 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Chinese-English Scene Text Image Super-resolution
Aug 07, 2023

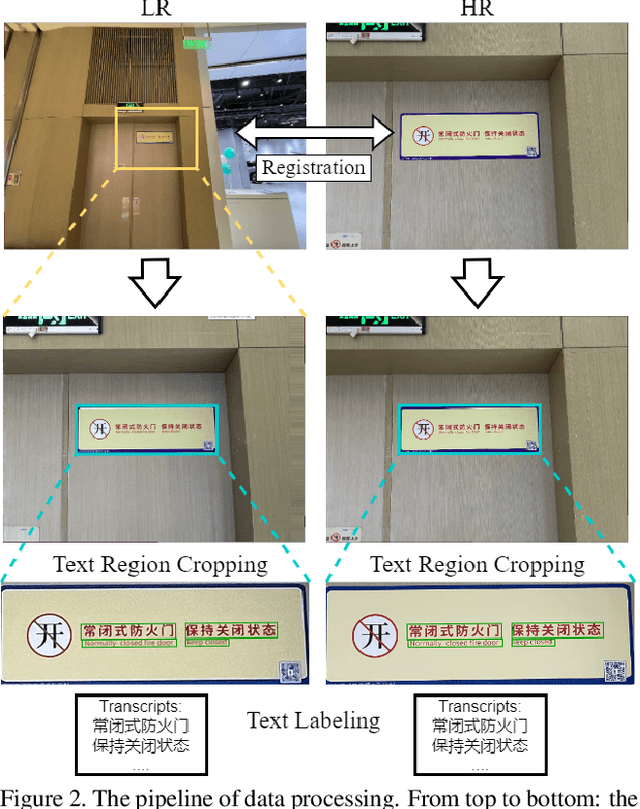

Scene Text Image Super-resolution (STISR) aims to recover high-resolution (HR) scene text images with visually pleasant and readable text content from the given low-resolution (LR) input. Most existing works focus on recovering English texts, which have relatively simple character structures, while little work has been done on the more challenging Chinese texts with diverse and complex character structures. In this paper, we propose a real-world Chinese-English benchmark dataset, namely Real-CE, for the task of STISR with the emphasis on restoring structurally complex Chinese characters. The benchmark provides 1,935/783 real-world LR-HR text image pairs~(contains 33,789 text lines in total) for training/testing in 2$\times$ and 4$\times$ zooming modes, complemented by detailed annotations, including detection boxes and text transcripts. Moreover, we design an edge-aware learning method, which provides structural supervision in image and feature domains, to effectively reconstruct the dense structures of Chinese characters. We conduct experiments on the proposed Real-CE benchmark and evaluate the existing STISR models with and without our edge-aware loss. The benchmark, including data and source code, is available at https://github.com/mjq11302010044/Real-CE.
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution
Mar 18, 2022
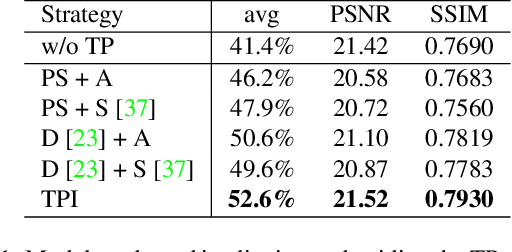
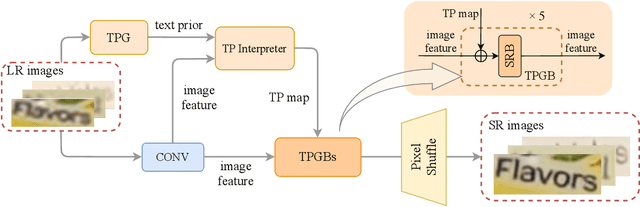
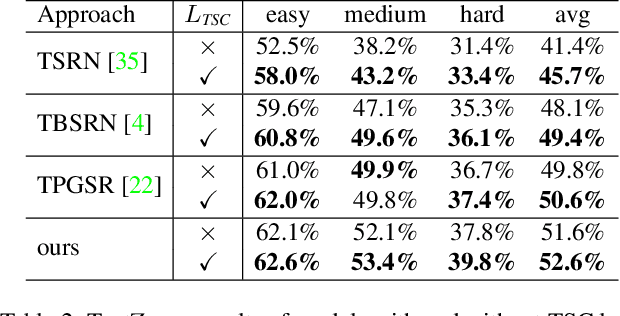
Scene text image super-resolution aims to increase the resolution and readability of the text in low-resolution images. Though significant improvement has been achieved by deep convolutional neural networks (CNNs), it remains difficult to reconstruct high-resolution images for spatially deformed texts, especially rotated and curve-shaped ones. This is because the current CNN-based methods adopt locality-based operations, which are not effective to deal with the variation caused by deformations. In this paper, we propose a CNN based Text ATTention network (TATT) to address this problem. The semantics of the text are firstly extracted by a text recognition module as text prior information. Then we design a novel transformer-based module, which leverages global attention mechanism, to exert the semantic guidance of text prior to the text reconstruction process. In addition, we propose a text structure consistency loss to refine the visual appearance by imposing structural consistency on the reconstructions of regular and deformed texts. Experiments on the benchmark TextZoom dataset show that the proposed TATT not only achieves state-of-the-art performance in terms of PSNR/SSIM metrics, but also significantly improves the recognition accuracy in the downstream text recognition task, particularly for text instances with multi-orientation and curved shapes. Code is available at https://github.com/mjq11302010044/TATT.
HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset
Mar 27, 2021

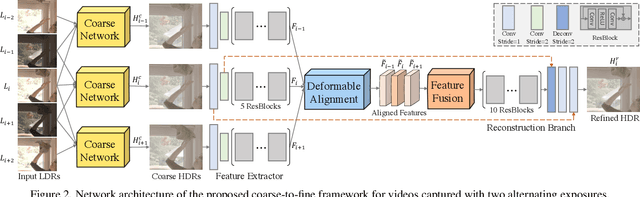
High dynamic range (HDR) video reconstruction from sequences captured with alternating exposures is a very challenging problem. Existing methods often align low dynamic range (LDR) input sequence in the image space using optical flow, and then merge the aligned images to produce HDR output. However, accurate alignment and fusion in the image space are difficult due to the missing details in the over-exposed regions and noise in the under-exposed regions, resulting in unpleasing ghosting artifacts. To enable more accurate alignment and HDR fusion, we introduce a coarse-to-fine deep learning framework for HDR video reconstruction. Firstly, we perform coarse alignment and pixel blending in the image space to estimate the coarse HDR video. Secondly, we conduct more sophisticated alignment and temporal fusion in the feature space of the coarse HDR video to produce better reconstruction. Considering the fact that there is no publicly available dataset for quantitative and comprehensive evaluation of HDR video reconstruction methods, we collect such a benchmark dataset, which contains $97$ sequences of static scenes and 184 testing pairs of dynamic scenes. Extensive experiments show that our method outperforms previous state-of-the-art methods. Our dataset, code and model will be made publicly available.
Joint Denoising and Demosaicking with Green Channel Prior for Real-world Burst Images
Jan 25, 2021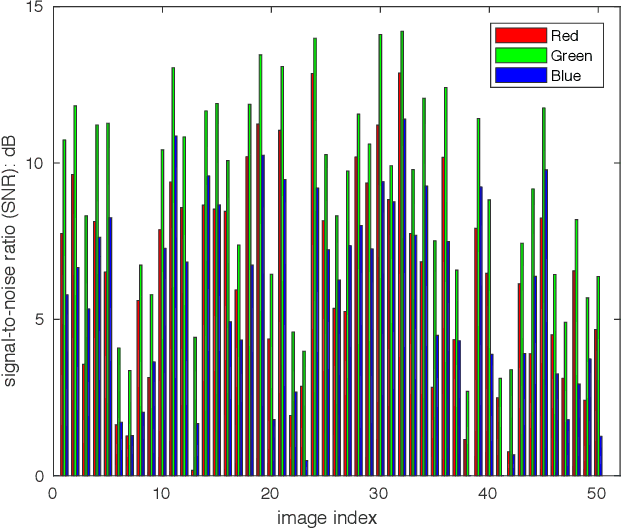


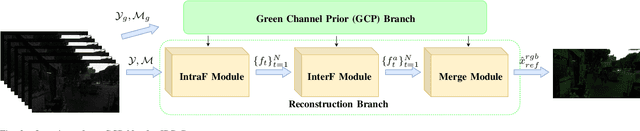
Denoising and demosaicking are essential yet correlated steps to reconstruct a full color image from the raw color filter array (CFA) data. By learning a deep convolutional neural network (CNN), significant progress has been achieved to perform denoising and demosaicking jointly. However, most existing CNN-based joint denoising and demosaicking (JDD) methods work on a single image while assuming additive white Gaussian noise, which limits their performance on real-world applications. In this work, we study the JDD problem for real-world burst images, namely JDD-B. Considering the fact that the green channel has twice the sampling rate and better quality than the red and blue channels in CFA raw data, we propose to use this green channel prior (GCP) to build a GCP-Net for the JDD-B task. In GCP-Net, the GCP features extracted from green channels are utilized to guide the feature extraction and feature upsampling of the whole image. To compensate for the shift between frames, the offset is also estimated from GCP features to reduce the impact of noise. Our GCP-Net can preserve more image structures and details than other JDD methods while removing noise. Experiments on synthetic and real-world noisy images demonstrate the effectiveness of GCP-Net quantitatively and qualitatively.
CameraNet: A Two-Stage Framework for Effective Camera ISP Learning
Aug 08, 2019



Traditional image signal processing (ISP) pipeline consists of a set of individual image processing components onboard a camera to reconstruct a high-quality sRGB image from the sensor raw data. Due to the hand-crafted nature of the ISP components, traditional ISP pipeline has limited reconstruction quality under challenging scenes. Recently, the convolutional neural networks (CNNs) have demonstrated their competitiveness in solving many individual image processing problems, such as image denoising, demosaicking, white balance and contrast enhancement. However, it remains a question whether a CNN model can address the multiple tasks inside an ISP pipeline simultaneously. We make a good attempt along this line and propose a novel framework, which we call CameraNet, for effective and general ISP pipeline learning. The CameraNet is composed of two CNN modules to account for two sets of relatively uncorrelated subtasks in an ISP pipeline: restoration and enhancement. To train the two-stage CameraNet model, we specify two groundtruths that can be easily created in the common workflow of photography. CameraNet is trained to progressively address the restoration and the enhancement subtasks with its two modules. Experiments show that the proposed CameraNet achieves consistently compelling reconstruction quality on three benchmark datasets and outperforms traditional ISP pipelines.
A Benchmark for Edge-Preserving Image Smoothing
Apr 02, 2019



Edge-preserving image smoothing is an important step for many low-level vision problems. Though many algorithms have been proposed, there are several difficulties hindering its further development. First, most existing algorithms cannot perform well on a wide range of image contents using a single parameter setting. Second, the performance evaluation of edge-preserving image smoothing remains subjective, and there lacks a widely accepted datasets to objectively compare the different algorithms. To address these issues and further advance the state of the art, in this work we propose a benchmark for edge-preserving image smoothing. This benchmark includes an image dataset with groundtruth image smoothing results as well as baseline algorithms that can generate competitive edge-preserving smoothing results for a wide range of image contents. The established dataset contains 500 training and testing images with a number of representative visual object categories, while the baseline methods in our benchmark are built upon representative deep convolutional network architectures, on top of which we design novel loss functions well suited for edge-preserving image smoothing. The trained deep networks run faster than most state-of-the-art smoothing algorithms with leading smoothing results both qualitatively and quantitatively. The benchmark is publicly accessible via https://github.com/zhufeida/Benchmark_EPS.
Real-world Noisy Image Denoising: A New Benchmark
Apr 07, 2018



Most of previous image denoising methods focus on additive white Gaussian noise (AWGN). However,the real-world noisy image denoising problem with the advancing of the computer vision techiniques. In order to promote the study on this problem while implementing the concurrent real-world image denoising datasets, we construct a new benchmark dataset which contains comprehensive real-world noisy images of different natural scenes. These images are captured by different cameras under different camera settings. We evaluate the different denoising methods on our new dataset as well as previous datasets. Extensive experimental results demonstrate that the recently proposed methods designed specifically for realistic noise removal based on sparse or low rank theories achieve better denoising performance and are more robust than other competing methods, and the newly proposed dataset is more challenging. The constructed dataset of real photographs is publicly available at \url{https://github.com/csjunxu/PolyUDataset} for researchers to investigate new real-world image denoising methods. We will add more analysis on the noise statistics in the real photographs of our new dataset in the next version of this article.