 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-CBA: Improving Online Continual Learning via Dual Continual Bias Adaptors from a Bi-level Optimization Perspective
Aug 26, 2024



In online continual learning (CL), models trained on changing distributions easily forget previously learned knowledge and bias toward newly received tasks. To address this issue, we present Continual Bias Adaptor (CBA), a bi-level framework that augments the classification network to adapt to catastrophic distribution shifts during training, enabling the network to achieve a stable consolidation of all seen tasks. However, the CBA module adjusts distribution shifts in a class-specific manner, exacerbating the stability gap issue and, to some extent, fails to meet the need for continual testing in online CL. To mitigate this challenge, we further propose a novel class-agnostic CBA module that separately aggregates the posterior probabilities of classes from new and old tasks, and applies a stable adjustment to the resulting posterior probabilities. We combine the two kinds of CBA modules into a unified Dual-CBA module, which thus is capable of adapting to catastrophic distribution shifts and simultaneously meets the real-time testing requirements of online CL. Besides, we propose Incremental Batch Normalization (IBN), a tailored BN module to re-estimate its population statistics for alleviating the feature bias arising from the inner loop optimization problem of our bi-level framework. To validate the effectiveness of the proposed method, we theoretically provide some insights into how it mitigates catastrophic distribution shifts, and empirically demonstrate its superiority through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
CBA: Improving Online Continual Learning via Continual Bias Adaptor
Aug 14, 2023



Online continual learning (CL) aims to learn new knowledge and consolidate previously learned knowledge from non-stationary data streams. Due to the time-varying training setting, the model learned from a changing distribution easily forgets the previously learned knowledge and biases toward the newly received task. To address this problem, we propose a Continual Bias Adaptor (CBA) module to augment the classifier network to adapt to catastrophic distribution change during training, such that the classifier network is able to learn a stable consolidation of previously learned tasks. In the testing stage, CBA can be removed which introduces no additional computation cost and memory overhead. We theoretically reveal the reason why the proposed method can effectively alleviate catastrophic distribution shifts, and empirically demonstrate its effectiveness through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
Learning to Adapt Classifier for Imbalanced Semi-supervised Learning
Jul 28, 2022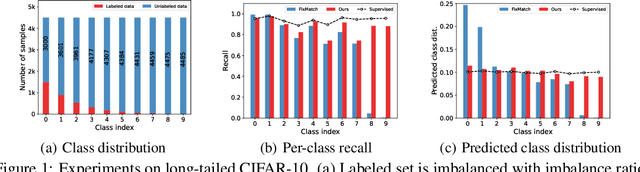
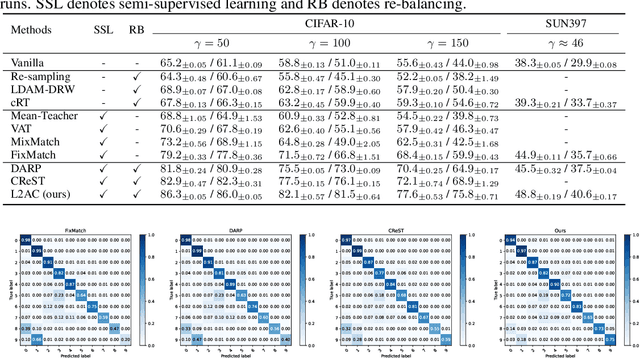
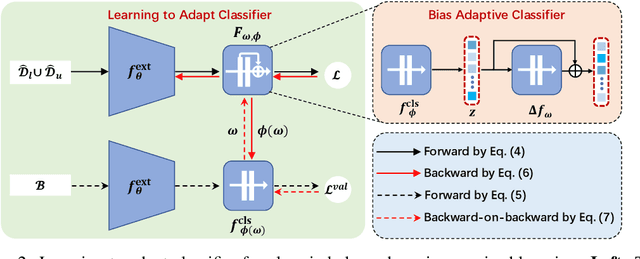
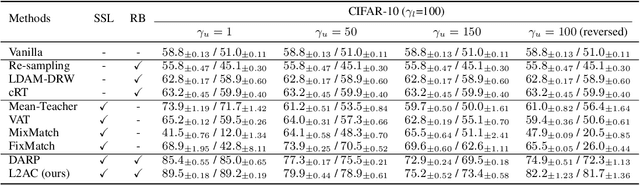
Pseudo-labeling has proven to be a promising semi-supervised learning (SSL) paradigm. Existing pseudo-labeling methods commonly assume that the class distributions of training data are balanced. However, such an assumption is far from realistic scenarios and existing pseudo-labeling methods suffer from severe performance degeneration in the context of class-imbalance. In this work, we investigate pseudo-labeling under imbalanced semi-supervised setups. The core idea is to automatically assimilate the training bias arising from class-imbalance, using a bias adaptive classifier that equips the original linear classifier with a bias attractor. The bias attractor is designed to be a light-weight residual network for adapting to the training bias. Specifically, the bias attractor is learned through a bi-level learning framework such that the bias adaptive classifier is able to fit imbalanced training data, while the linear classifier can give unbiased label prediction for each class. We conduct extensive experiments under various imbalanced semi-supervised setups, and the results demonstrate that our method can be applicable to different pseudo-labeling models and superior to the prior arts.
Label Hierarchy Transition: Modeling Class Hierarchies to Enhance Deep Classifiers
Dec 04, 2021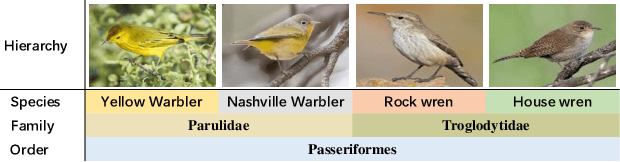
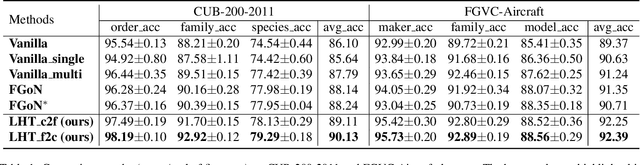
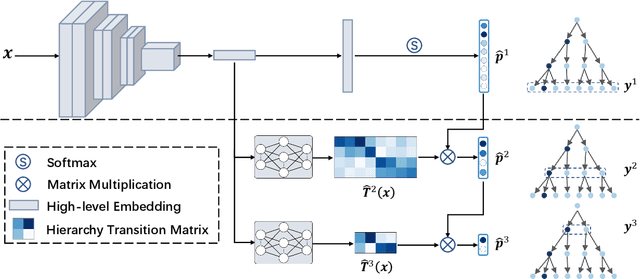
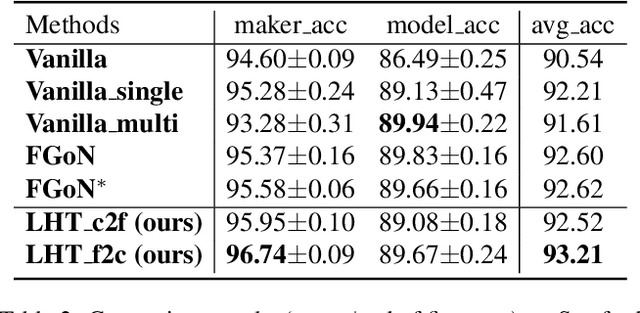
Hierarchical classification aims to sort the object into a hierarchy of categories. For example, a bird can be categorized according to a three-level hierarchy of order, family, and species. Existing methods commonly address hierarchical classification by decoupling it into several multi-class classification tasks. However, such a multi-task learning strategy fails to fully exploit the correlation among various categories across different hierarchies. In this paper, we propose Label Hierarchy Transition, a unified probabilistic framework based on deep learning, to address hierarchical classification. Specifically, we explicitly learn the label hierarchy transition matrices, whose column vectors represent the conditional label distributions of classes between two adjacent hierarchies and could be capable of encoding the correlation embedded in class hierarchies. We further propose a confusion loss, which encourages the classification network to learn the correlation across different label hierarchies during training. The proposed framework can be adapted to any existing deep network with only minor modifications. We experiment with three public benchmark datasets with various class hierarchies, and the results demonstrate the superiority of our approach beyond the prior arts. Source code will be made publicly available.
A Benchmark for Edge-Preserving Image Smoothing
Apr 02, 2019



Edge-preserving image smoothing is an important step for many low-level vision problems. Though many algorithms have been proposed, there are several difficulties hindering its further development. First, most existing algorithms cannot perform well on a wide range of image contents using a single parameter setting. Second, the performance evaluation of edge-preserving image smoothing remains subjective, and there lacks a widely accepted datasets to objectively compare the different algorithms. To address these issues and further advance the state of the art, in this work we propose a benchmark for edge-preserving image smoothing. This benchmark includes an image dataset with groundtruth image smoothing results as well as baseline algorithms that can generate competitive edge-preserving smoothing results for a wide range of image contents. The established dataset contains 500 training and testing images with a number of representative visual object categories, while the baseline methods in our benchmark are built upon representative deep convolutional network architectures, on top of which we design novel loss functions well suited for edge-preserving image smoothing. The trained deep networks run faster than most state-of-the-art smoothing algorithms with leading smoothing results both qualitatively and quantitatively. The benchmark is publicly accessible via https://github.com/zhufeida/Benchmark_EPS.