 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Distill-Net: A Data Distillation Approach Tailored for Reply-based Continual Learning
May 26, 2025Replay-based continual learning (CL) methods assume that models trained on a small subset can also effectively minimize the empirical risk of the complete dataset. These methods maintain a memory buffer that stores a sampled subset of data from previous tasks to consolidate past knowledge. However, this assumption is not guaranteed in practice due to the limited capacity of the memory buffer and the heuristic criteria used for buffer data selection. To address this issue, we propose a new dataset distillation framework tailored for CL, which maintains a learnable memory buffer to distill the global information from the current task data and accumulated knowledge preserved in the previous memory buffer. Moreover, to avoid the computational overhead and overfitting risks associated with parameterizing the entire buffer during distillation, we introduce a lightweight distillation module that can achieve global information distillation solely by generating learnable soft labels for the memory buffer data. Extensive experiments show that, our method can achieve competitive results and effectively mitigates forgetting across various datasets. The source code will be publicly available.
Singular Value Fine-tuning for Few-Shot Class-Incremental Learning
Mar 13, 2025Class-Incremental Learning (CIL) aims to prevent catastrophic forgetting of previously learned classes while sequentially incorporating new ones. The more challenging Few-shot CIL (FSCIL) setting further complicates this by providing only a limited number of samples for each new class, increasing the risk of overfitting in addition to standard CIL challenges. While catastrophic forgetting has been extensively studied, overfitting in FSCIL, especially with large foundation models, has received less attention. To fill this gap, we propose the Singular Value Fine-tuning for FSCIL (SVFCL) and compared it with existing approaches for adapting foundation models to FSCIL, which primarily build on Parameter Efficient Fine-Tuning (PEFT) methods like prompt tuning and Low-Rank Adaptation (LoRA). Specifically, SVFCL applies singular value decomposition to the foundation model weights, keeping the singular vectors fixed while fine-tuning the singular values for each task, and then merging them. This simple yet effective approach not only alleviates the forgetting problem but also mitigates overfitting more effectively while significantly reducing trainable parameters. Extensive experiments on four benchmark datasets, along with visualizations and ablation studies, validate the effectiveness of SVFCL. The code will be made available.
Dual-CBA: Improving Online Continual Learning via Dual Continual Bias Adaptors from a Bi-level Optimization Perspective
Aug 26, 2024



In online continual learning (CL), models trained on changing distributions easily forget previously learned knowledge and bias toward newly received tasks. To address this issue, we present Continual Bias Adaptor (CBA), a bi-level framework that augments the classification network to adapt to catastrophic distribution shifts during training, enabling the network to achieve a stable consolidation of all seen tasks. However, the CBA module adjusts distribution shifts in a class-specific manner, exacerbating the stability gap issue and, to some extent, fails to meet the need for continual testing in online CL. To mitigate this challenge, we further propose a novel class-agnostic CBA module that separately aggregates the posterior probabilities of classes from new and old tasks, and applies a stable adjustment to the resulting posterior probabilities. We combine the two kinds of CBA modules into a unified Dual-CBA module, which thus is capable of adapting to catastrophic distribution shifts and simultaneously meets the real-time testing requirements of online CL. Besides, we propose Incremental Batch Normalization (IBN), a tailored BN module to re-estimate its population statistics for alleviating the feature bias arising from the inner loop optimization problem of our bi-level framework. To validate the effectiveness of the proposed method, we theoretically provide some insights into how it mitigates catastrophic distribution shifts, and empirically demonstrate its superiority through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
CBA: Improving Online Continual Learning via Continual Bias Adaptor
Aug 14, 2023



Online continual learning (CL) aims to learn new knowledge and consolidate previously learned knowledge from non-stationary data streams. Due to the time-varying training setting, the model learned from a changing distribution easily forgets the previously learned knowledge and biases toward the newly received task. To address this problem, we propose a Continual Bias Adaptor (CBA) module to augment the classifier network to adapt to catastrophic distribution change during training, such that the classifier network is able to learn a stable consolidation of previously learned tasks. In the testing stage, CBA can be removed which introduces no additional computation cost and memory overhead. We theoretically reveal the reason why the proposed method can effectively alleviate catastrophic distribution shifts, and empirically demonstrate its effectiveness through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
Learning to Adapt Classifier for Imbalanced Semi-supervised Learning
Jul 28, 2022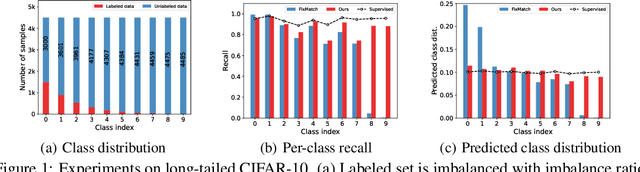
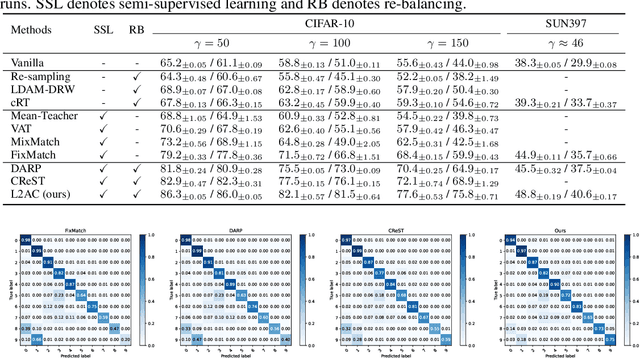
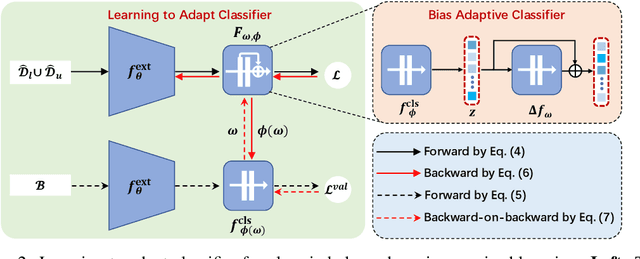
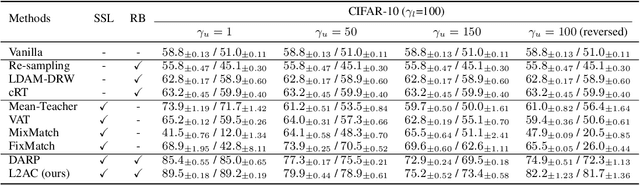
Pseudo-labeling has proven to be a promising semi-supervised learning (SSL) paradigm. Existing pseudo-labeling methods commonly assume that the class distributions of training data are balanced. However, such an assumption is far from realistic scenarios and existing pseudo-labeling methods suffer from severe performance degeneration in the context of class-imbalance. In this work, we investigate pseudo-labeling under imbalanced semi-supervised setups. The core idea is to automatically assimilate the training bias arising from class-imbalance, using a bias adaptive classifier that equips the original linear classifier with a bias attractor. The bias attractor is designed to be a light-weight residual network for adapting to the training bias. Specifically, the bias attractor is learned through a bi-level learning framework such that the bias adaptive classifier is able to fit imbalanced training data, while the linear classifier can give unbiased label prediction for each class. We conduct extensive experiments under various imbalanced semi-supervised setups, and the results demonstrate that our method can be applicable to different pseudo-labeling models and superior to the prior arts.
Revisiting Experience Replay: Continual Learning by Adaptively Tuning Task-wise Relationship
Jan 06, 2022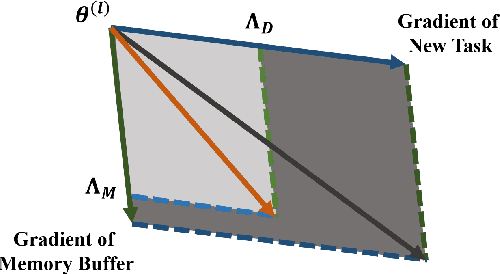
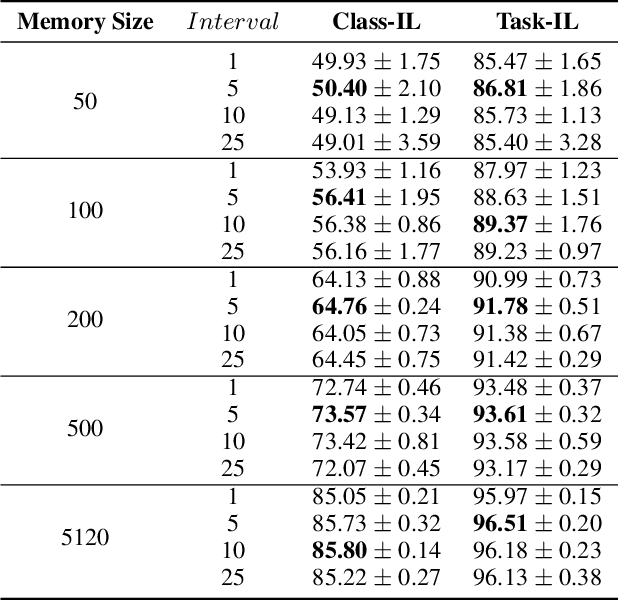

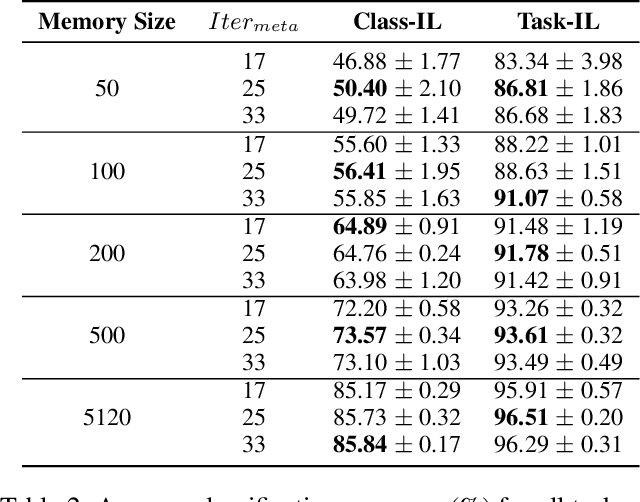
Continual learning requires models to learn new tasks while maintaining previously learned knowledge. Various algorithms have been proposed to address this real challenge. Till now, rehearsal-based methods, such as experience replay, have achieved state-of-the-art performance. These approaches save a small part of the data of the past tasks as a memory buffer to prevent models from forgetting previously learned knowledge. However, most of them treat every new task equally, i.e., fixed the hyperparameters of the framework while learning different new tasks. Such a setting lacks the consideration of the relationship/similarity between past and new tasks. For example, the previous knowledge/features learned from dogs are more beneficial for the identification of cats (new task), compared to those learned from buses. In this regard, we propose a meta learning algorithm based on bi-level optimization to adaptively tune the relationship between the knowledge extracted from the past and new tasks. Therefore, the model can find an appropriate direction of gradient during continual learning and avoid the serious overfitting problem on memory buffer. Extensive experiments are conducted on three publicly available datasets (i.e., CIFAR-10, CIFAR-100, and Tiny ImageNet). The experimental results demonstrate that the proposed method can consistently improve the performance of all baselines.
Label Hierarchy Transition: Modeling Class Hierarchies to Enhance Deep Classifiers
Dec 04, 2021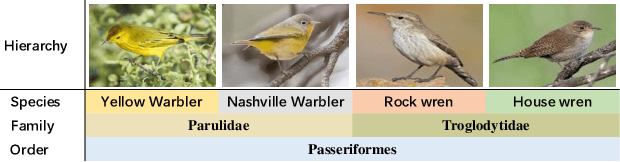
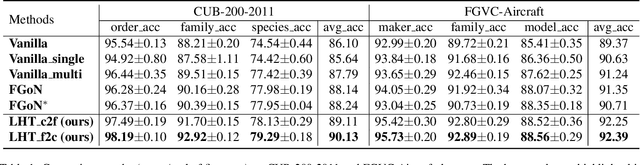
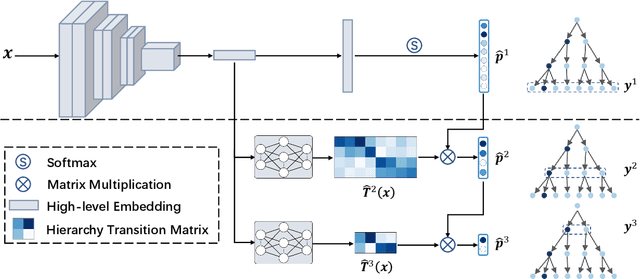
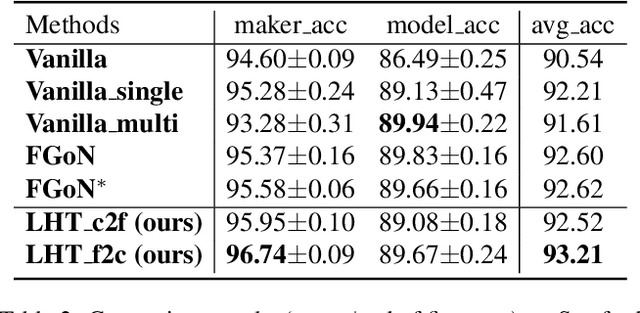
Hierarchical classification aims to sort the object into a hierarchy of categories. For example, a bird can be categorized according to a three-level hierarchy of order, family, and species. Existing methods commonly address hierarchical classification by decoupling it into several multi-class classification tasks. However, such a multi-task learning strategy fails to fully exploit the correlation among various categories across different hierarchies. In this paper, we propose Label Hierarchy Transition, a unified probabilistic framework based on deep learning, to address hierarchical classification. Specifically, we explicitly learn the label hierarchy transition matrices, whose column vectors represent the conditional label distributions of classes between two adjacent hierarchies and could be capable of encoding the correlation embedded in class hierarchies. We further propose a confusion loss, which encourages the classification network to learn the correlation across different label hierarchies during training. The proposed framework can be adapted to any existing deep network with only minor modifications. We experiment with three public benchmark datasets with various class hierarchies, and the results demonstrate the superiority of our approach beyond the prior arts. Source code will be made publicly available.
Unsupervised Local Discrimination for Medical Images
Aug 21, 2021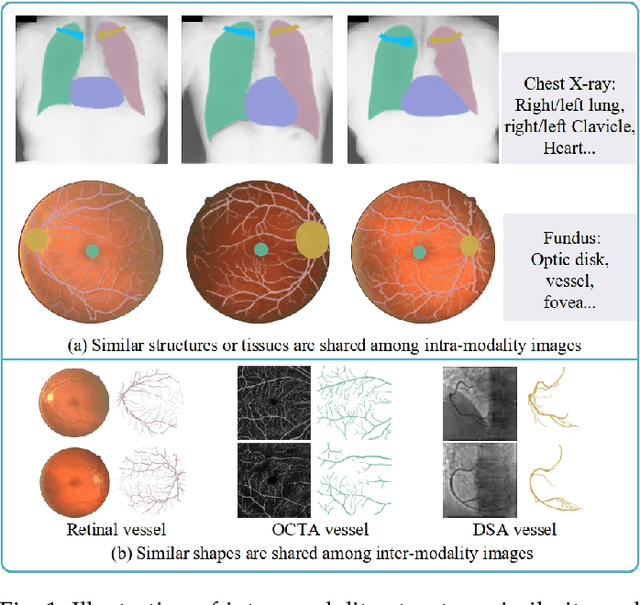
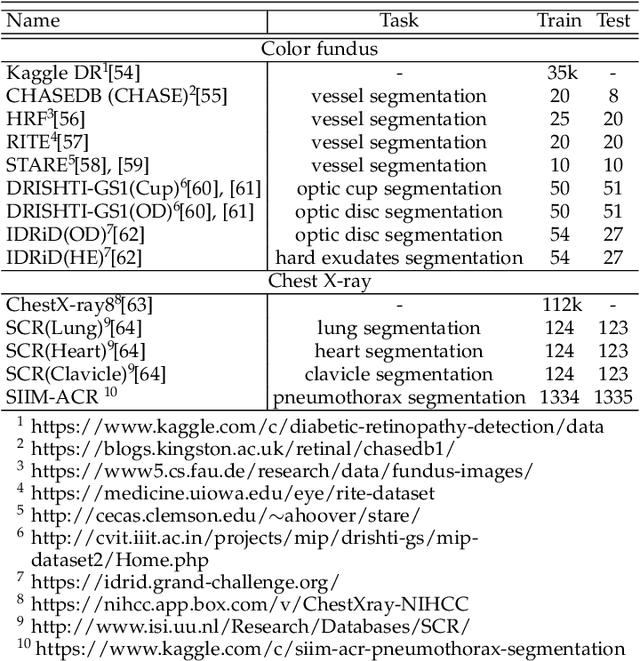

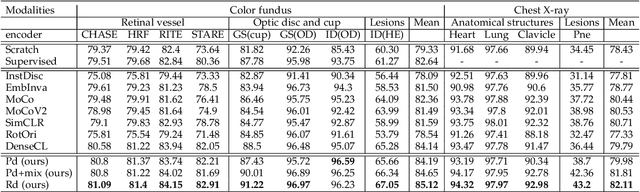
Contrastive representation learning is an effective unsupervised method to alleviate the demand for expensive annotated data in medical image processing. Recent work mainly based on instance-wise discrimination to learn global features, while neglect local details, which limit their application in processing tiny anatomical structures, tissues and lesions. Therefore, we aim to propose a universal local discrmination framework to learn local discriminative features to effectively initialize medical models, meanwhile, we systematacially investigate its practical medical applications. Specifically, based on the common property of intra-modality structure similarity, i.e. similar structures are shared among the same modality images, a systematic local feature learning framework is proposed. Instead of making instance-wise comparisons based on global embedding, our method makes pixel-wise embedding and focuses on measuring similarity among patches and regions. The finer contrastive rule makes the learnt representation more generalized for segmentation tasks and outperform extensive state-of-the-art methods by wining 11 out of all 12 downstream tasks in color fundus and chest X-ray. Furthermore, based on the property of inter-modality shape similarity, i.e. structures may share similar shape although in different medical modalities, we joint across-modality shape prior into region discrimination to realize unsupervised segmentation. It shows the feaibility of segmenting target only based on shape description from other modalities and inner pattern similarity provided by region discrimination. Finally, we enhance the center-sensitive ability of patch discrimination by introducing center-sensitive averaging to realize one-shot landmark localization, this is an effective application for patch discrimination.
Residual Moment Loss for Medical Image Segmentation
Jun 27, 2021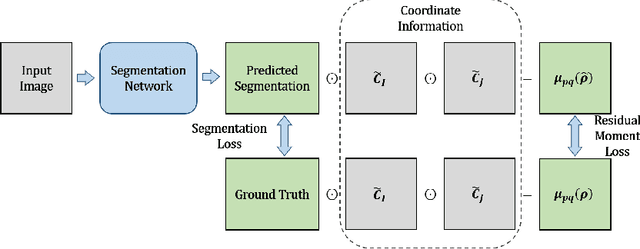



Location information is proven to benefit the deep learning models on capturing the manifold structure of target objects, and accordingly boosts the accuracy of medical image segmentation. However, most existing methods encode the location information in an implicit way, e.g. the distance transform maps, which describe the relative distance from each pixel to the contour boundary, for the network to learn. These implicit approaches do not fully exploit the position information (i.e. absolute location) of targets. In this paper, we propose a novel loss function, namely residual moment (RM) loss, to explicitly embed the location information of segmentation targets during the training of deep learning networks. Particularly, motivated by image moments, the segmentation prediction map and ground-truth map are weighted by coordinate information. Then our RM loss encourages the networks to maintain the consistency between the two weighted maps, which promotes the segmentation networks to easily locate the targets and extract manifold-structure-related features. We validate the proposed RM loss by conducting extensive experiments on two publicly available datasets, i.e., 2D optic cup and disk segmentation and 3D left atrial segmentation. The experimental results demonstrate the effectiveness of our RM loss, which significantly boosts the accuracy of segmentation networks.
Unsupervised Learning of Local Discriminative Representation for Medical Images
Dec 17, 2020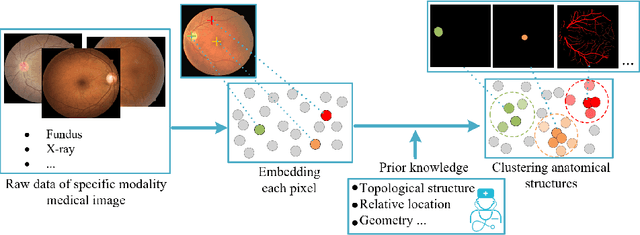
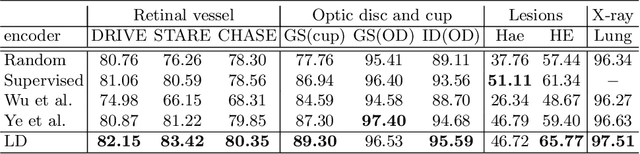
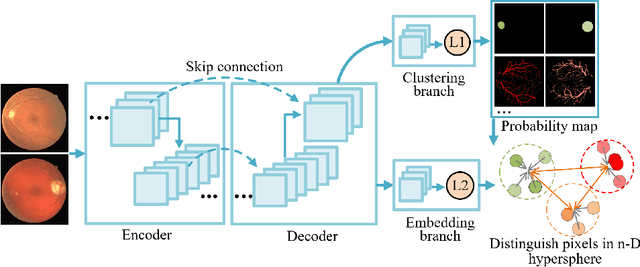
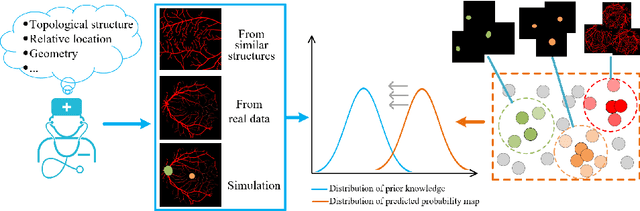
Local discriminative representation is needed in many medical image analysis tasks such as identifying sub-types of lesion or segmenting detailed components of anatomical structures by measuring similarity of local image regions. However, the commonly applied supervised representation learning methods require a large amount of annotated data, and unsupervised discriminative representation learning distinguishes different images by learning a global feature. In order to avoid the limitations of these two methods and be suitable for localized medical image analysis tasks, we introduce local discrimination into unsupervised representation learning in this work. The model contains two branches: one is an embedding branch which learns an embedding function to disperse dissimilar pixels over a low-dimensional hypersphere; and the other is a clustering branch which learns a clustering function to classify similar pixels into the same cluster. These two branches are trained simultaneously in a mutually beneficial pattern, and the learnt local discriminative representations are able to well measure the similarity of local image regions. These representations can be transferred to enhance various downstream tasks. Meanwhile, they can also be applied to cluster anatomical structures from unlabeled medical images under the guidance of topological priors from simulation or other structures with similar topological characteristics. The effectiveness and usefulness of the proposed method are demonstrated by enhancing various downstream tasks and clustering anatomical structures in retinal images and chest X-ray images. The corresponding code is available at https://github.com/HuaiChen-1994/LDLearning.