 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedGraph: an Aggregation Method from Graph Perspective
Oct 06, 2022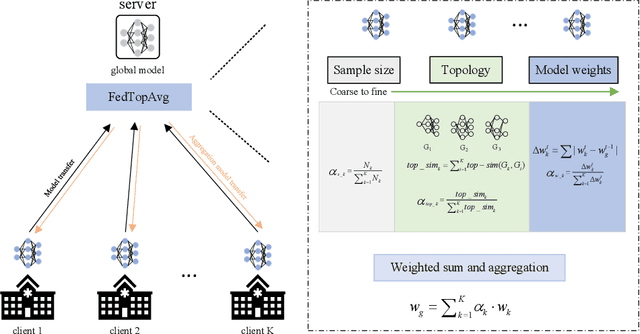



With the increasingly strengthened data privacy act and the difficult data centralization, Federated Learning (FL) has become an effective solution to collaboratively train the model while preserving each client's privacy. FedAvg is a standard aggregation algorithm that makes the proportion of dataset size of each client as aggregation weight. However, it can't deal with non-independent and identically distributed (non-i.i.d) data well because of its fixed aggregation weights and the neglect of data distribution. In this paper, we propose an aggregation strategy that can effectively deal with non-i.i.d dataset, namely FedGraph, which can adjust the aggregation weights adaptively according to the training condition of local models in whole training process. The FedGraph takes three factors into account from coarse to fine: the proportion of each local dataset size, the topology factor of model graphs, and the model weights. We calculate the gravitational force between local models by transforming the local models into topology graphs. The FedGraph can explore the internal correlation between local models better through the weighted combination of the proportion each local dataset, topology structure, and model weights. The proposed FedGraph has been applied to the MICCAI Federated Tumor Segmentation Challenge 2021 (FeTS) datasets, and the validation results show that our method surpasses the previous state-of-the-art by 2.76 mean Dice Similarity Score. The source code will be available at Github.
MISSFormer: An Effective Medical Image Segmentation Transformer
Sep 15, 2021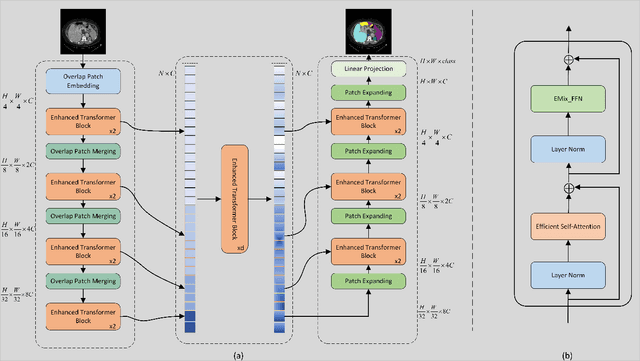

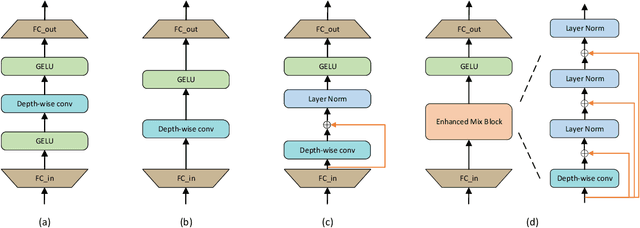

The CNN-based methods have achieved impressive results in medical image segmentation, but it failed to capture the long-range dependencies due to the inherent locality of convolution operation. Transformer-based methods are popular in vision tasks recently because of its capacity of long-range dependencies and get a promising performance. However, it lacks in modeling local context, although some works attempted to embed convolutional layer to overcome this problem and achieved some improvement, but it makes the feature inconsistent and fails to leverage the natural multi-scale features of hierarchical transformer, which limit the performance of models. In this paper, taking medical image segmentation as an example, we present MISSFormer, an effective and powerful Medical Image Segmentation tranSFormer. MISSFormer is a hierarchical encoder-decoder network and has two appealing designs: 1) A feed forward network is redesigned with the proposed Enhanced Transformer Block, which makes features aligned adaptively and enhances the long-range dependencies and local context. 2) We proposed Enhanced Transformer Context Bridge, a context bridge with the enhanced transformer block to model the long-range dependencies and local context of multi-scale features generated by our hierarchical transformer encoder. Driven by these two designs, the MISSFormer shows strong capacity to capture more valuable dependencies and context in medical image segmentation. The experiments on multi-organ and cardiac segmentation tasks demonstrate the superiority, effectiveness and robustness of our MISSFormer, the exprimental results of MISSFormer trained from scratch even outperforms state-of-the-art methods pretrained on ImageNet, and the core designs can be generalized to other visual segmentation tasks. The code will be released in Github.