 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Experience Replay: Continual Learning by Adaptively Tuning Task-wise Relationship
Paper and Code
Jan 06, 2022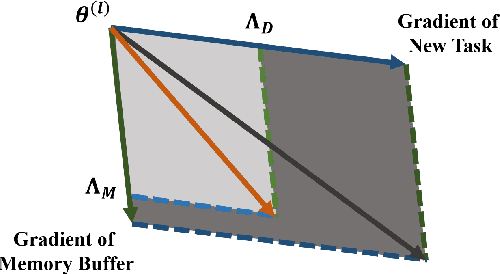
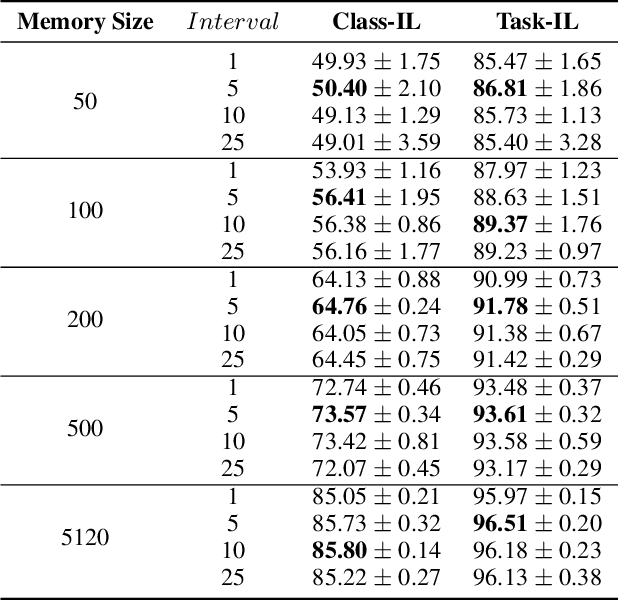

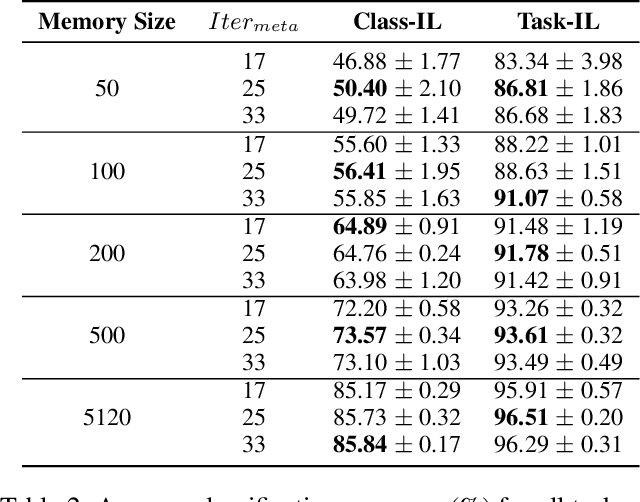
Continual learning requires models to learn new tasks while maintaining previously learned knowledge. Various algorithms have been proposed to address this real challenge. Till now, rehearsal-based methods, such as experience replay, have achieved state-of-the-art performance. These approaches save a small part of the data of the past tasks as a memory buffer to prevent models from forgetting previously learned knowledge. However, most of them treat every new task equally, i.e., fixed the hyperparameters of the framework while learning different new tasks. Such a setting lacks the consideration of the relationship/similarity between past and new tasks. For example, the previous knowledge/features learned from dogs are more beneficial for the identification of cats (new task), compared to those learned from buses. In this regard, we propose a meta learning algorithm based on bi-level optimization to adaptively tune the relationship between the knowledge extracted from the past and new tasks. Therefore, the model can find an appropriate direction of gradient during continual learning and avoid the serious overfitting problem on memory buffer. Extensive experiments are conducted on three publicly available datasets (i.e., CIFAR-10, CIFAR-100, and Tiny ImageNet). The experimental results demonstrate that the proposed method can consistently improve the performance of all baselines.