 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
PathRWKV: Enabling Whole Slide Prediction with Recurrent-Transformer
Mar 05, 2025


Pathological diagnosis plays a critical role in clinical practice, where the whole slide images (WSIs) are widely applied. Through a two-stage paradigm, recent deep learning approaches enhance the WSI analysis with tile-level feature extracting and slide-level feature modeling. Current Transformer models achieved improvement in the efficiency and accuracy to previous multiple instance learning based approaches. However, three core limitations persist, as they do not: (1) robustly address the modeling on variable scales for different slides, (2) effectively balance model complexity and data availability, and (3) balance training efficiency and inference performance. To explicitly address them, we propose a novel model for slide modeling, PathRWKV. Via a recurrent structure, we enable the model for dynamic perceptible tiles in slide-level modeling, which novelly enables the prediction on all tiles in the inference stage. Moreover, we employ linear attention instead of conventional matrix multiplication attention to reduce model complexity and overfitting problem. Lastly, we hinge multi-task learning to enable modeling on versatile tasks simultaneously, improving training efficiency, and asynchronous structure design to draw an effective conclusion on all tiles during inference, enhancing inference performance. Experimental results suggest that PathRWKV outperforms the current state-of-the-art methods in various downstream tasks on multiple datasets. The code and datasets are publicly available.
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Jul 16, 2024
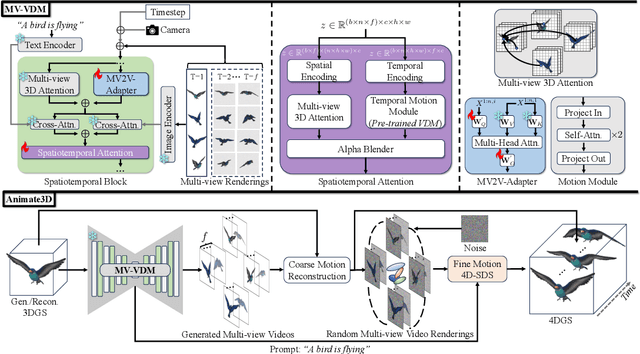


Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image-conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model's multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct motions directly from generated multi-view videos, followed by the introduced 4D-SDS to refine both appearance and motion. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models will be open-released.
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Apr 04, 2024Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
Mar 22, 2024
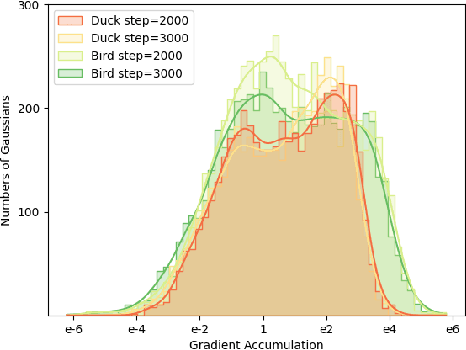

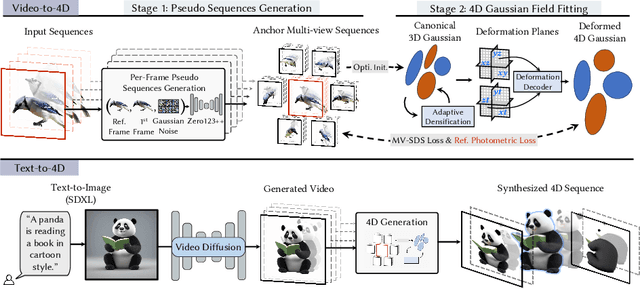
Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation. Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences, we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization. Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.
Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video
Nov 06, 2023In this paper, we present Consistent4D, a novel approach for generating 4D dynamic objects from uncalibrated monocular videos. Uniquely, we cast the 360-degree dynamic object reconstruction as a 4D generation problem, eliminating the need for tedious multi-view data collection and camera calibration. This is achieved by leveraging the object-level 3D-aware image diffusion model as the primary supervision signal for training Dynamic Neural Radiance Fields (DyNeRF). Specifically, we propose a Cascade DyNeRF to facilitate stable convergence and temporal continuity under the supervision signal which is discrete along the time axis. To achieve spatial and temporal consistency, we further introduce an Interpolation-driven Consistency Loss. It is optimized by minimizing the discrepancy between rendered frames from DyNeRF and interpolated frames from a pre-trained video interpolation model. Extensive experiments show that our Consistent4D can perform competitively to prior art alternatives, opening up new possibilities for 4D dynamic object generation from monocular videos, whilst also demonstrating advantage for conventional text-to-3D generation tasks. Our project page is https://consistent4d.github.io/.
PolarFormer: Multi-camera 3D Object Detection with Polar Transformers
Jul 12, 2022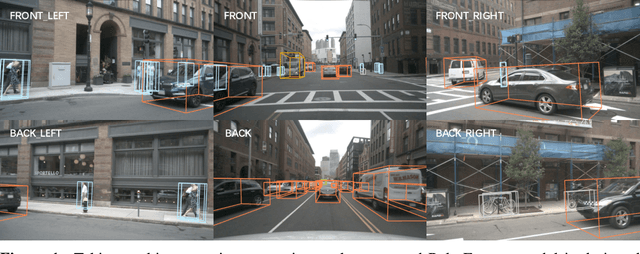
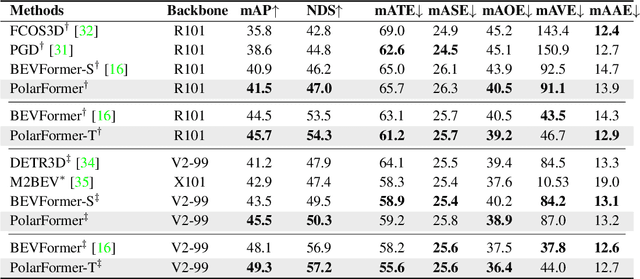
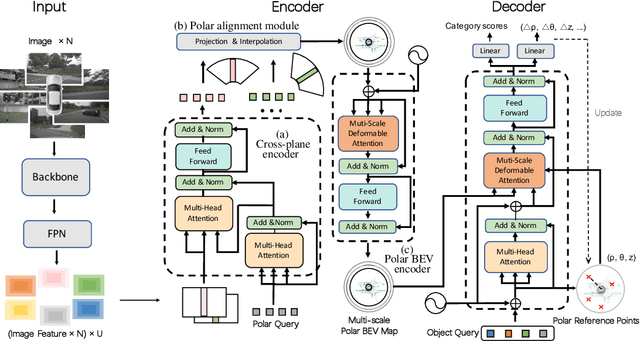
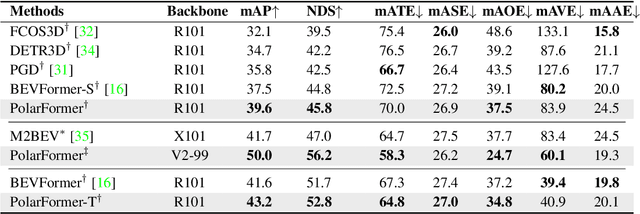
3D object detection in autonomous driving aims to reason "what" and "where" the objects of interest present in a 3D world. Following the conventional wisdom of previous 2D object detection, existing methods often adopt the canonical Cartesian coordinate system with perpendicular axis. However, we conjugate that this does not fit the nature of the ego car's perspective, as each onboard camera perceives the world in shape of wedge intrinsic to the imaging geometry with radical (non-perpendicular) axis. Hence, in this paper we advocate the exploitation of the Polar coordinate system and propose a new Polar Transformer (PolarFormer) for more accurate 3D object detection in the bird's-eye-view (BEV) taking as input only multi-camera 2D images. Specifically, we design a cross attention based Polar detection head without restriction to the shape of input structure to deal with irregular Polar grids. For tackling the unconstrained object scale variations along Polar's distance dimension, we further introduce a multi-scalePolar representation learning strategy. As a result, our model can make best use of the Polar representation rasterized via attending to the corresponding image observation in a sequence-to-sequence fashion subject to the geometric constraints. Thorough experiments on the nuScenes dataset demonstrate that our PolarFormer outperforms significantly state-of-the-art 3D object detection alternatives, as well as yielding competitive performance on BEV semantic segmentation task.