 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
Jun 18, 2026Agent benchmarks are growing fast, but no single benchmark touches more than four or five of the dimensions that deployment exposes. This paper aggregates the largest coordinated deep-dive of one MCP-based industrial-agent benchmark to date: fourteen parallel implementation studies covering new asset classes (including a multi-modal visual extension), alternative orchestrations, retrieval strategies, reasoning modes, infrastructure optimizations, and evaluation-methodology probes. Consolidating those studies with seven prior agent benchmarks, we argue that aggregate-score leaderboards systematically underspecify deployed-agent evaluation. Rankings derived from aggregate scores do not transfer to out-of-distribution settings; recent public-to-hidden competition retrospectives provide direct empirical evidence of this rank instability. We propose ranking configurations by predictive validity, the correlation between in-sample and out-of-sample rank, rather than in-sample mean, and report a twelve-tier measurement apparatus that exposes the deployment-relevant dimensions HELM and its agent-era successors collapse. The position is operationalized through three falsifiable out-of-distribution criteria with explicit thresholds; existing evidence partly supports it but is too thin to confirm. We close with a pre-registered pilot design and a field-level vision for what the next generation of agentic benchmarks should report.
SpatialMath: Spatial Comprehension-Infused Symbolic Reasoning for Mathematical Problem-Solving
Jan 24, 2026Multimodal Small-to-Medium sized Language Models (MSLMs) have demonstrated strong capabilities in integrating visual and textual information but still face significant limitations in visual comprehension and mathematical reasoning, particularly in geometric problems with diverse levels of visual infusion. Current models struggle to accurately decompose intricate visual inputs and connect perception with structured reasoning, leading to suboptimal performance. To address these challenges, we propose SpatialMath, a novel Spatial Comprehension-Infused Symbolic Reasoning Framework designed to integrate spatial representations into structured symbolic reasoning chains. SpatialMath employs a specialized perception module to extract spatially-grounded representations from visual diagrams, capturing critical geometric structures and spatial relationships. These representations are then methodically infused into symbolic reasoning chains, facilitating visual comprehension-aware structured reasoning. To this end, we introduce MATHVERSE-PLUS, a novel dataset containing structured visual interpretations and step-by-step reasoning paths for vision-intensive mathematical problems. SpatialMath significantly outperforms strong multimodal baselines, achieving up to 10 percentage points improvement over supervised fine-tuning with data augmentation in vision-intensive settings. Robustness analysis reveals that enhanced spatial representations directly improve reasoning accuracy, reinforcing the need for structured perception-to-reasoning pipelines in MSLMs.
Analyzing Effects of Fake Training Data on the Performance of Deep Learning Systems
Mar 02, 2023Deep learning models frequently suffer from various problems such as class imbalance and lack of robustness to distribution shift. It is often difficult to find data suitable for training beyond the available benchmarks. This is especially the case for computer vision models. However, with the advent of Generative Adversarial Networks (GANs), it is now possible to generate high-quality synthetic data. This synthetic data can be used to alleviate some of the challenges faced by deep learning models. In this work we present a detailed analysis of the effect of training computer vision models using different proportions of synthetic data along with real (organic) data. We analyze the effect that various quantities of synthetic data, when mixed with original data, can have on a model's robustness to out-of-distribution data and the general quality of predictions.
Performance evaluation of deep segmentation models on Landsat-8 imagery
Nov 30, 2022
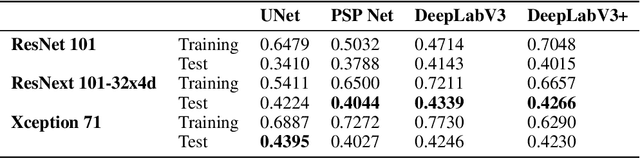
Contrails, short for condensation trails, are line-shaped ice clouds produced by aircraft engine exhaust when they fly through cold and humid air. They generate a greenhouse effect by absorbing or directing back to Earth approximately 33% of emitted outgoing longwave radiation. They account for over half of the climate change resulting from aviation activities. Avoiding contrails and adjusting flight routes could be an inexpensive and effective way to reduce their impact. An accurate, automated, and reliable detection algorithm is required to develop and evaluate contrail avoidance strategies. Advancement in contrail detection has been severely limited due to several factors, primarily due to a lack of quality-labeled data. Recently, proposed a large human-labeled Landsat-8 contrails dataset. Each contrail is carefully labeled with various inputs in various scenes of Landsat-8 satellite imagery. In this work, we benchmark several popular segmentation models with combinations of different loss functions and encoder backbones. This work is the first to apply state-of-the-art segmentation techniques to detect contrails in low-orbit satellite imagery. Our work can also be used as an open benchmark for contrail segmentation and is publicly available.
UATTA-ENS: Uncertainty Aware Test Time Augmented Ensemble for PIRC Diabetic Retinopathy Detection
Nov 08, 2022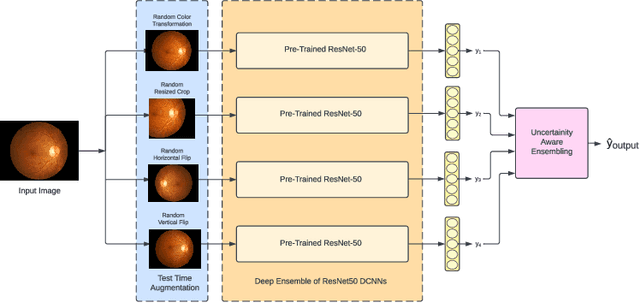
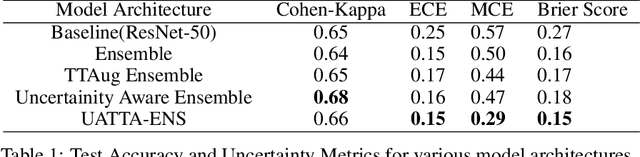
Deep Ensemble Convolutional Neural Networks has become a methodology of choice for analyzing medical images with a diagnostic performance comparable to a physician, including the diagnosis of Diabetic Retinopathy. However, commonly used techniques are deterministic and are therefore unable to provide any estimate of predictive uncertainty. Quantifying model uncertainty is crucial for reducing the risk of misdiagnosis. A reliable architecture should be well-calibrated to avoid over-confident predictions. To address this, we propose a UATTA-ENS: Uncertainty-Aware Test-Time Augmented Ensemble Technique for 5 Class PIRC Diabetic Retinopathy Classification to produce reliable and well-calibrated predictions.
Evaluating Predictive Uncertainty and Robustness to Distributional Shift Using Real World Data
Nov 08, 2021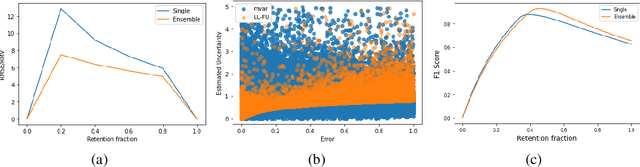
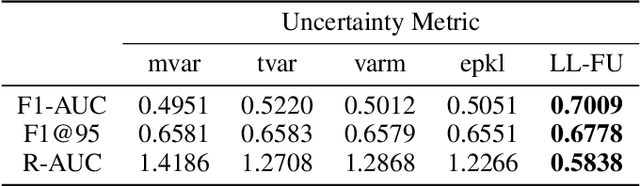
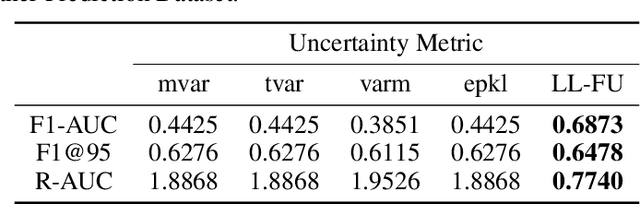

Most machine learning models operate under the assumption that the training, testing and deployment data is independent and identically distributed (i.i.d.). This assumption doesn't generally hold true in a natural setting. Usually, the deployment data is subject to various types of distributional shifts. The magnitude of a model's performance is proportional to this shift in the distribution of the dataset. Thus it becomes necessary to evaluate a model's uncertainty and robustness to distributional shifts to get a realistic estimate of its expected performance on real-world data. Present methods to evaluate uncertainty and model's robustness are lacking and often fail to paint the full picture. Moreover, most analysis so far has primarily focused on classification tasks. In this paper, we propose more insightful metrics for general regression tasks using the Shifts Weather Prediction Dataset. We also present an evaluation of the baseline methods using these metrics.