 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
InstructRestore: Region-Customized Image Restoration with Human Instructions
Mar 31, 2025



Despite the significant progress in diffusion prior-based image restoration, most existing methods apply uniform processing to the entire image, lacking the capability to perform region-customized image restoration according to user instructions. In this work, we propose a new framework, namely InstructRestore, to perform region-adjustable image restoration following human instructions. To achieve this, we first develop a data generation engine to produce training triplets, each consisting of a high-quality image, the target region description, and the corresponding region mask. With this engine and careful data screening, we construct a comprehensive dataset comprising 536,945 triplets to support the training and evaluation of this task. We then examine how to integrate the low-quality image features under the ControlNet architecture to adjust the degree of image details enhancement. Consequently, we develop a ControlNet-like model to identify the target region and allocate different integration scales to the target and surrounding regions, enabling region-customized image restoration that aligns with user instructions. Experimental results demonstrate that our proposed InstructRestore approach enables effective human-instructed image restoration, such as images with bokeh effects and user-instructed local enhancement. Our work advances the investigation of interactive image restoration and enhancement techniques. Data, code, and models will be found at https://github.com/shuaizhengliu/InstructRestore.git.
Toward Accurate and Temporally Consistent Video Restoration from Raw Data
Dec 25, 2023Denoising and demosaicking are two fundamental steps in reconstructing a clean full-color video from raw data, while performing video denoising and demosaicking jointly, namely VJDD, could lead to better video restoration performance than performing them separately. In addition to restoration accuracy, another key challenge to VJDD lies in the temporal consistency of consecutive frames. This issue exacerbates when perceptual regularization terms are introduced to enhance video perceptual quality. To address these challenges, we present a new VJDD framework by consistent and accurate latent space propagation, which leverages the estimation of previous frames as prior knowledge to ensure consistent recovery of the current frame. A data temporal consistency (DTC) loss and a relational perception consistency (RPC) loss are accordingly designed. Compared with the commonly used flow-based losses, the proposed losses can circumvent the error accumulation problem caused by inaccurate flow estimation and effectively handle intensity changes in videos, improving much the temporal consistency of output videos while preserving texture details. Extensive experiments demonstrate the leading VJDD performance of our method in term of restoration accuracy, perceptual quality and temporal consistency. Codes and dataset are available at \url{https://github.com/GuoShi28/VJDD}.
Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
Dec 01, 2023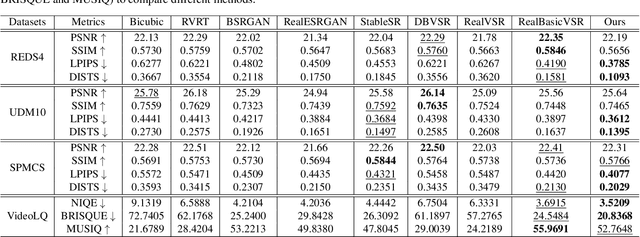
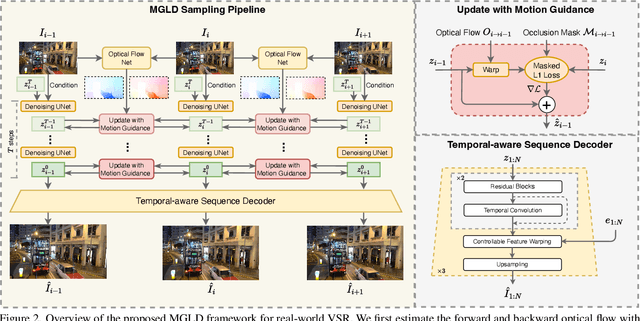


Real-world low-resolution (LR) videos have diverse and complex degradations, imposing great challenges on video super-resolution (VSR) algorithms to reproduce their high-resolution (HR) counterparts with high quality. Recently, the diffusion models have shown compelling performance in generating realistic details for image restoration tasks. However, the diffusion process has randomness, making it hard to control the contents of restored images. This issue becomes more serious when applying diffusion models to VSR tasks because temporal consistency is crucial to the perceptual quality of videos. In this paper, we propose an effective real-world VSR algorithm by leveraging the strength of pre-trained latent diffusion models. To ensure the content consistency among adjacent frames, we exploit the temporal dynamics in LR videos to guide the diffusion process by optimizing the latent sampling path with a motion-guided loss, ensuring that the generated HR video maintains a coherent and continuous visual flow. To further mitigate the discontinuity of generated details, we insert temporal module to the decoder and fine-tune it with an innovative sequence-oriented loss. The proposed motion-guided latent diffusion (MGLD) based VSR algorithm achieves significantly better perceptual quality than state-of-the-arts on real-world VSR benchmark datasets, validating the effectiveness of the proposed model design and training strategies.
A Benchmark for Chinese-English Scene Text Image Super-resolution
Aug 07, 2023

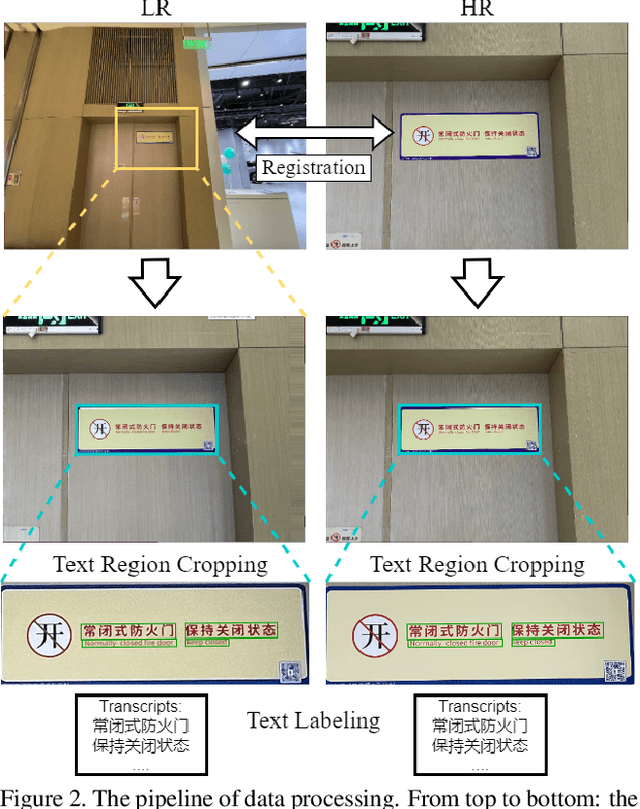

Scene Text Image Super-resolution (STISR) aims to recover high-resolution (HR) scene text images with visually pleasant and readable text content from the given low-resolution (LR) input. Most existing works focus on recovering English texts, which have relatively simple character structures, while little work has been done on the more challenging Chinese texts with diverse and complex character structures. In this paper, we propose a real-world Chinese-English benchmark dataset, namely Real-CE, for the task of STISR with the emphasis on restoring structurally complex Chinese characters. The benchmark provides 1,935/783 real-world LR-HR text image pairs~(contains 33,789 text lines in total) for training/testing in 2$\times$ and 4$\times$ zooming modes, complemented by detailed annotations, including detection boxes and text transcripts. Moreover, we design an edge-aware learning method, which provides structural supervision in image and feature domains, to effectively reconstruct the dense structures of Chinese characters. We conduct experiments on the proposed Real-CE benchmark and evaluate the existing STISR models with and without our edge-aware loss. The benchmark, including data and source code, is available at https://github.com/mjq11302010044/Real-CE.
Spatial-Frequency Attention for Image Denoising
Feb 27, 2023The recently developed transformer networks have achieved impressive performance in image denoising by exploiting the self-attention (SA) in images. However, the existing methods mostly use a relatively small window to compute SA due to the quadratic complexity of it, which limits the model's ability to model long-term image information. In this paper, we propose the spatial-frequency attention network (SFANet) to enhance the network's ability in exploiting long-range dependency. For spatial attention module (SAM), we adopt dilated SA to model long-range dependency. In the frequency attention module (FAM), we exploit more global information by using Fast Fourier Transform (FFT) by designing a window-based frequency channel attention (WFCA) block to effectively model deep frequency features and their dependencies. To make our module applicable to images of different sizes and keep the model consistency between training and inference, we apply window-based FFT with a set of fixed window sizes. In addition, channel attention is computed on both real and imaginary parts of the Fourier spectrum, which further improves restoration performance. The proposed WFCA block can effectively model image long-range dependency with acceptable complexity. Experiments on multiple denoising benchmarks demonstrate the leading performance of SFANet network.
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution
Mar 18, 2022
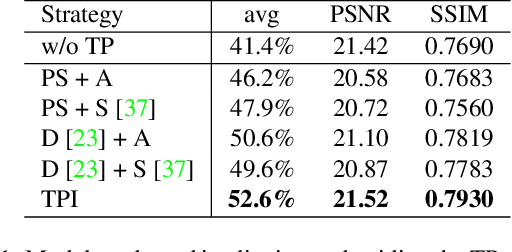
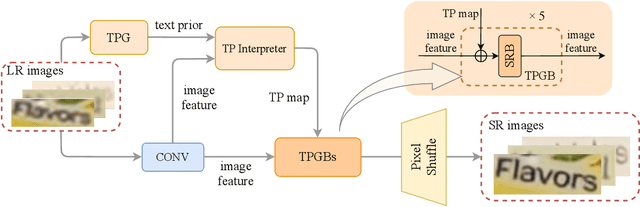
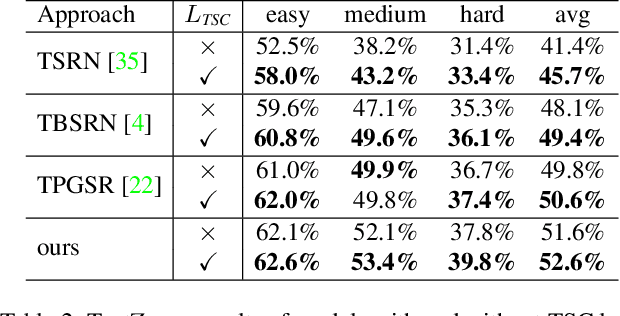
Scene text image super-resolution aims to increase the resolution and readability of the text in low-resolution images. Though significant improvement has been achieved by deep convolutional neural networks (CNNs), it remains difficult to reconstruct high-resolution images for spatially deformed texts, especially rotated and curve-shaped ones. This is because the current CNN-based methods adopt locality-based operations, which are not effective to deal with the variation caused by deformations. In this paper, we propose a CNN based Text ATTention network (TATT) to address this problem. The semantics of the text are firstly extracted by a text recognition module as text prior information. Then we design a novel transformer-based module, which leverages global attention mechanism, to exert the semantic guidance of text prior to the text reconstruction process. In addition, we propose a text structure consistency loss to refine the visual appearance by imposing structural consistency on the reconstructions of regular and deformed texts. Experiments on the benchmark TextZoom dataset show that the proposed TATT not only achieves state-of-the-art performance in terms of PSNR/SSIM metrics, but also significantly improves the recognition accuracy in the downstream text recognition task, particularly for text instances with multi-orientation and curved shapes. Code is available at https://github.com/mjq11302010044/TATT.
A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift
Mar 17, 2022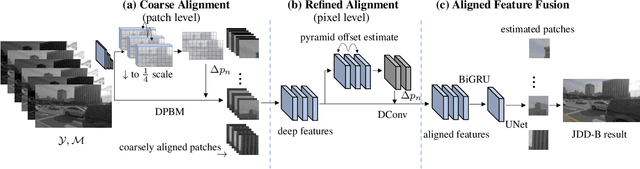


Denoising and demosaicking are two essential steps to reconstruct a clean full-color image from the raw data. Recently, joint denoising and demosaicking (JDD) for burst images, namely JDD-B, has attracted much attention by using multiple raw images captured in a short time to reconstruct a single high-quality image. One key challenge of JDD-B lies in the robust alignment of image frames. State-of-the-art alignment methods in feature domain cannot effectively utilize the temporal information of burst images, where large shifts commonly exist due to camera and object motion. In addition, the higher resolution (e.g., 4K) of modern imaging devices results in larger displacement between frames. To address these challenges, we design a differentiable two-stage alignment scheme sequentially in patch and pixel level for effective JDD-B. The input burst images are firstly aligned in the patch level by using a differentiable progressive block matching method, which can estimate the offset between distant frames with small computational cost. Then we perform implicit pixel-wise alignment in full-resolution feature domain to refine the alignment results. The two stages are jointly trained in an end-to-end manner. Extensive experiments demonstrate the significant improvement of our method over existing JDD-B methods. Codes are available at https://github.com/GuoShi28/2StageAlign.
Benchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study
Dec 30, 2021


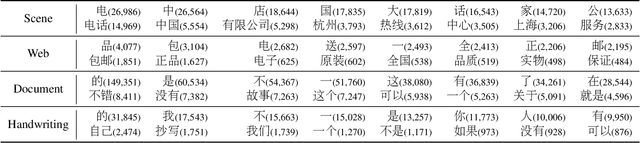
The flourishing blossom of deep learning has witnessed the rapid development of text recognition in recent years. However, the existing text recognition methods are mainly for English texts, whereas ignoring the pivotal role of Chinese texts. As another widely-spoken language, Chinese text recognition in all ways has extensive application markets. Based on our observations, we attribute the scarce attention on Chinese text recognition to the lack of reasonable dataset construction standards, unified evaluation methods, and results of the existing baselines. To fill this gap, we manually collect Chinese text datasets from publicly available competitions, projects, and papers, then divide them into four categories including scene, web, document, and handwriting datasets. Furthermore, we evaluate a series of representative text recognition methods on these datasets with unified evaluation methods to provide experimental results. By analyzing the experimental results, we surprisingly observe that state-of-the-art baselines for recognizing English texts cannot perform well on Chinese scenarios. We consider that there still remain numerous challenges under exploration due to the characteristics of Chinese texts, which are quite different from English texts. The code and datasets are made publicly available at https://github.com/FudanVI/benchmarking-chinese-text-recognition.
Text Gestalt: Stroke-Aware Scene Text Image Super-Resolution
Dec 13, 2021



In the last decade, the blossom of deep learning has witnessed the rapid development of scene text recognition. However, the recognition of low-resolution scene text images remains a challenge. Even though some super-resolution methods have been proposed to tackle this problem, they usually treat text images as general images while ignoring the fact that the visual quality of strokes (the atomic unit of text) plays an essential role for text recognition. According to Gestalt Psychology, humans are capable of composing parts of details into the most similar objects guided by prior knowledge. Likewise, when humans observe a low-resolution text image, they will inherently use partial stroke-level details to recover the appearance of holistic characters. Inspired by Gestalt Psychology, we put forward a Stroke-Aware Scene Text Image Super-Resolution method containing a Stroke-Focused Module (SFM) to concentrate on stroke-level internal structures of characters in text images. Specifically, we attempt to design rules for decomposing English characters and digits at stroke-level, then pre-train a text recognizer to provide stroke-level attention maps as positional clues with the purpose of controlling the consistency between the generated super-resolution image and high-resolution ground truth. The extensive experimental results validate that the proposed method can indeed generate more distinguishable images on TextZoom and manually constructed Chinese character dataset Degraded-IC13. Furthermore, since the proposed SFM is only used to provide stroke-level guidance when training, it will not bring any time overhead during the test phase. Code is available at https://github.com/FudanVI/FudanOCR/tree/main/text-gestalt.