 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study
Dec 30, 2021


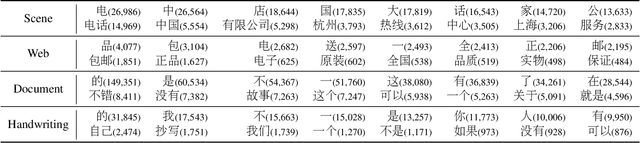
The flourishing blossom of deep learning has witnessed the rapid development of text recognition in recent years. However, the existing text recognition methods are mainly for English texts, whereas ignoring the pivotal role of Chinese texts. As another widely-spoken language, Chinese text recognition in all ways has extensive application markets. Based on our observations, we attribute the scarce attention on Chinese text recognition to the lack of reasonable dataset construction standards, unified evaluation methods, and results of the existing baselines. To fill this gap, we manually collect Chinese text datasets from publicly available competitions, projects, and papers, then divide them into four categories including scene, web, document, and handwriting datasets. Furthermore, we evaluate a series of representative text recognition methods on these datasets with unified evaluation methods to provide experimental results. By analyzing the experimental results, we surprisingly observe that state-of-the-art baselines for recognizing English texts cannot perform well on Chinese scenarios. We consider that there still remain numerous challenges under exploration due to the characteristics of Chinese texts, which are quite different from English texts. The code and datasets are made publicly available at https://github.com/FudanVI/benchmarking-chinese-text-recognition.
MOTS: Multiple Object Tracking for General Categories Based On Few-Shot Method
May 19, 2020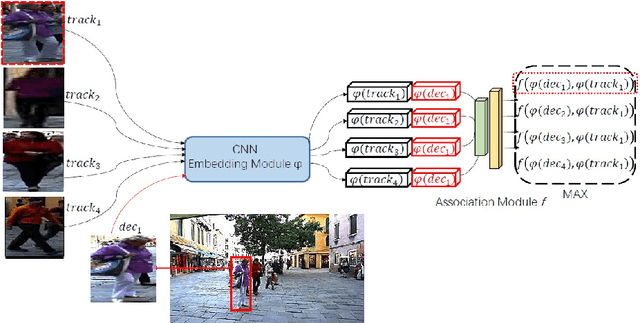
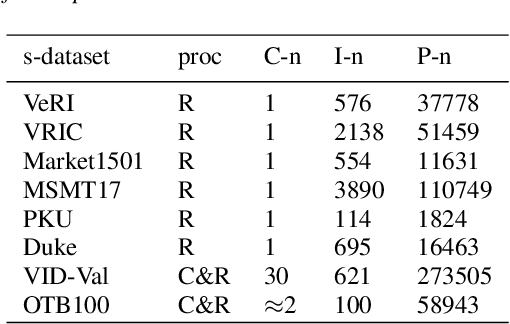
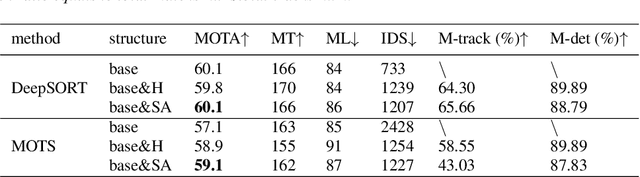

Most modern Multi-Object Tracking (MOT) systems typically apply REID-based paradigm to hold a balance between computational efficiency and performance. In the past few years, numerous attempts have been made to perfect the systems. Although they presented favorable performance, they were constrained to track specified category. Drawing on the ideas of few shot method, we pioneered a new multi-target tracking system, named MOTS, which is based on metrics but not limited to track specific category. It contains two stages in series: In the first stage, we design the self-Adaptive-matching module to perform simple targets matching, which can complete 88.76% assignments without sacrificing performance on MOT16 training set. In the second stage, a Fine-match Network was carefully designed for unmatched targets. With a newly built TRACK-REID data-set, the Fine-match Network can perform matching of 31 category targets, even generalizes to unseen categories.