 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalist Intelligence in Dentistry: Vision Foundation Models for Oral and Maxillofacial Radiology
Oct 16, 2025Oral and maxillofacial radiology plays a vital role in dental healthcare, but radiographic image interpretation is limited by a shortage of trained professionals. While AI approaches have shown promise, existing dental AI systems are restricted by their single-modality focus, task-specific design, and reliance on costly labeled data, hindering their generalization across diverse clinical scenarios. To address these challenges, we introduce DentVFM, the first family of vision foundation models (VFMs) designed for dentistry. DentVFM generates task-agnostic visual representations for a wide range of dental applications and uses self-supervised learning on DentVista, a large curated dental imaging dataset with approximately 1.6 million multi-modal radiographic images from various medical centers. DentVFM includes 2D and 3D variants based on the Vision Transformer (ViT) architecture. To address gaps in dental intelligence assessment and benchmarks, we introduce DentBench, a comprehensive benchmark covering eight dental subspecialties, more diseases, imaging modalities, and a wide geographical distribution. DentVFM shows impressive generalist intelligence, demonstrating robust generalization to diverse dental tasks, such as disease diagnosis, treatment analysis, biomarker identification, and anatomical landmark detection and segmentation. Experimental results indicate DentVFM significantly outperforms supervised, self-supervised, and weakly supervised baselines, offering superior generalization, label efficiency, and scalability. Additionally, DentVFM enables cross-modality diagnostics, providing more reliable results than experienced dentists in situations where conventional imaging is unavailable. DentVFM sets a new paradigm for dental AI, offering a scalable, adaptable, and label-efficient model to improve intelligent dental healthcare and address critical gaps in global oral healthcare.
PathRWKV: Enabling Whole Slide Prediction with Recurrent-Transformer
Mar 05, 2025


Pathological diagnosis plays a critical role in clinical practice, where the whole slide images (WSIs) are widely applied. Through a two-stage paradigm, recent deep learning approaches enhance the WSI analysis with tile-level feature extracting and slide-level feature modeling. Current Transformer models achieved improvement in the efficiency and accuracy to previous multiple instance learning based approaches. However, three core limitations persist, as they do not: (1) robustly address the modeling on variable scales for different slides, (2) effectively balance model complexity and data availability, and (3) balance training efficiency and inference performance. To explicitly address them, we propose a novel model for slide modeling, PathRWKV. Via a recurrent structure, we enable the model for dynamic perceptible tiles in slide-level modeling, which novelly enables the prediction on all tiles in the inference stage. Moreover, we employ linear attention instead of conventional matrix multiplication attention to reduce model complexity and overfitting problem. Lastly, we hinge multi-task learning to enable modeling on versatile tasks simultaneously, improving training efficiency, and asynchronous structure design to draw an effective conclusion on all tiles during inference, enhancing inference performance. Experimental results suggest that PathRWKV outperforms the current state-of-the-art methods in various downstream tasks on multiple datasets. The code and datasets are publicly available.
UnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
FedGraph: an Aggregation Method from Graph Perspective
Oct 06, 2022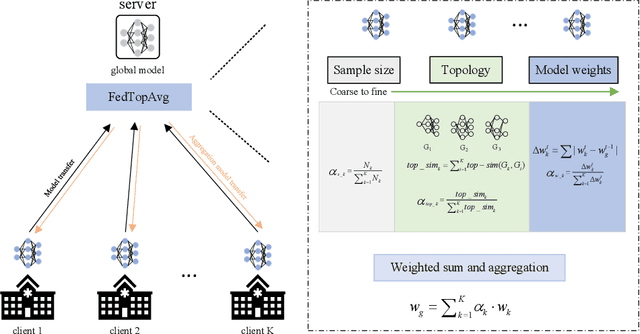



With the increasingly strengthened data privacy act and the difficult data centralization, Federated Learning (FL) has become an effective solution to collaboratively train the model while preserving each client's privacy. FedAvg is a standard aggregation algorithm that makes the proportion of dataset size of each client as aggregation weight. However, it can't deal with non-independent and identically distributed (non-i.i.d) data well because of its fixed aggregation weights and the neglect of data distribution. In this paper, we propose an aggregation strategy that can effectively deal with non-i.i.d dataset, namely FedGraph, which can adjust the aggregation weights adaptively according to the training condition of local models in whole training process. The FedGraph takes three factors into account from coarse to fine: the proportion of each local dataset size, the topology factor of model graphs, and the model weights. We calculate the gravitational force between local models by transforming the local models into topology graphs. The FedGraph can explore the internal correlation between local models better through the weighted combination of the proportion each local dataset, topology structure, and model weights. The proposed FedGraph has been applied to the MICCAI Federated Tumor Segmentation Challenge 2021 (FeTS) datasets, and the validation results show that our method surpasses the previous state-of-the-art by 2.76 mean Dice Similarity Score. The source code will be available at Github.
MISSFormer: An Effective Medical Image Segmentation Transformer
Sep 15, 2021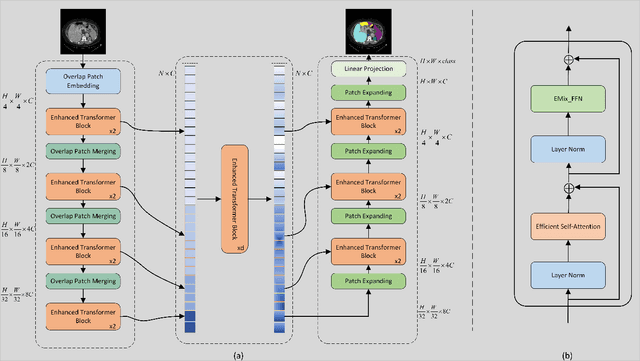

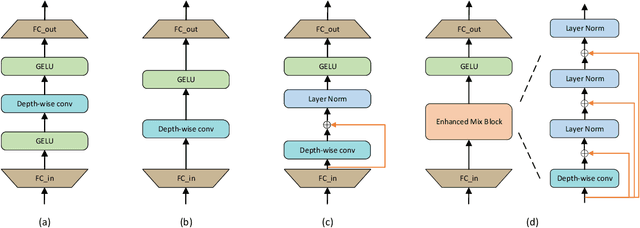

The CNN-based methods have achieved impressive results in medical image segmentation, but it failed to capture the long-range dependencies due to the inherent locality of convolution operation. Transformer-based methods are popular in vision tasks recently because of its capacity of long-range dependencies and get a promising performance. However, it lacks in modeling local context, although some works attempted to embed convolutional layer to overcome this problem and achieved some improvement, but it makes the feature inconsistent and fails to leverage the natural multi-scale features of hierarchical transformer, which limit the performance of models. In this paper, taking medical image segmentation as an example, we present MISSFormer, an effective and powerful Medical Image Segmentation tranSFormer. MISSFormer is a hierarchical encoder-decoder network and has two appealing designs: 1) A feed forward network is redesigned with the proposed Enhanced Transformer Block, which makes features aligned adaptively and enhances the long-range dependencies and local context. 2) We proposed Enhanced Transformer Context Bridge, a context bridge with the enhanced transformer block to model the long-range dependencies and local context of multi-scale features generated by our hierarchical transformer encoder. Driven by these two designs, the MISSFormer shows strong capacity to capture more valuable dependencies and context in medical image segmentation. The experiments on multi-organ and cardiac segmentation tasks demonstrate the superiority, effectiveness and robustness of our MISSFormer, the exprimental results of MISSFormer trained from scratch even outperforms state-of-the-art methods pretrained on ImageNet, and the core designs can be generalized to other visual segmentation tasks. The code will be released in Github.
Soft-Root-Sign Activation Function
Mar 01, 2020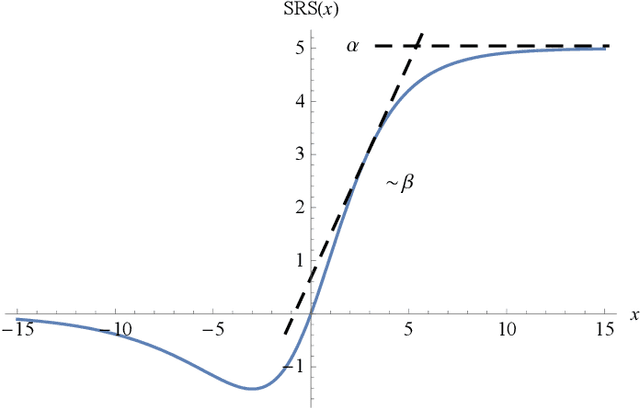
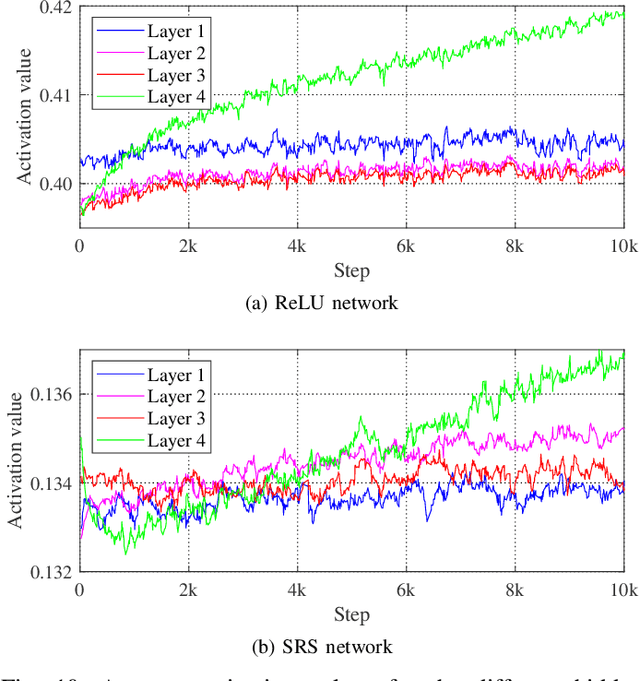
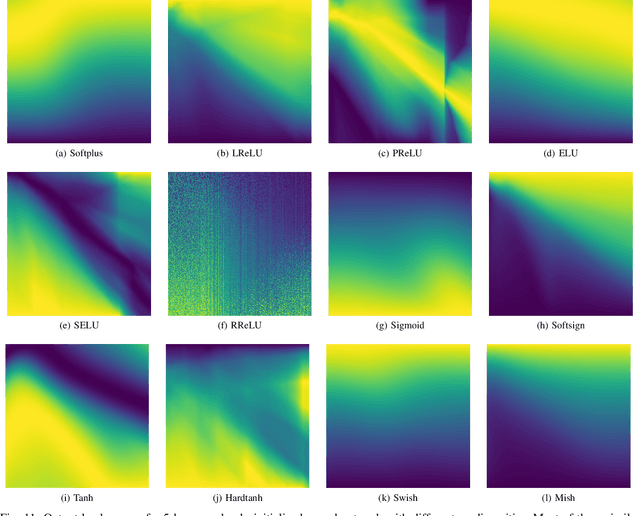
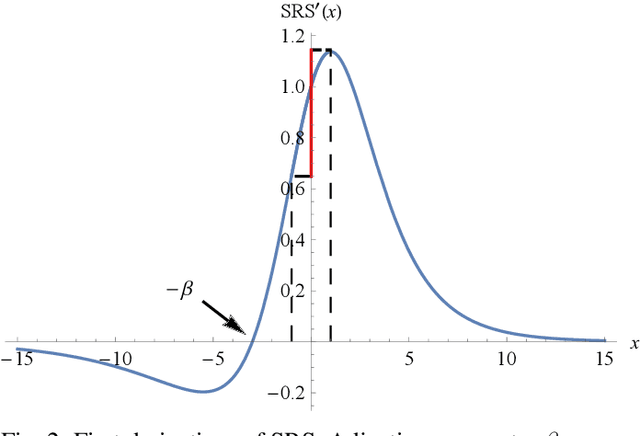
The choice of activation function in deep networks has a significant effect on the training dynamics and task performance. At present, the most effective and widely-used activation function is ReLU. However, because of the non-zero mean, negative missing and unbounded output, ReLU is at a potential disadvantage during optimization. To this end, we introduce a novel activation function to manage to overcome the above three challenges. The proposed nonlinearity, namely "Soft-Root-Sign" (SRS), is smooth, non-monotonic, and bounded. Notably, the bounded property of SRS distinguishes itself from most state-of-the-art activation functions. In contrast to ReLU, SRS can adaptively adjust the output by a pair of independent trainable parameters to capture negative information and provide zero-mean property, which leading not only to better generalization performance, but also to faster learning speed. It also avoids and rectifies the output distribution to be scattered in the non-negative real number space, making it more compatible with batch normalization (BN) and less sensitive to initialization. In experiments, we evaluated SRS on deep networks applied to a variety of tasks, including image classification, machine translation and generative modelling. Our SRS matches or exceeds models with ReLU and other state-of-the-art nonlinearities, showing that the proposed activation function is generalized and can achieve high performance across tasks. Ablation study further verified the compatibility with BN and self-adaptability for different initialization.
Comb Convolution for Efficient Convolutional Architecture
Nov 01, 2019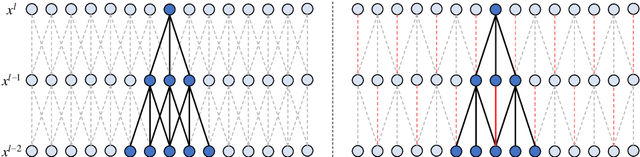
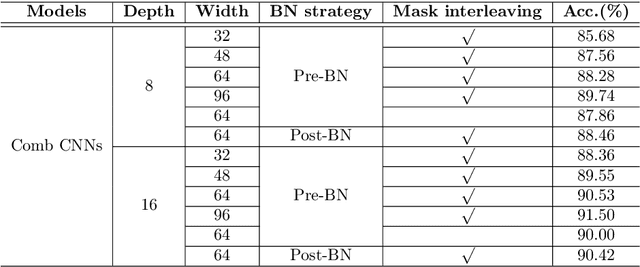
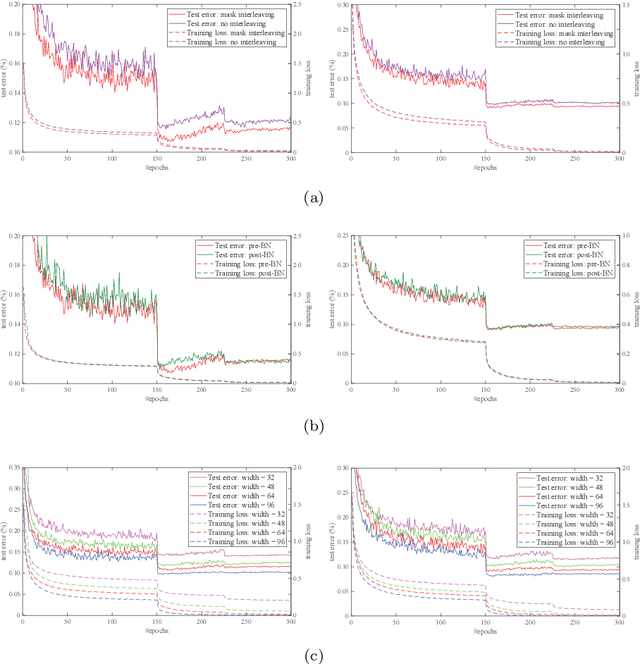
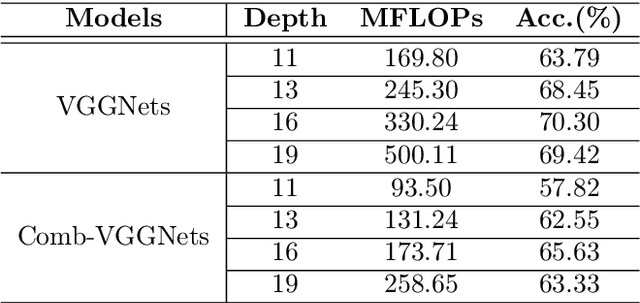
Convolutional neural networks (CNNs) are inherently suffering from massively redundant computation (FLOPs) due to the dense connection pattern between feature maps and convolution kernels. Recent research has investigated the sparse relationship between channels, however, they ignored the spatial relationship within a channel. In this paper, we present a novel convolutional operator, namely comb convolution, to exploit the intra-channel sparse relationship among neurons. The proposed convolutional operator eliminates nearly 50% of connections by inserting uniform mappings into standard convolutions and removing about half of spatial connections in convolutional layer. Notably, our work is orthogonal and complementary to existing methods that reduce channel-wise redundancy. Thus, it has great potential to further increase efficiency through integrating the comb convolution to existing architectures. Experimental results demonstrate that by simply replacing standard convolutions with comb convolutions on state-of-the-art CNN architectures (e.g., VGGNets, Xception and SE-Net), we can achieve 50% FLOPs reduction while still maintaining the accuracy.
Representing Sets as Summed Semantic Vectors
Sep 24, 2018
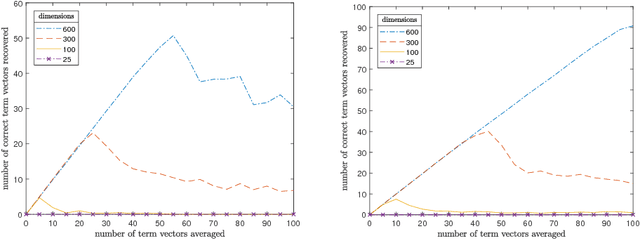
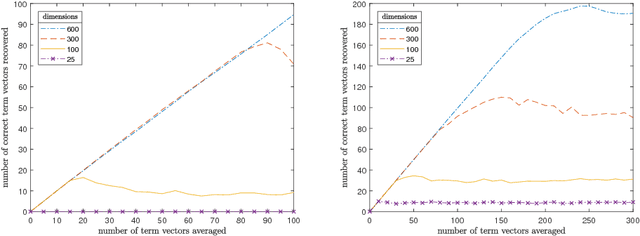
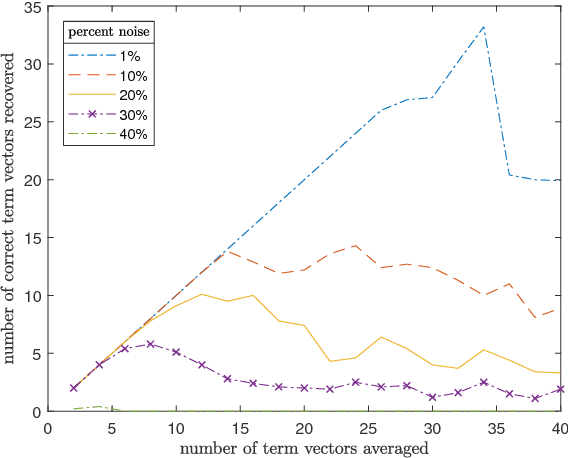
Representing meaning in the form of high dimensional vectors is a common and powerful tool in biologically inspired architectures. While the meaning of a set of concepts can be summarized by taking a (possibly weighted) sum of their associated vectors, this has generally been treated as a one-way operation. In this paper we show how a technique built to aid sparse vector decomposition allows in many cases the exact recovery of the inputs and weights to such a sum, allowing a single vector to represent an entire set of vectors from a dictionary. We characterize the number of vectors that can be recovered under various conditions, and explore several ways such a tool can be used for vector-based reasoning.
Hi-Fi: Hierarchical Feature Integration for Skeleton Detection
Aug 07, 2018
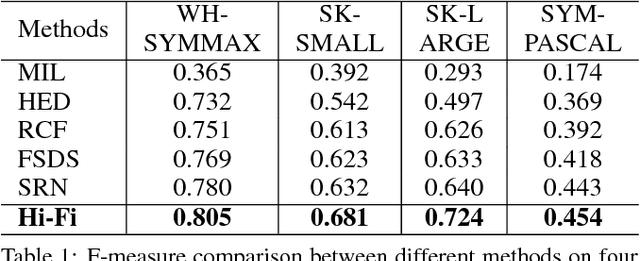

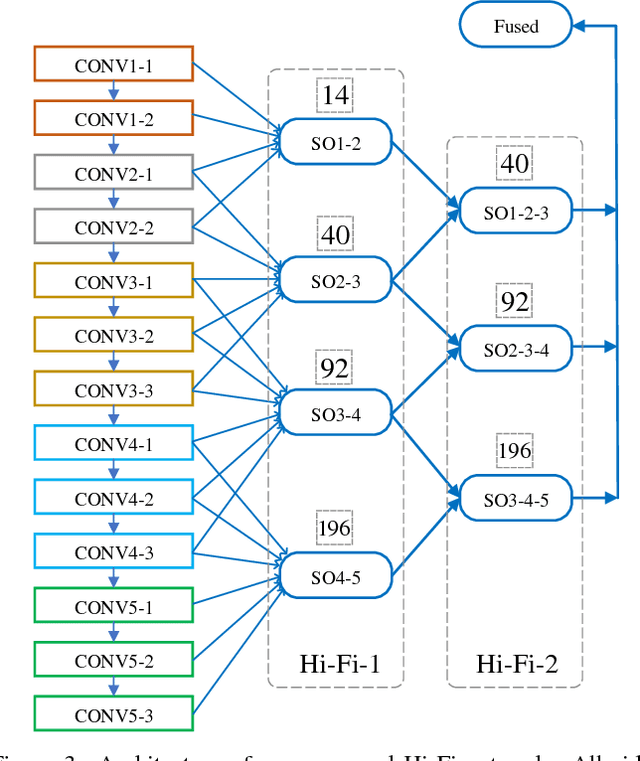
In natural images, the scales (thickness) of object skeletons may dramatically vary among objects and object parts, making object skeleton detection a challenging problem. We present a new convolutional neural network (CNN) architecture by introducing a novel hierarchical feature integration mechanism, named Hi-Fi, to address the skeleton detection problem. The proposed CNN-based approach has a powerful multi-scale feature integration ability that intrinsically captures high-level semantics from deeper layers as well as low-level details from shallower layers. % By hierarchically integrating different CNN feature levels with bidirectional guidance, our approach (1) enables mutual refinement across features of different levels, and (2) possesses the strong ability to capture both rich object context and high-resolution details. Experimental results show that our method significantly outperforms the state-of-the-art methods in terms of effectively fusing features from very different scales, as evidenced by a considerable performance improvement on several benchmarks.