 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoBEV: Elevating Roadside 3D Object Detection with Depth and Height Complementarity
Oct 18, 2023Roadside camera-driven 3D object detection is a crucial task in intelligent transportation systems, which extends the perception range beyond the limitations of vision-centric vehicles and enhances road safety. While previous studies have limitations in using only depth or height information, we find both depth and height matter and they are in fact complementary. The depth feature encompasses precise geometric cues, whereas the height feature is primarily focused on distinguishing between various categories of height intervals, essentially providing semantic context. This insight motivates the development of Complementary-BEV (CoBEV), a novel end-to-end monocular 3D object detection framework that integrates depth and height to construct robust BEV representations. In essence, CoBEV estimates each pixel's depth and height distribution and lifts the camera features into 3D space for lateral fusion using the newly proposed two-stage complementary feature selection (CFS) module. A BEV feature distillation framework is also seamlessly integrated to further enhance the detection accuracy from the prior knowledge of the fusion-modal CoBEV teacher. We conduct extensive experiments on the public 3D detection benchmarks of roadside camera-based DAIR-V2X-I and Rope3D, as well as the private Supremind-Road dataset, demonstrating that CoBEV not only achieves the accuracy of the new state-of-the-art, but also significantly advances the robustness of previous methods in challenging long-distance scenarios and noisy camera disturbance, and enhances generalization by a large margin in heterologous settings with drastic changes in scene and camera parameters. For the first time, the vehicle AP score of a camera model reaches 80% on DAIR-V2X-I in terms of easy mode. The source code will be made publicly available at https://github.com/MasterHow/CoBEV.
GaitGCI: Generative Counterfactual Intervention for Gait Recognition
Jun 06, 2023

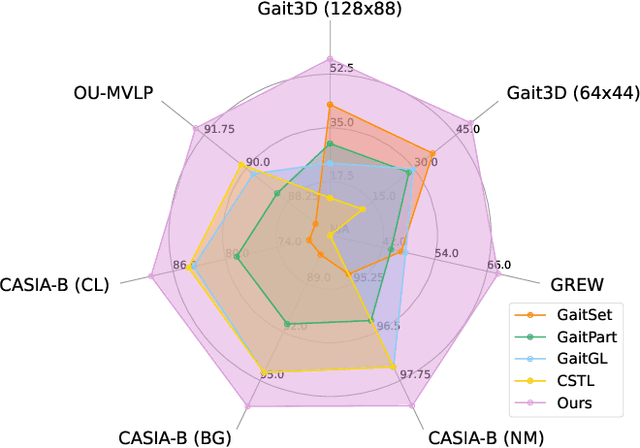
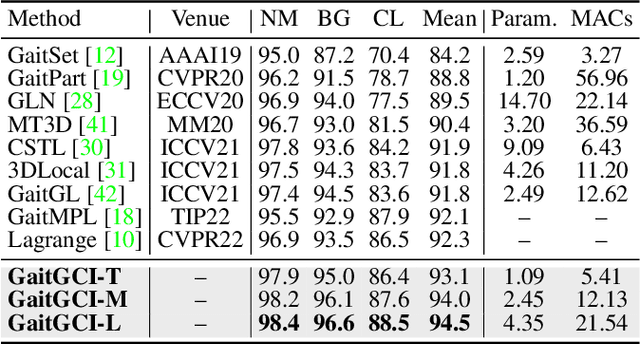
Gait is one of the most promising biometrics that aims to identify pedestrians from their walking patterns. However, prevailing methods are susceptible to confounders, resulting in the networks hardly focusing on the regions that reflect effective walking patterns. To address this fundamental problem in gait recognition, we propose a Generative Counterfactual Intervention framework, dubbed GaitGCI, consisting of Counterfactual Intervention Learning (CIL) and Diversity-Constrained Dynamic Convolution (DCDC). CIL eliminates the impacts of confounders by maximizing the likelihood difference between factual/counterfactual attention while DCDC adaptively generates sample-wise factual/counterfactual attention to efficiently perceive the sample-wise properties. With matrix decomposition and diversity constraint, DCDC guarantees the model to be efficient and effective. Extensive experiments indicate that proposed GaitGCI: 1) could effectively focus on the discriminative and interpretable regions that reflect gait pattern; 2) is model-agnostic and could be plugged into existing models to improve performance with nearly no extra cost; 3) efficiently achieves state-of-the-art performance on arbitrary scenarios (in-the-lab and in-the-wild).
PanoVPR: Towards Unified Perspective-to-Equirectangular Visual Place Recognition via Sliding Windows across the Panoramic View
Mar 24, 2023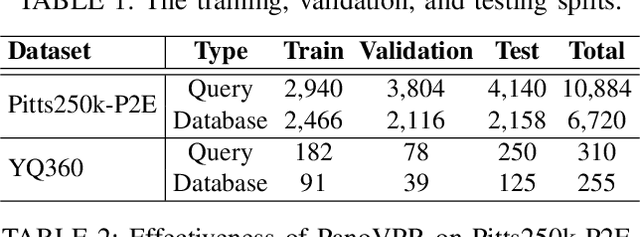
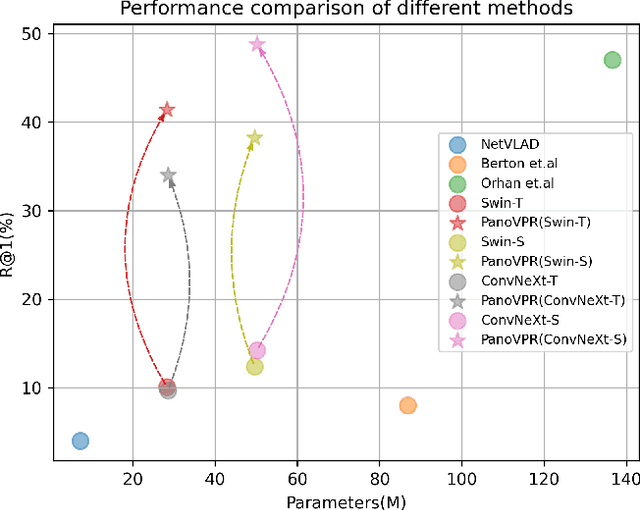
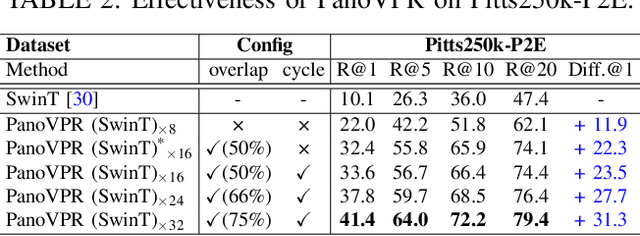
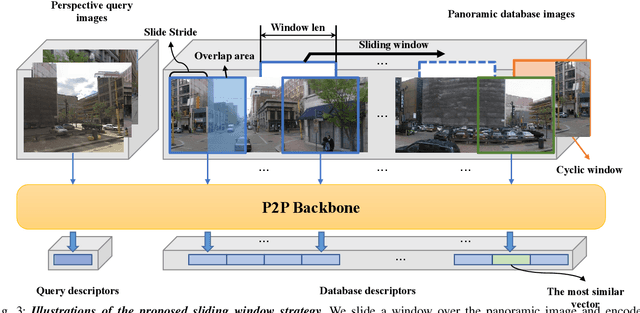
Visual place recognition has received increasing attention in recent years as a key technology in autonomous driving and robotics. The current mainstream approaches use either the perspective view retrieval perspective view (P2P) paradigm or the equirectangular image retrieval equirectangular image (E2E) paradigm. However, a natural and practical idea is that users only have consumer-grade pinhole cameras to obtain query perspective images and retrieve them in panoramic database images from map providers. To this end, we propose PanoVPR, a sliding-window-based perspective-to-equirectangular (P2E) visual place recognition framework, which eliminates feature truncation caused by hard cropping by sliding windows over the whole equirectangular image and computing and comparing feature descriptors between windows. In addition, this unified framework allows for directly transferring the network structure used in perspective-to-perspective (P2P) methods without modification. To facilitate training and evaluation, we derive the pitts250k-P2E dataset from the pitts250k and achieve promising results, and we also establish a P2E dataset in a real-world scenario by a mobile robot platform, which we refer to YQ360. Code and datasets will be made available at https://github.com/zafirshi/PanoVPR.
MOTS: Multiple Object Tracking for General Categories Based On Few-Shot Method
May 19, 2020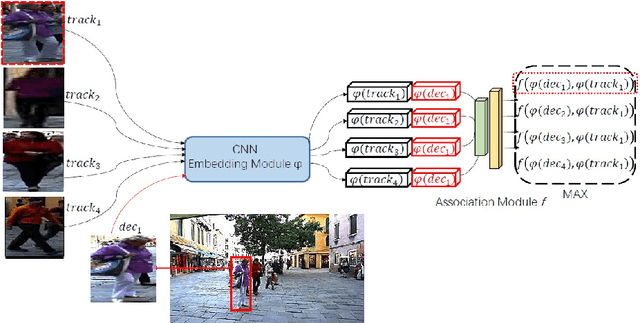
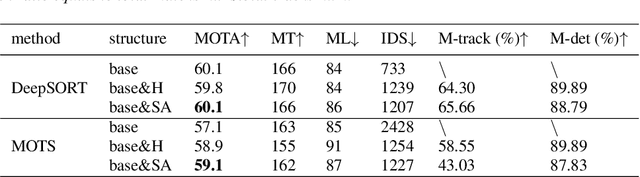

Most modern Multi-Object Tracking (MOT) systems typically apply REID-based paradigm to hold a balance between computational efficiency and performance. In the past few years, numerous attempts have been made to perfect the systems. Although they presented favorable performance, they were constrained to track specified category. Drawing on the ideas of few shot method, we pioneered a new multi-target tracking system, named MOTS, which is based on metrics but not limited to track specific category. It contains two stages in series: In the first stage, we design the self-Adaptive-matching module to perform simple targets matching, which can complete 88.76% assignments without sacrificing performance on MOT16 training set. In the second stage, a Fine-match Network was carefully designed for unmatched targets. With a newly built TRACK-REID data-set, the Fine-match Network can perform matching of 31 category targets, even generalizes to unseen categories.
Dual Path Multi-Scale Fusion Networks with Attention for Crowd Counting
Feb 04, 2019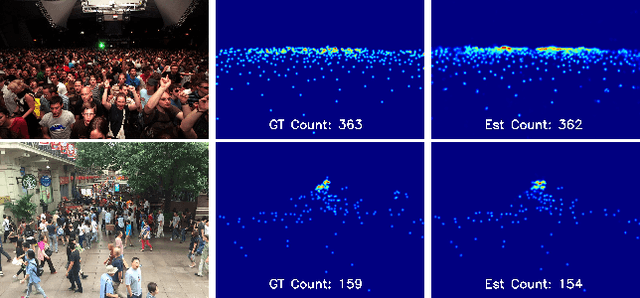
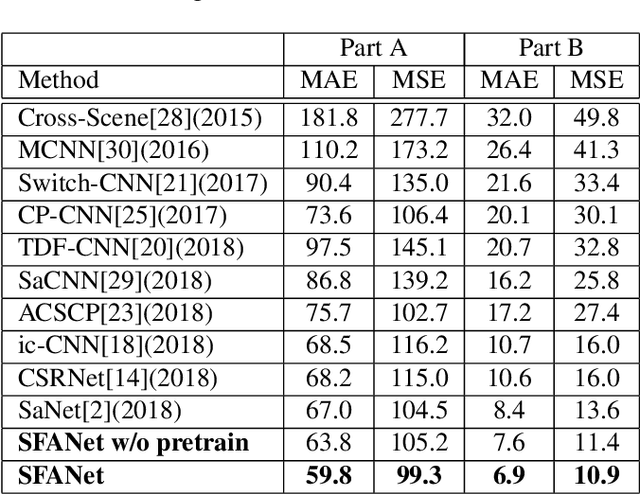
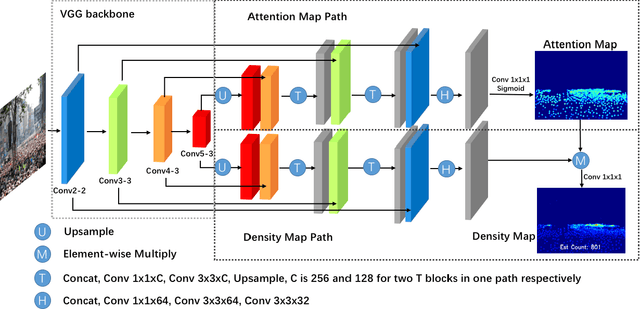
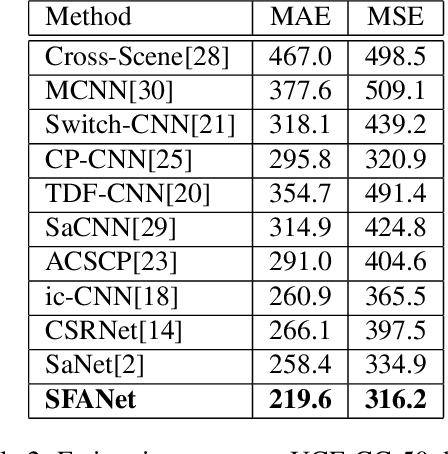
The task of crowd counting in varying density scenes is an extremely difficult challenge due to large scale variations. In this paper, we propose a novel dual path multi-scale fusion network architecture with attention mechanism named SFANet that can perform accurate count estimation as well as present high-resolution density maps for highly congested crowd scenes. The proposed SFANet contains two main components: a VGG backbone convolutional neural network (CNN) as the front-end feature map extractor and a dual path multi-scale fusion networks as the back-end to generate density map. These dual path multi-scale fusion networks have the same structure, one path is responsible for generating attention map by highlighting crowd regions in images, the other path is responsible for fusing multi-scale features as well as attention map to generate the final high-quality high-resolution density maps. SFANet can be easily trained in an end-to-end way by dual path joint training. We have evaluated our method on four crowd counting datasets (ShanghaiTech, UCF CC 50, UCSD and UCF-QRNF). The results demonstrate that with attention mechanism and multi-scale feature fusion, the proposed SFANet achieves the best performance on all these datasets and generates better quality density maps compared with other state-of-the-art approaches.
High Order Neural Networks for Video Classification
Nov 19, 2018
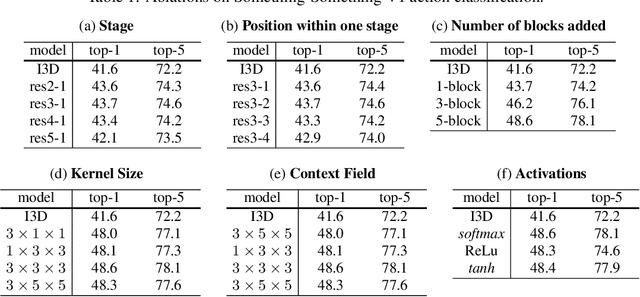
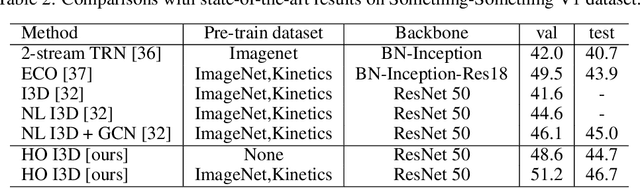

Capturing spatiotemporal correlations is an essential topic in video classification. In this paper, we present high order operations as a generic family of building blocks for capturing high order correlations from high dimensional input video space. We prove that several successful architectures for visual classification tasks are in the family of high order neural networks, theoretical and experimental analysis demonstrates their underlying mechanism is high order. We also proposal a new LEarnable hiGh Order (LEGO) block, whose goal is to capture spatiotemporal correlation in a feedforward manner. Specifically, LEGO blocks implicitly learn the relation expressions for spatiotemporal features and use the learned relations to weight input features. This building block can be plugged into many neural network architectures, achieving evident improvement without introducing much overhead. On the task of video classification, even using RGB only without fine-tuning with other video datasets, our high order models can achieve results on par with or better than the existing state-of-the-art methods on both Something-Something (V1 and V2) and Charades datasets.
Qiniu Submission to ActivityNet Challenge 2018
Jun 12, 2018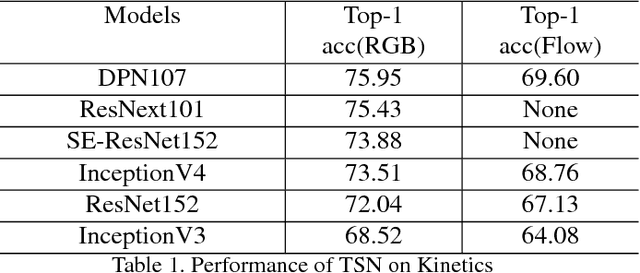
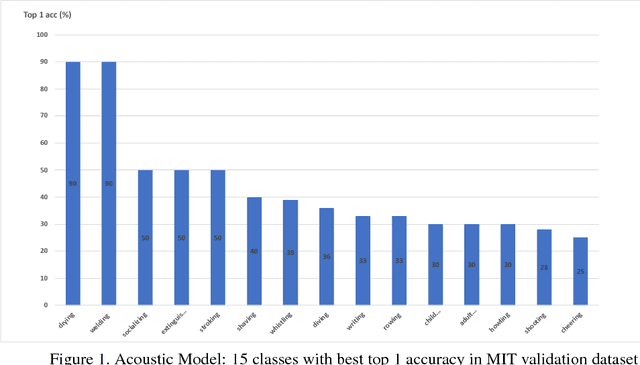
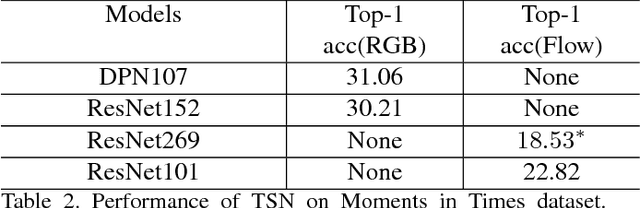
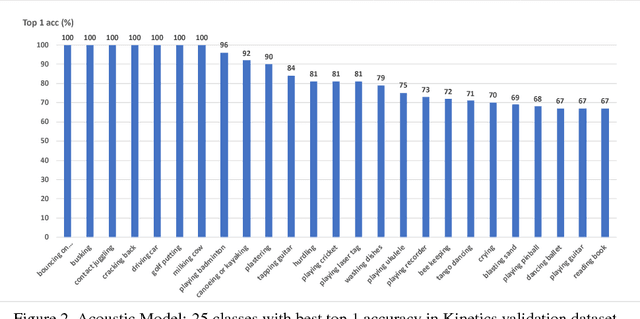
In this paper, we introduce our submissions for the tasks of trimmed activity recognition (Kinetics) and trimmed event recognition (Moments in Time) for Activitynet Challenge 2018. In the two tasks, non-local neural networks and temporal segment networks are implemented as our base models. Multi-modal cues such as RGB image, optical flow and acoustic signal have also been used in our method. We also propose new non-local-based models for further improvement on the recognition accuracy. The final submissions after ensembling the models achieve 83.5% top-1 accuracy and 96.8% top-5 accuracy on the Kinetics validation set, 35.81% top-1 accuracy and 62.59% top-5 accuracy on the MIT validation set.