 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution Strategies for Deep RL pretraining
Mar 31, 2026Although Deep Reinforcement Learning has proven highly effective for complex decision-making problems, it demands significant computational resources and careful parameter adjustment in order to develop successful strategies. Evolution strategies offer a more straightforward, derivative-free approach that is less computationally costly and simpler to deploy. However, ES generally do not match the performance levels achieved by DRL, which calls into question their suitability for more demanding scenarios. This study examines the performance of ES and DRL across tasks of varying difficulty, including Flappy Bird, Breakout and Mujoco environments, as well as whether ES could be used for initial training to enhance DRL algorithms. The results indicate that ES do not consistently train faster than DRL. When used as a preliminary training step, they only provide benefits in less complex environments (Flappy Bird) and show minimal or no improvement in training efficiency or stability across different parameter settings when applied to more sophisticated tasks (Breakout and MuJoCo Walker).
UATTA-ENS: Uncertainty Aware Test Time Augmented Ensemble for PIRC Diabetic Retinopathy Detection
Nov 08, 2022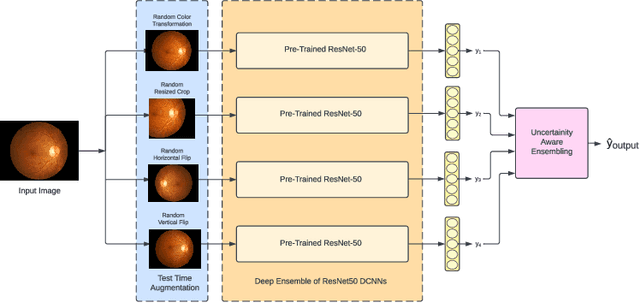
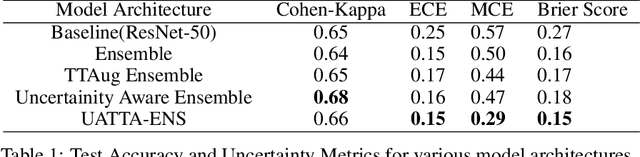
Deep Ensemble Convolutional Neural Networks has become a methodology of choice for analyzing medical images with a diagnostic performance comparable to a physician, including the diagnosis of Diabetic Retinopathy. However, commonly used techniques are deterministic and are therefore unable to provide any estimate of predictive uncertainty. Quantifying model uncertainty is crucial for reducing the risk of misdiagnosis. A reliable architecture should be well-calibrated to avoid over-confident predictions. To address this, we propose a UATTA-ENS: Uncertainty-Aware Test-Time Augmented Ensemble Technique for 5 Class PIRC Diabetic Retinopathy Classification to produce reliable and well-calibrated predictions.
CNN-Based Semantic Change Detection in Satellite Imagery
Jun 10, 2020
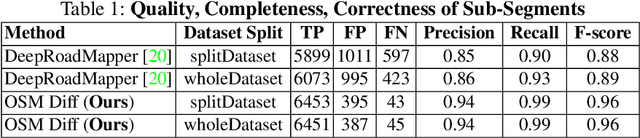
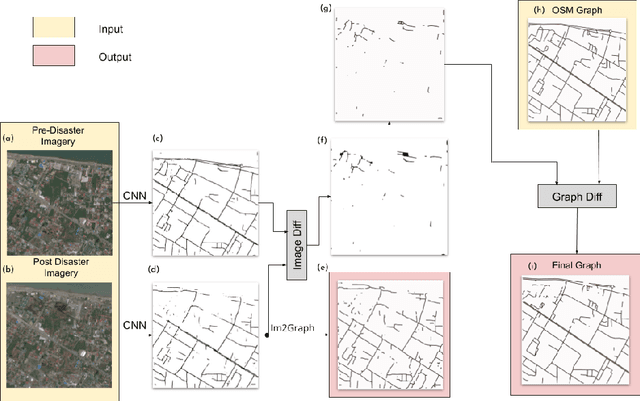
Timely disaster risk management requires accurate road maps and prompt damage assessment. Currently, this is done by volunteers manually marking satellite imagery of affected areas but this process is slow and often error-prone. Segmentation algorithms can be applied to satellite images to detect road networks. However, existing methods are unsuitable for disaster-struck areas as they make assumptions about the road network topology which may no longer be valid in these scenarios. Herein, we propose a CNN-based framework for identifying accessible roads in post-disaster imagery by detecting changes from pre-disaster imagery. Graph theory is combined with the CNN output for detecting semantic changes in road networks with OpenStreetMap data. Our results are validated with data of a tsunami-affected region in Palu, Indonesia acquired from DigitalGlobe.
Deep Learning-based Aerial Image Segmentation with Open Data for Disaster Impact Assessment
Jun 10, 2020
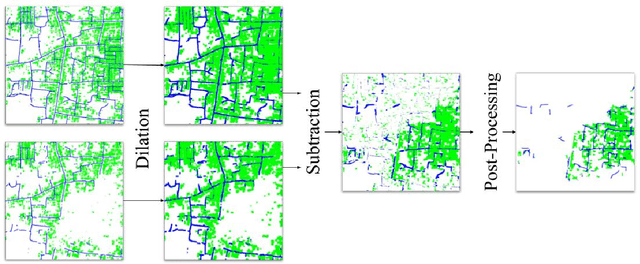
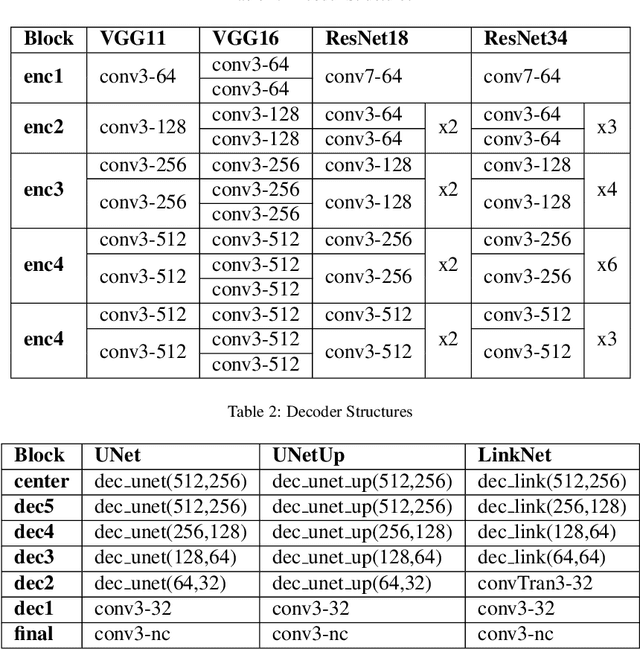
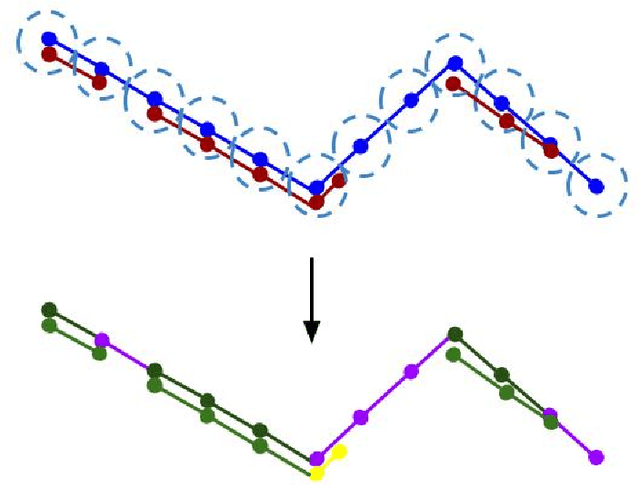
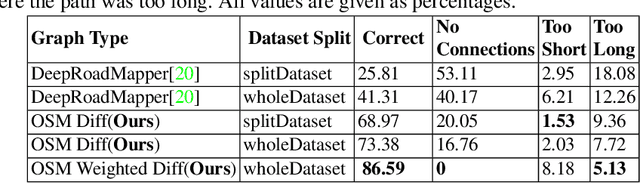
Satellite images are an extremely valuable resource in the aftermath of natural disasters such as hurricanes and tsunamis where they can be used for risk assessment and disaster management. In order to provide timely and actionable information for disaster response, in this paper a framework utilising segmentation neural networks is proposed to identify impacted areas and accessible roads in post-disaster scenarios. The effectiveness of pretraining with ImageNet on the task of aerial image segmentation has been analysed and performances of popular segmentation models compared. Experimental results show that pretraining on ImageNet usually improves the segmentation performance for a number of models. Open data available from OpenStreetMap (OSM) is used for training, forgoing the need for time-consuming manual annotation. The method also makes use of graph theory to update road network data available from OSM and to detect the changes caused by a natural disaster. Extensive experiments on data from the 2018 tsunami that struck Palu, Indonesia show the effectiveness of the proposed framework. ENetSeparable, with 30% fewer parameters compared to ENet, achieved comparable segmentation results to that of the state-of-the-art networks.
Tree Annotations in LiDAR Data Using Point Densities and Convolutional Neural Networks
Jun 09, 2020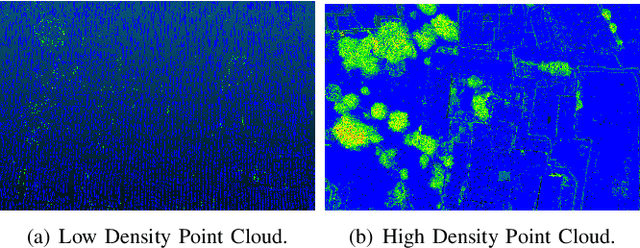

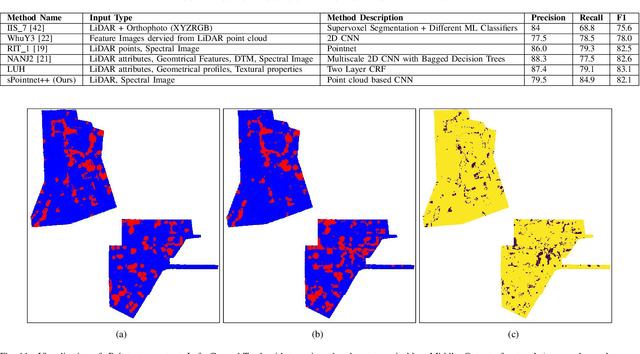
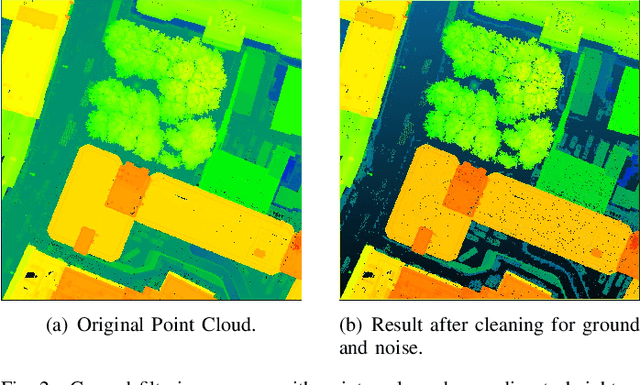
LiDAR provides highly accurate 3D point clouds. However, data needs to be manually labelled in order to provide subsequent useful information. Manual annotation of such data is time consuming, tedious and error prone, and hence in this paper we present three automatic methods for annotating trees in LiDAR data. The first method requires high density point clouds and uses certain LiDAR data attributes for the purpose of tree identification, achieving almost 90% accuracy. The second method uses a voxel-based 3D Convolutional Neural Network on low density LiDAR datasets and is able to identify most large trees accurately but struggles with smaller ones due to the voxelisation process. The third method is a scaled version of the PointNet++ method and works directly on outdoor point clouds and achieves an F_score of 82.1% on the ISPRS benchmark dataset, comparable to the state-of-the-art methods but with increased efficiency.
3D Point Cloud Feature Explanations Using Gradient-Based Methods
Jun 09, 2020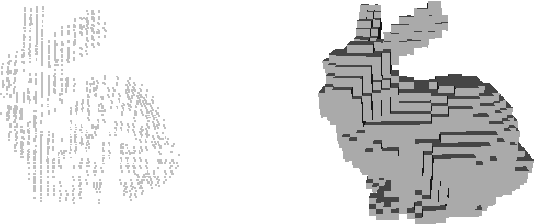
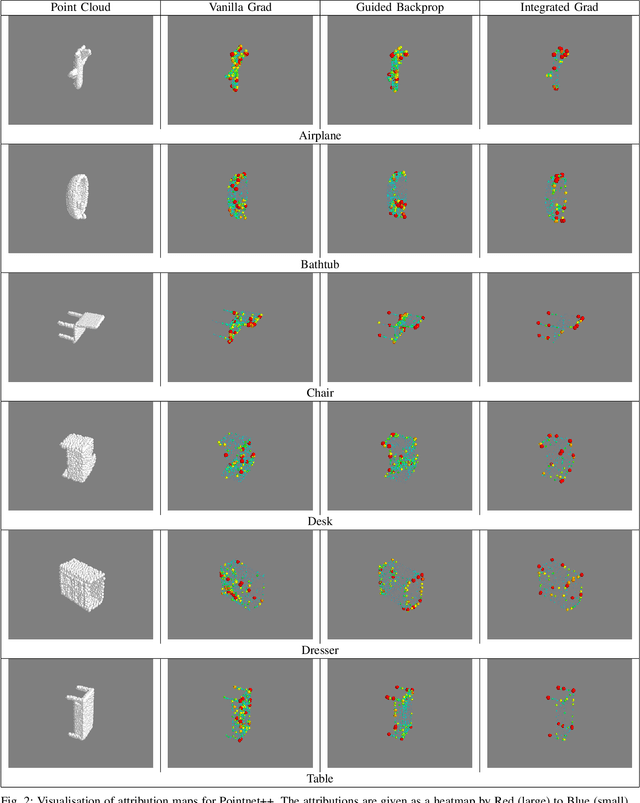
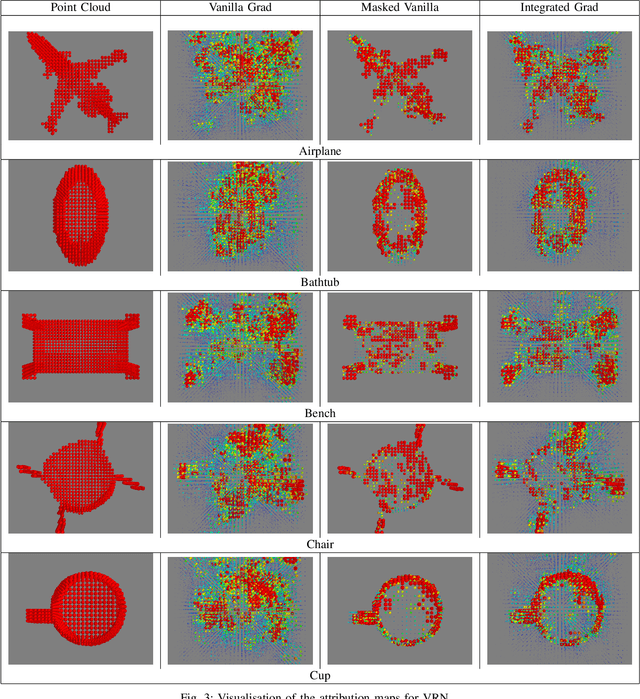

Explainability is an important factor to drive user trust in the use of neural networks for tasks with material impact. However, most of the work done in this area focuses on image analysis and does not take into account 3D data. We extend the saliency methods that have been shown to work on image data to deal with 3D data. We analyse the features in point clouds and voxel spaces and show that edges and corners in 3D data are deemed as important features while planar surfaces are deemed less important. The approach is model-agnostic and can provide useful information about learnt features. Driven by the insight that 3D data is inherently sparse, we visualise the features learnt by a voxel-based classification network and show that these features are also sparse and can be pruned relatively easily, leading to more efficient neural networks. Our results show that the Voxception-ResNet model can be pruned down to 5\% of its parameters with negligible loss in accuracy.
Multi-Temporal Aerial Image Registration Using Semantic Features
Sep 19, 2019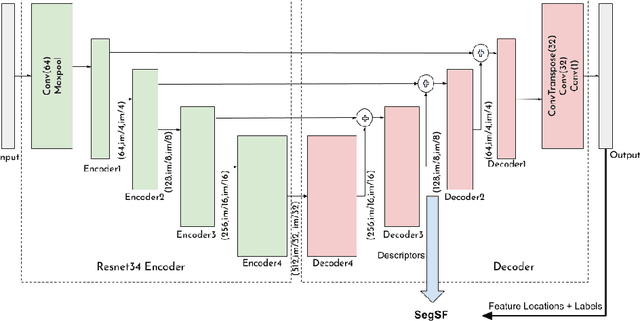


A semantic feature extraction method for multitemporal high resolution aerial image registration is proposed in this paper. These features encode properties or information about temporally invariant objects such as roads and help deal with issues such as changing foliage in image registration, which classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and have shown good robustness and accuracy in registering aerial images across years and seasons in the experiments.