 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgRAW: Multi-Agent Workflow with Chain-of-Thought Reasoning for Surgical Intelligence
Mar 13, 2025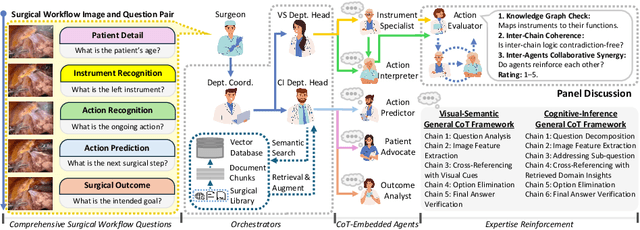
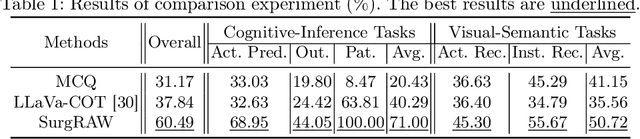
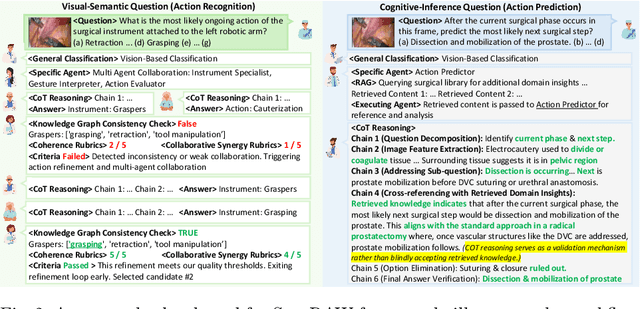
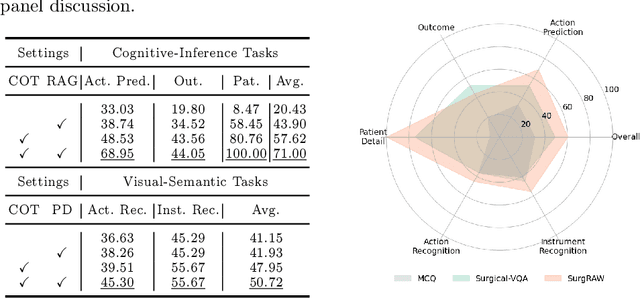
Integration of Vision-Language Models (VLMs) in surgical intelligence is hindered by hallucinations, domain knowledge gaps, and limited understanding of task interdependencies within surgical scenes, undermining clinical reliability. While recent VLMs demonstrate strong general reasoning and thinking capabilities, they still lack the domain expertise and task-awareness required for precise surgical scene interpretation. Although Chain-of-Thought (CoT) can structure reasoning more effectively, current approaches rely on self-generated CoT steps, which often exacerbate inherent domain gaps and hallucinations. To overcome this, we present SurgRAW, a CoT-driven multi-agent framework that delivers transparent, interpretable insights for most tasks in robotic-assisted surgery. By employing specialized CoT prompts across five tasks: instrument recognition, action recognition, action prediction, patient data extraction, and outcome assessment, SurgRAW mitigates hallucinations through structured, domain-aware reasoning. Retrieval-Augmented Generation (RAG) is also integrated to external medical knowledge to bridge domain gaps and improve response reliability. Most importantly, a hierarchical agentic system ensures that CoT-embedded VLM agents collaborate effectively while understanding task interdependencies, with a panel discussion mechanism promotes logical consistency. To evaluate our method, we introduce SurgCoTBench, the first reasoning-based dataset with structured frame-level annotations. With comprehensive experiments, we demonstrate the effectiveness of proposed SurgRAW with 29.32% accuracy improvement over baseline VLMs on 12 robotic procedures, achieving the state-of-the-art performance and advancing explainable, trustworthy, and autonomous surgical assistance.
UnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.