 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
ASTormer: An AST Structure-aware Transformer Decoder for Text-to-SQL
Oct 28, 2023Text-to-SQL aims to generate an executable SQL program given the user utterance and the corresponding database schema. To ensure the well-formedness of output SQLs, one prominent approach adopts a grammar-based recurrent decoder to produce the equivalent SQL abstract syntax tree (AST). However, previous methods mainly utilize an RNN-series decoder, which 1) is time-consuming and inefficient and 2) introduces very few structure priors. In this work, we propose an AST structure-aware Transformer decoder (ASTormer) to replace traditional RNN cells. The structural knowledge, such as node types and positions in the tree, is seamlessly incorporated into the decoder via both absolute and relative position embeddings. Besides, the proposed framework is compatible with different traversing orders even considering adaptive node selection. Extensive experiments on five text-to-SQL benchmarks demonstrate the effectiveness and efficiency of our structured decoder compared to competitive baselines.
CSS: A Large-scale Cross-schema Chinese Text-to-SQL Medical Dataset
May 25, 2023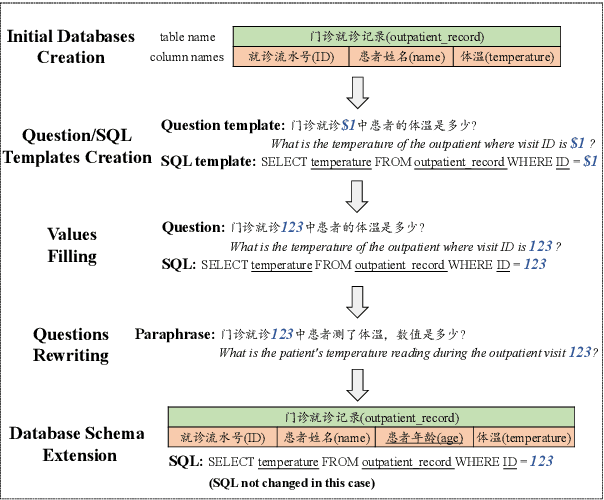
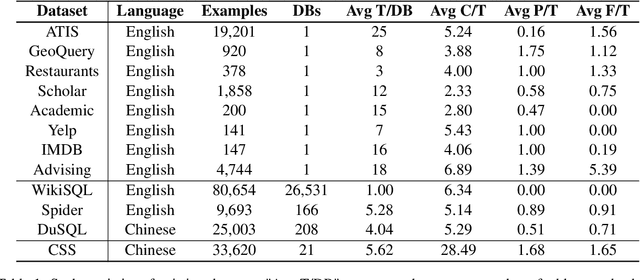
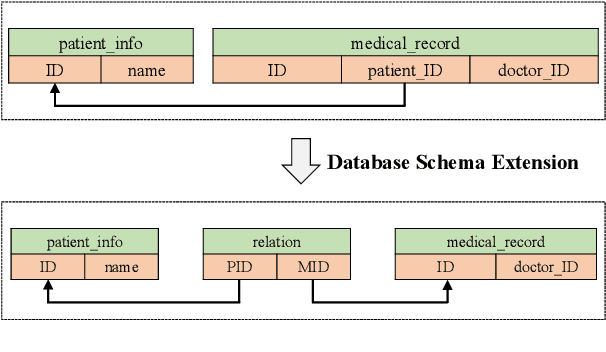
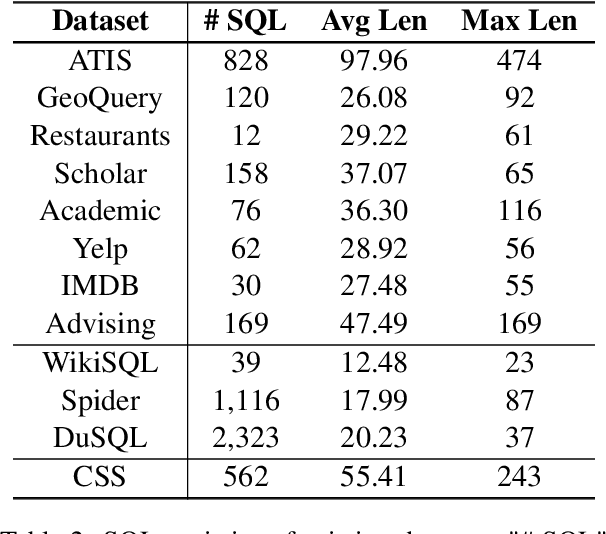
The cross-domain text-to-SQL task aims to build a system that can parse user questions into SQL on complete unseen databases, and the single-domain text-to-SQL task evaluates the performance on identical databases. Both of these setups confront unavoidable difficulties in real-world applications. To this end, we introduce the cross-schema text-to-SQL task, where the databases of evaluation data are different from that in the training data but come from the same domain. Furthermore, we present CSS, a large-scale CrosS-Schema Chinese text-to-SQL dataset, to carry on corresponding studies. CSS originally consisted of 4,340 question/SQL pairs across 2 databases. In order to generalize models to different medical systems, we extend CSS and create 19 new databases along with 29,280 corresponding dataset examples. Moreover, CSS is also a large corpus for single-domain Chinese text-to-SQL studies. We present the data collection approach and a series of analyses of the data statistics. To show the potential and usefulness of CSS, benchmarking baselines have been conducted and reported. Our dataset is publicly available at \url{https://huggingface.co/datasets/zhanghanchong/css}.
On the Structural Generalization in Text-to-SQL
Jan 21, 2023



Exploring the generalization of a text-to-SQL parser is essential for a system to automatically adapt the real-world databases. Previous works provided investigations focusing on lexical diversity, including the influence of the synonym and perturbations in both natural language questions and databases. However, research on the structure variety of database schema~(DS) is deficient. Specifically, confronted with the same input question, the target SQL is probably represented in different ways when the DS comes to a different structure. In this work, we provide in-deep discussions about the structural generalization of text-to-SQL tasks. We observe that current datasets are too templated to study structural generalization. To collect eligible test data, we propose a framework to generate novel text-to-SQL data via automatic and synchronous (DS, SQL) pair altering. In the experiments, significant performance reduction when evaluating well-trained text-to-SQL models on the synthetic samples demonstrates the limitation of current research regarding structural generalization. According to comprehensive analysis, we suggest the practical reason is the overfitting of (NL, SQL) patterns.
2D LiDAR and Camera Fusion Using Motion Cues for Indoor Layout Estimation
Apr 24, 2022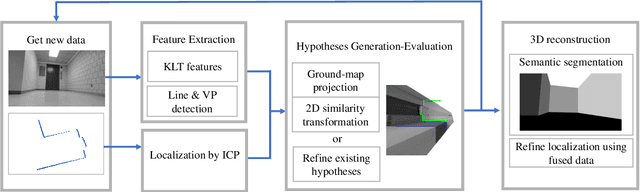
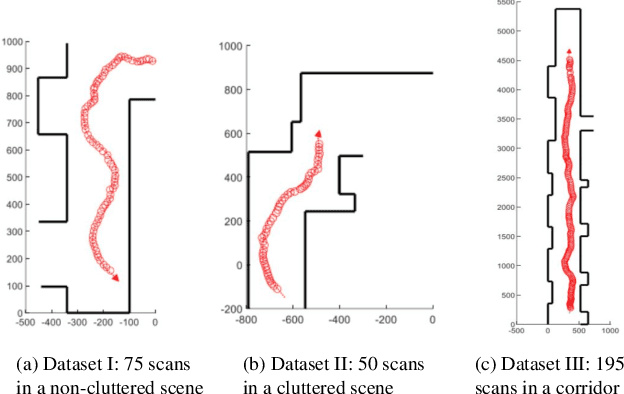


This paper presents a novel indoor layout estimation system based on the fusion of 2D LiDAR and intensity camera data. A ground robot explores an indoor space with a single floor and vertical walls, and collects a sequence of intensity images and 2D LiDAR datasets. The LiDAR provides accurate depth information, while the camera captures high-resolution data for semantic interpretation. The alignment of sensor outputs and image segmentation are computed jointly by aligning LiDAR points, as samples of the room contour, to ground-wall boundaries in the images. The alignment problem is decoupled into a top-down view projection and a 2D similarity transformation estimation, which can be solved according to the vertical vanishing point and motion of two sensors. The recursive random sample consensus algorithm is implemented to generate, evaluate and optimize multiple hypotheses with the sequential measurements. The system allows jointly analyzing the geometric interpretation from different sensors without offline calibration. The ambiguity in images for ground-wall boundary extraction is removed with the assistance of LiDAR observations, which improves the accuracy of semantic segmentation. The localization and mapping is refined using the fused data, which enables the system to work reliably in scenes with low texture or low geometric features.
Unsupervised Local Discrimination for Medical Images
Aug 21, 2021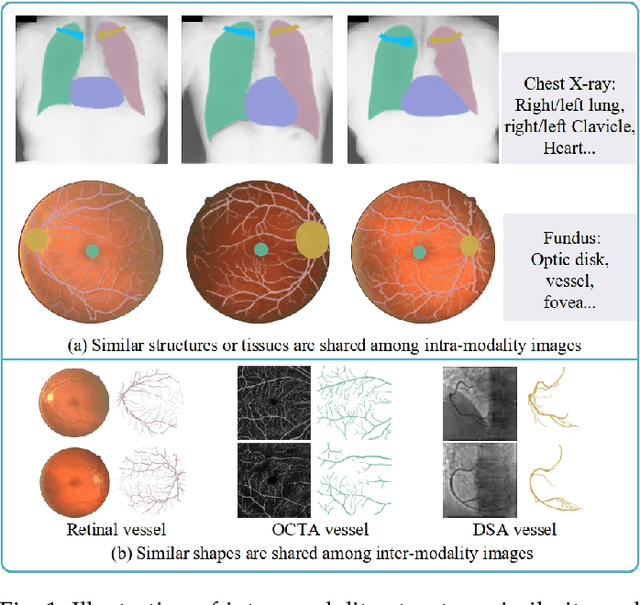
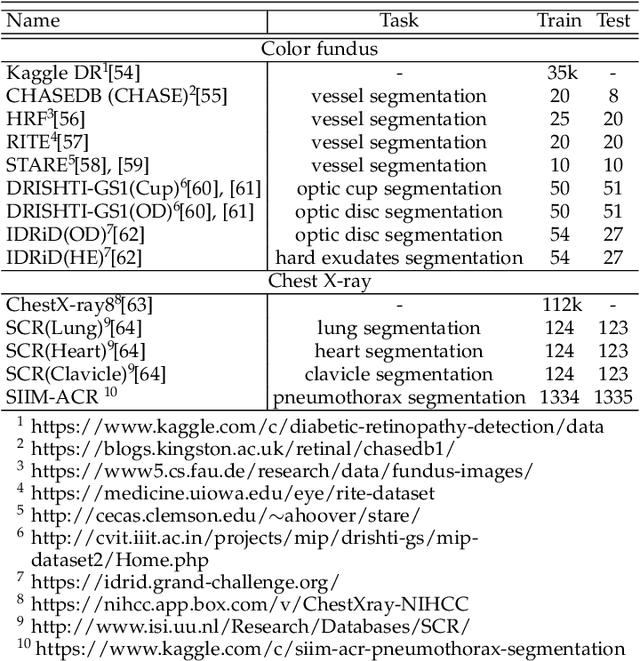

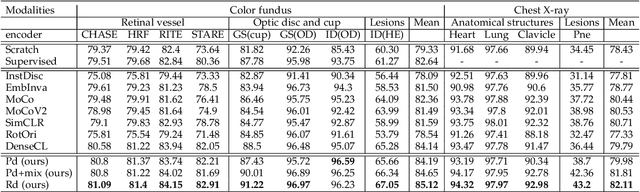
Contrastive representation learning is an effective unsupervised method to alleviate the demand for expensive annotated data in medical image processing. Recent work mainly based on instance-wise discrimination to learn global features, while neglect local details, which limit their application in processing tiny anatomical structures, tissues and lesions. Therefore, we aim to propose a universal local discrmination framework to learn local discriminative features to effectively initialize medical models, meanwhile, we systematacially investigate its practical medical applications. Specifically, based on the common property of intra-modality structure similarity, i.e. similar structures are shared among the same modality images, a systematic local feature learning framework is proposed. Instead of making instance-wise comparisons based on global embedding, our method makes pixel-wise embedding and focuses on measuring similarity among patches and regions. The finer contrastive rule makes the learnt representation more generalized for segmentation tasks and outperform extensive state-of-the-art methods by wining 11 out of all 12 downstream tasks in color fundus and chest X-ray. Furthermore, based on the property of inter-modality shape similarity, i.e. structures may share similar shape although in different medical modalities, we joint across-modality shape prior into region discrimination to realize unsupervised segmentation. It shows the feaibility of segmenting target only based on shape description from other modalities and inner pattern similarity provided by region discrimination. Finally, we enhance the center-sensitive ability of patch discrimination by introducing center-sensitive averaging to realize one-shot landmark localization, this is an effective application for patch discrimination.
Unsupervised Learning of Local Discriminative Representation for Medical Images
Dec 17, 2020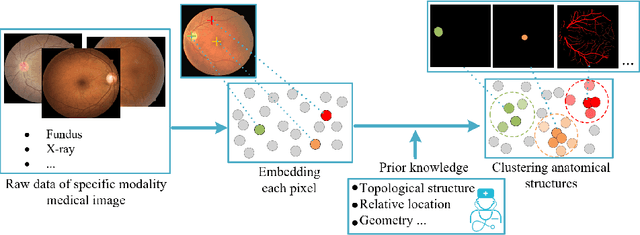
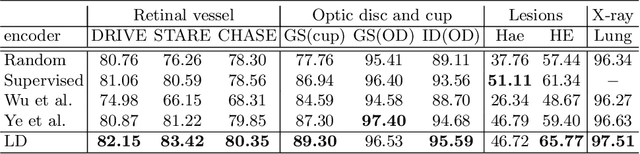
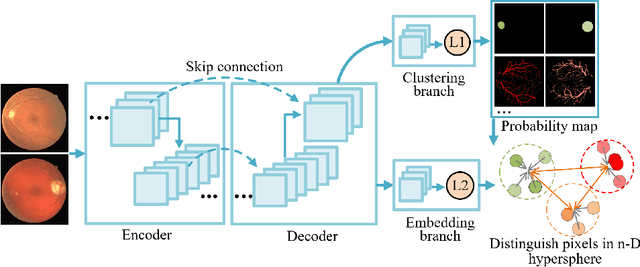
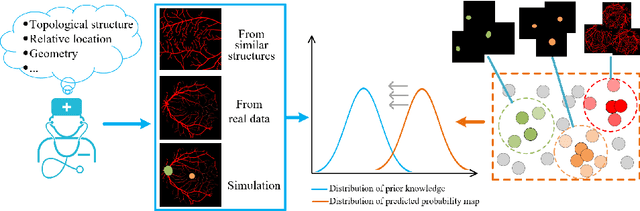
Local discriminative representation is needed in many medical image analysis tasks such as identifying sub-types of lesion or segmenting detailed components of anatomical structures by measuring similarity of local image regions. However, the commonly applied supervised representation learning methods require a large amount of annotated data, and unsupervised discriminative representation learning distinguishes different images by learning a global feature. In order to avoid the limitations of these two methods and be suitable for localized medical image analysis tasks, we introduce local discrimination into unsupervised representation learning in this work. The model contains two branches: one is an embedding branch which learns an embedding function to disperse dissimilar pixels over a low-dimensional hypersphere; and the other is a clustering branch which learns a clustering function to classify similar pixels into the same cluster. These two branches are trained simultaneously in a mutually beneficial pattern, and the learnt local discriminative representations are able to well measure the similarity of local image regions. These representations can be transferred to enhance various downstream tasks. Meanwhile, they can also be applied to cluster anatomical structures from unlabeled medical images under the guidance of topological priors from simulation or other structures with similar topological characteristics. The effectiveness and usefulness of the proposed method are demonstrated by enhancing various downstream tasks and clustering anatomical structures in retinal images and chest X-ray images. The corresponding code is available at https://github.com/HuaiChen-1994/LDLearning.
Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking
Apr 10, 2020
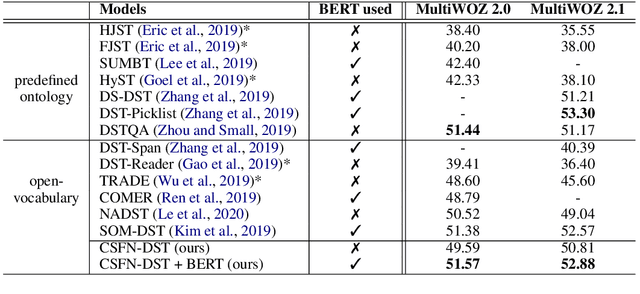


Dialogue state tracking (DST) aims at estimating the current dialogue state given all the preceding conversation. For multi-domain DST, the data sparsity problem is a major obstacle due to increased numbers of state candidates and dialogue lengths. To encode the dialogue context efficiently, we utilize the previous dialogue state (predicted) and the current dialogue utterance as the input for DST. To consider relations among different domain-slots, the schema graph involving prior knowledge is exploited. In this paper, a novel context and schema fusion network is proposed to encode the dialogue context and schema graph by using internal and external attention mechanisms. Experiment results show that our approach can obtain new state-of-the-art performance of the open-vocabulary DST on both MultiWOZ 2.0 and MultiWOZ 2.1 benchmarks.
Indoor Layout Estimation by 2D LiDAR and Camera Fusion
Jan 15, 2020
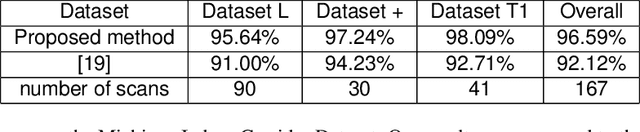


This paper presents an algorithm for indoor layout estimation and reconstruction through the fusion of a sequence of captured images and LiDAR data sets. In the proposed system, a movable platform collects both intensity images and 2D LiDAR information. Pose estimation and semantic segmentation is computed jointly by aligning the LiDAR points to line segments from the images. For indoor scenes with walls orthogonal to floor, the alignment problem is decoupled into top-down view projection and a 2D similarity transformation estimation and solved by the recursive random sample consensus (R-RANSAC) algorithm. Hypotheses can be generated, evaluated and optimized by integrating new scans as the platform moves throughout the environment. The proposed method avoids the need of extensive prior training or a cuboid layout assumption, which is more effective and practical compared to most previous indoor layout estimation methods. Multi-sensor fusion allows the capability of providing accurate depth estimation and high resolution visual information.
Semantic Parsing with Dual Learning
Jul 24, 2019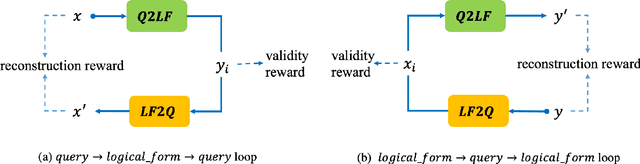
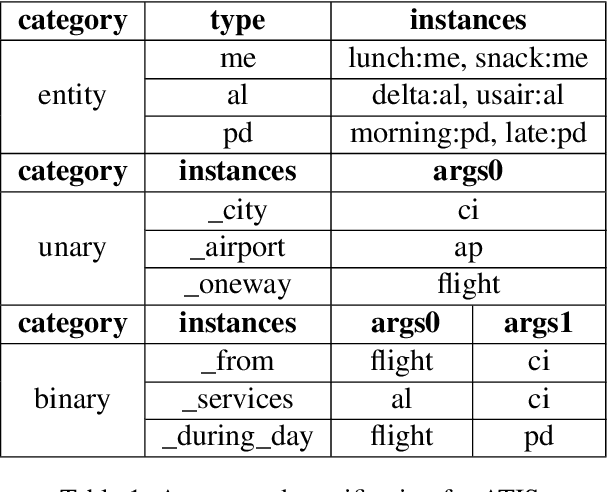

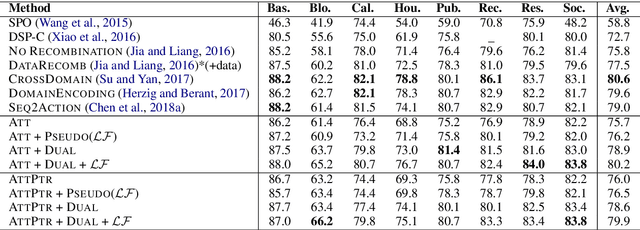
Semantic parsing converts natural language queries into structured logical forms. The paucity of annotated training samples is a fundamental challenge in this field. In this work, we develop a semantic parsing framework with the dual learning algorithm, which enables a semantic parser to make full use of data (labeled and even unlabeled) through a dual-learning game. This game between a primal model (semantic parsing) and a dual model (logical form to query) forces them to regularize each other, and can achieve feedback signals from some prior-knowledge. By utilizing the prior-knowledge of logical form structures, we propose a novel reward signal at the surface and semantic levels which tends to generate complete and reasonable logical forms. Experimental results show that our approach achieves new state-of-the-art performance on ATIS dataset and gets competitive performance on Overnight dataset.