 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Resource Allocation Policy: Vertex-GNN or Edge-GNN?
Jul 24, 2023Graph neural networks (GNNs) update the hidden representations of vertices (called Vertex-GNNs) or hidden representations of edges (called Edge-GNNs) by processing and pooling the information of neighboring vertices and edges and combining to incorporate graph topology. When learning resource allocation policies, GNNs cannot perform well if their expressive power are weak, i.e., if they cannot differentiate all input features such as channel matrices. In this paper, we analyze the expressive power of the Vertex-GNNs and Edge-GNNs for learning three representative wireless policies: link scheduling, power control, and precoding policies. We find that the expressive power of the GNNs depend on the linearity and output dimensions of the processing and combination functions. When linear processors are used, the Vertex-GNNs cannot differentiate all channel matrices due to the loss of channel information, while the Edge-GNNs can. When learning the precoding policy, even the Vertex-GNNs with non-linear processors may not be with strong expressive ability due to the dimension compression. We proceed to provide necessary conditions for the GNNs to well learn the precoding policy. Simulation results validate the analyses and show that the Edge-GNNs can achieve the same performance as the Vertex-GNNs with much lower training and inference time.
Multi-Temporal Aerial Image Registration Using Semantic Features
Sep 19, 2019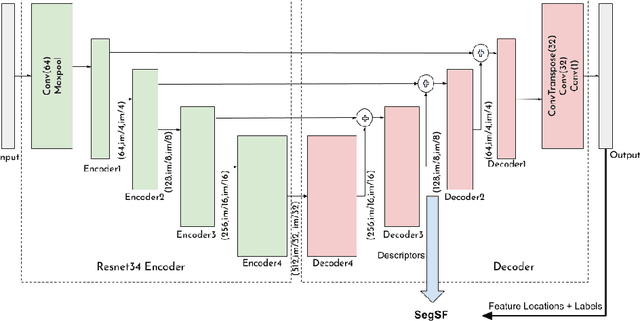


A semantic feature extraction method for multitemporal high resolution aerial image registration is proposed in this paper. These features encode properties or information about temporally invariant objects such as roads and help deal with issues such as changing foliage in image registration, which classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and have shown good robustness and accuracy in registering aerial images across years and seasons in the experiments.
Question Guided Modular Routing Networks for Visual Question Answering
Apr 17, 2019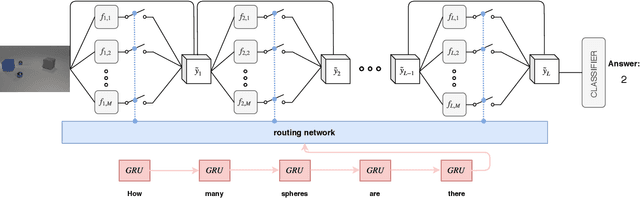
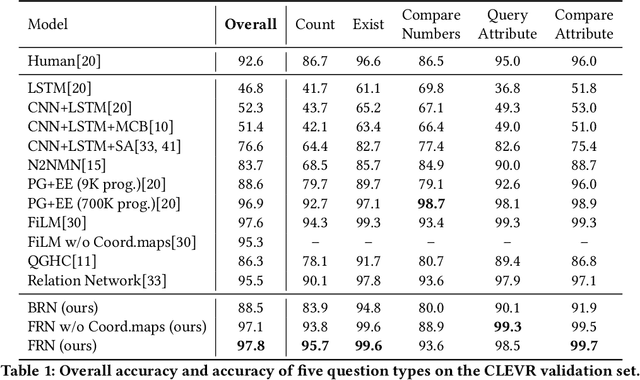
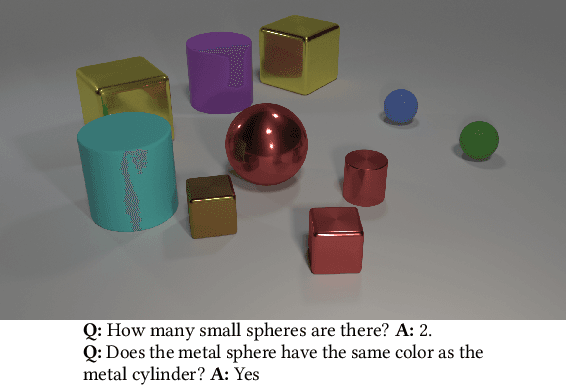

Visual Question Answering (VQA) faces two major challenges: how to better fuse the visual and textual modalities and how to make the VQA model have the reasoning ability to answer more complex questions. In this paper, we address both challenges by proposing the novel Question Guided Modular Routing Networks (QGMRN). QGMRN can fuse the visual and textual modalities in multiple semantic levels which makes the fusion occur in a fine-grained way, it also can learn to reason by routing between the generic modules without additional supervision information or prior knowledge. The proposed QGMRN consists of three sub-networks: visual network, textual network and routing network. The routing network selectively executes each module in the visual network according to the pathway activated by the question features generated by the textual network. Experiments on the CLEVR dataset show that our model can outperform the state-of-the-art. Models and Codes will be released.
Dual Path Multi-Scale Fusion Networks with Attention for Crowd Counting
Feb 04, 2019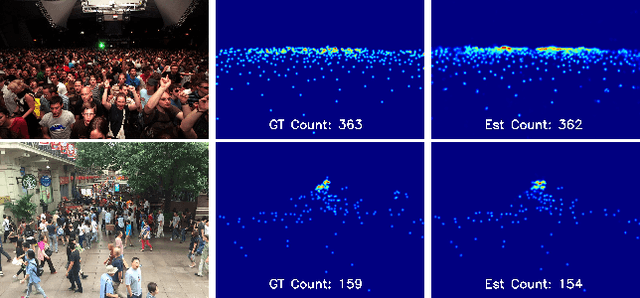
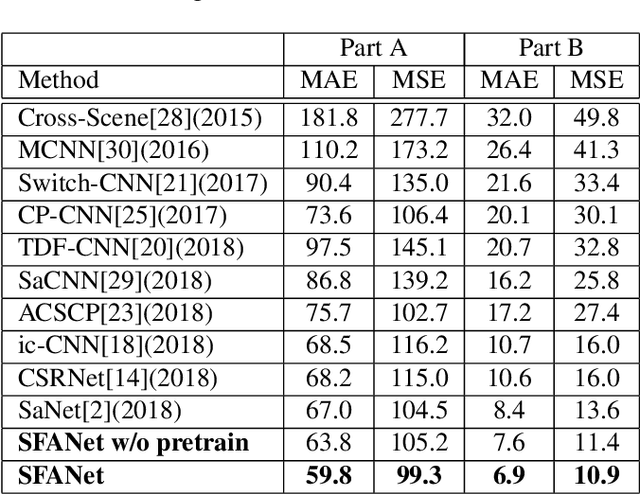
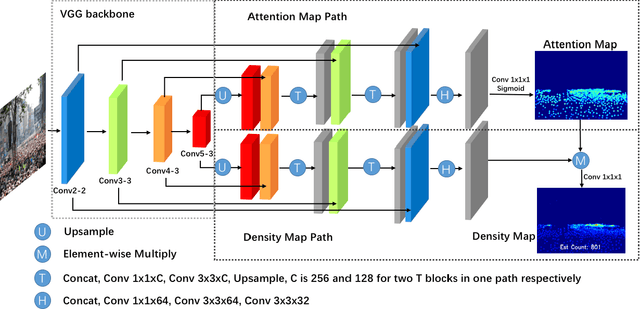
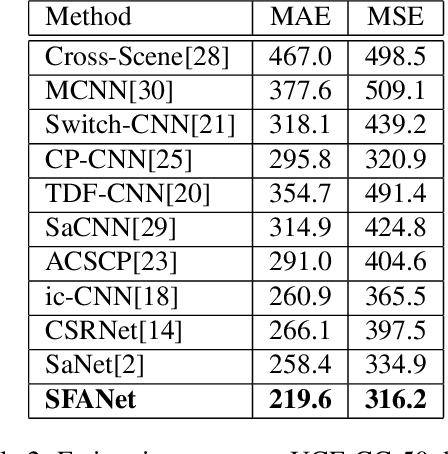
The task of crowd counting in varying density scenes is an extremely difficult challenge due to large scale variations. In this paper, we propose a novel dual path multi-scale fusion network architecture with attention mechanism named SFANet that can perform accurate count estimation as well as present high-resolution density maps for highly congested crowd scenes. The proposed SFANet contains two main components: a VGG backbone convolutional neural network (CNN) as the front-end feature map extractor and a dual path multi-scale fusion networks as the back-end to generate density map. These dual path multi-scale fusion networks have the same structure, one path is responsible for generating attention map by highlighting crowd regions in images, the other path is responsible for fusing multi-scale features as well as attention map to generate the final high-quality high-resolution density maps. SFANet can be easily trained in an end-to-end way by dual path joint training. We have evaluated our method on four crowd counting datasets (ShanghaiTech, UCF CC 50, UCSD and UCF-QRNF). The results demonstrate that with attention mechanism and multi-scale feature fusion, the proposed SFANet achieves the best performance on all these datasets and generates better quality density maps compared with other state-of-the-art approaches.
Qiniu Submission to ActivityNet Challenge 2018
Jun 12, 2018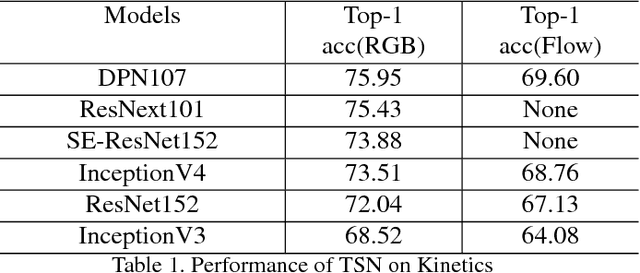
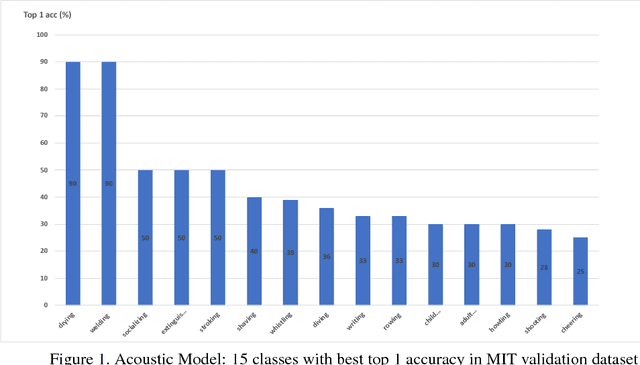
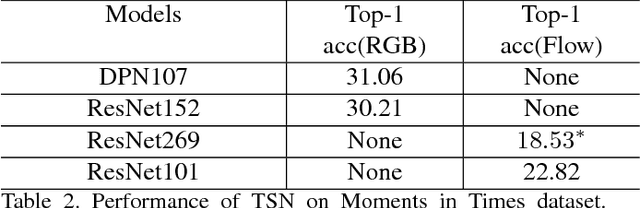
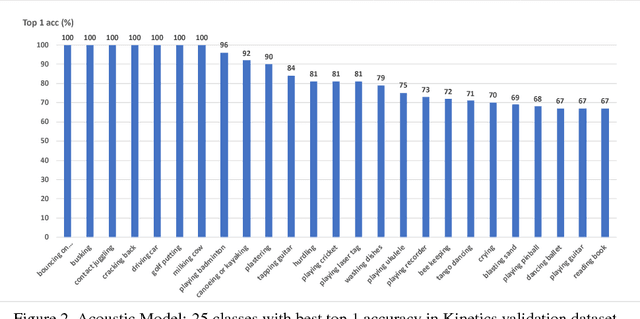
In this paper, we introduce our submissions for the tasks of trimmed activity recognition (Kinetics) and trimmed event recognition (Moments in Time) for Activitynet Challenge 2018. In the two tasks, non-local neural networks and temporal segment networks are implemented as our base models. Multi-modal cues such as RGB image, optical flow and acoustic signal have also been used in our method. We also propose new non-local-based models for further improvement on the recognition accuracy. The final submissions after ensembling the models achieve 83.5% top-1 accuracy and 96.8% top-5 accuracy on the Kinetics validation set, 35.81% top-1 accuracy and 62.59% top-5 accuracy on the MIT validation set.