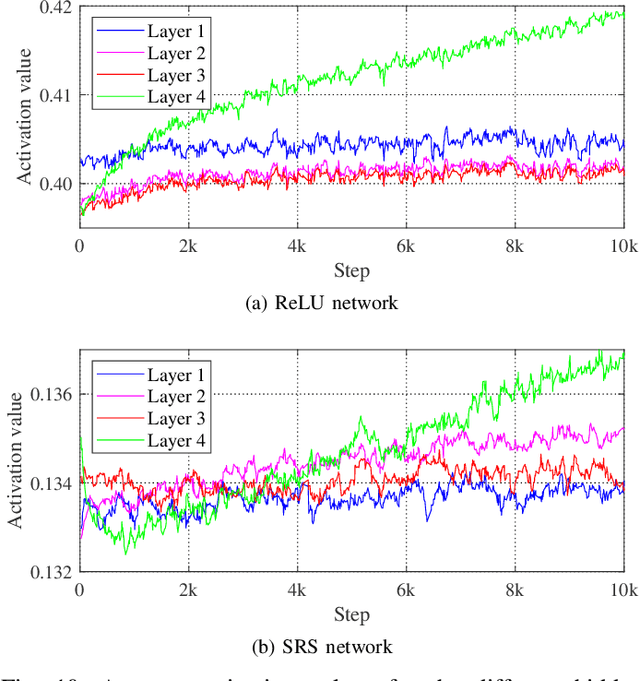
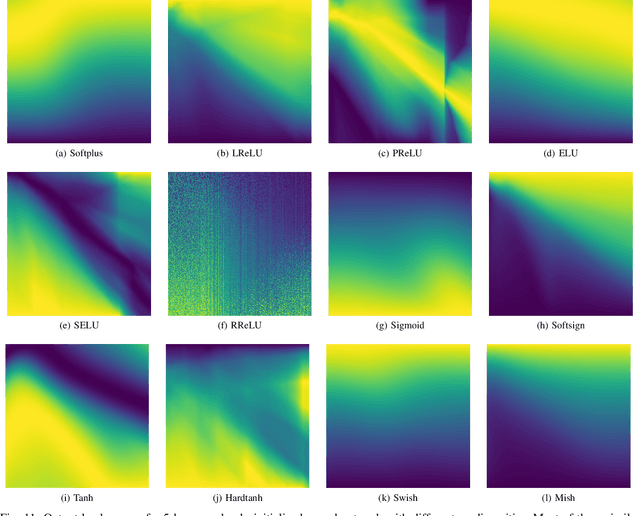
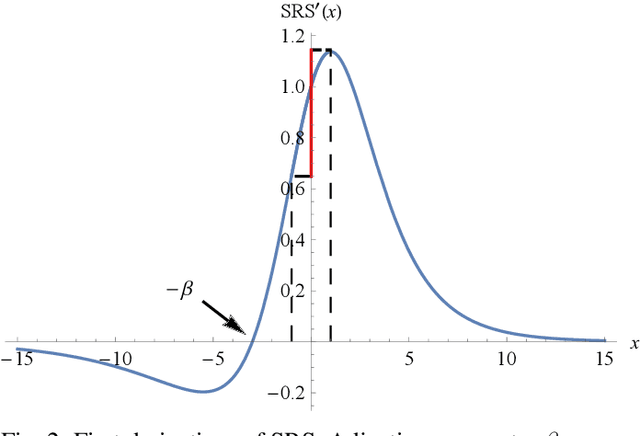
The choice of activation function in deep networks has a significant effect on the training dynamics and task performance. At present, the most effective and widely-used activation function is ReLU. However, because of the non-zero mean, negative missing and unbounded output, ReLU is at a potential disadvantage during optimization. To this end, we introduce a novel activation function to manage to overcome the above three challenges. The proposed nonlinearity, namely "Soft-Root-Sign" (SRS), is smooth, non-monotonic, and bounded. Notably, the bounded property of SRS distinguishes itself from most state-of-the-art activation functions. In contrast to ReLU, SRS can adaptively adjust the output by a pair of independent trainable parameters to capture negative information and provide zero-mean property, which leading not only to better generalization performance, but also to faster learning speed. It also avoids and rectifies the output distribution to be scattered in the non-negative real number space, making it more compatible with batch normalization (BN) and less sensitive to initialization. In experiments, we evaluated SRS on deep networks applied to a variety of tasks, including image classification, machine translation and generative modelling. Our SRS matches or exceeds models with ReLU and other state-of-the-art nonlinearities, showing that the proposed activation function is generalized and can achieve high performance across tasks. Ablation study further verified the compatibility with BN and self-adaptability for different initialization.
Comb Convolution for Efficient Convolutional Architecture
Nov 01, 2019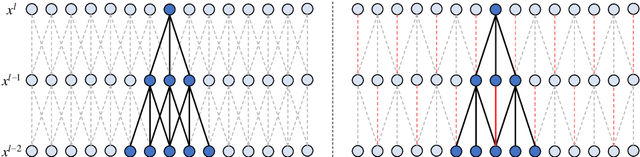
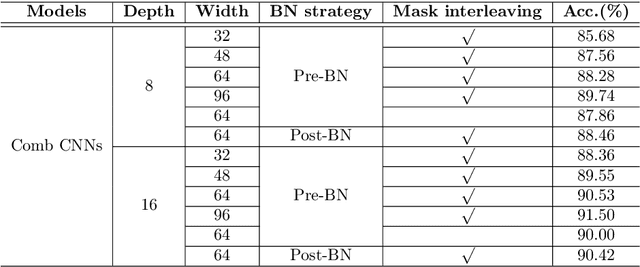
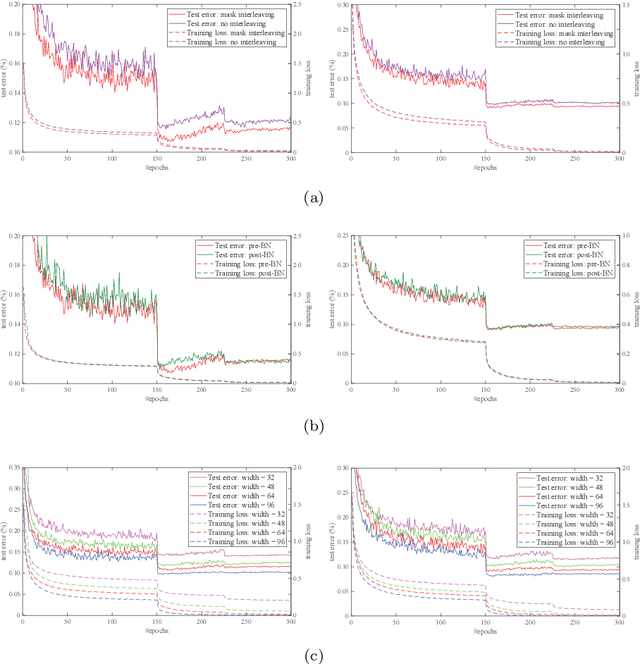
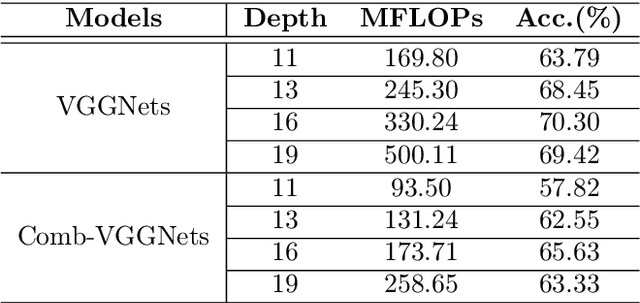
Convolutional neural networks (CNNs) are inherently suffering from massively redundant computation (FLOPs) due to the dense connection pattern between feature maps and convolution kernels. Recent research has investigated the sparse relationship between channels, however, they ignored the spatial relationship within a channel. In this paper, we present a novel convolutional operator, namely comb convolution, to exploit the intra-channel sparse relationship among neurons. The proposed convolutional operator eliminates nearly 50% of connections by inserting uniform mappings into standard convolutions and removing about half of spatial connections in convolutional layer. Notably, our work is orthogonal and complementary to existing methods that reduce channel-wise redundancy. Thus, it has great potential to further increase efficiency through integrating the comb convolution to existing architectures. Experimental results demonstrate that by simply replacing standard convolutions with comb convolutions on state-of-the-art CNN architectures (e.g., VGGNets, Xception and SE-Net), we can achieve 50% FLOPs reduction while still maintaining the accuracy.