 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD-Sherlock: Multi-Agent Debates for Out-of-Context Misinformation Detection
Oct 26, 2024



One of the most challenging forms of misinformation involves the out-of-context (OOC) use of images paired with misleading text, creating false narratives. Existing AI-driven detection systems lack explainability and require expensive fine-tuning. We address these issues with MAD-Sherlock: a Multi-Agent Debate system for OOC Misinformation Detection. MAD-Sherlock introduces a novel multi-agent debate framework where multimodal agents collaborate to assess contextual consistency and request external information to enhance cross-context reasoning and decision-making. Our framework enables explainable detection with state-of-the-art accuracy even without domain-specific fine-tuning. Extensive ablation studies confirm that external retrieval significantly improves detection accuracy, and user studies demonstrate that MAD-Sherlock boosts performance for both experts and non-experts. These results position MAD-Sherlock as a powerful tool for autonomous and citizen intelligence applications.
Analyzing Effects of Fake Training Data on the Performance of Deep Learning Systems
Mar 02, 2023Deep learning models frequently suffer from various problems such as class imbalance and lack of robustness to distribution shift. It is often difficult to find data suitable for training beyond the available benchmarks. This is especially the case for computer vision models. However, with the advent of Generative Adversarial Networks (GANs), it is now possible to generate high-quality synthetic data. This synthetic data can be used to alleviate some of the challenges faced by deep learning models. In this work we present a detailed analysis of the effect of training computer vision models using different proportions of synthetic data along with real (organic) data. We analyze the effect that various quantities of synthetic data, when mixed with original data, can have on a model's robustness to out-of-distribution data and the general quality of predictions.
Disentangled Uncertainty and Out of Distribution Detection in Medical Generative Models
Nov 11, 2022

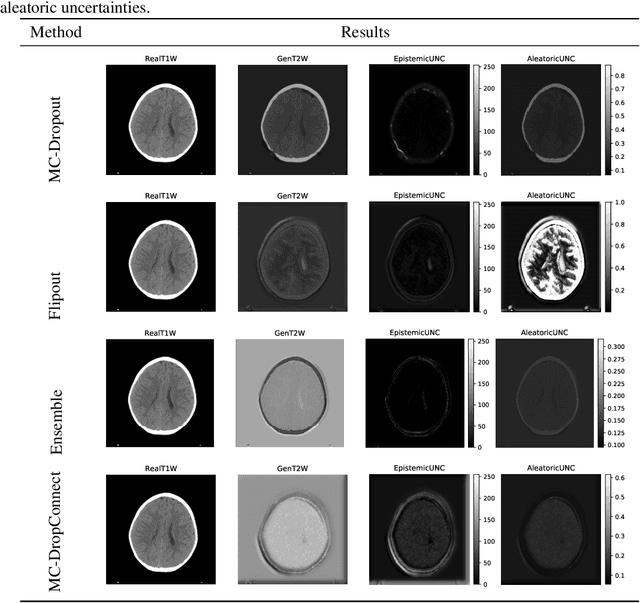
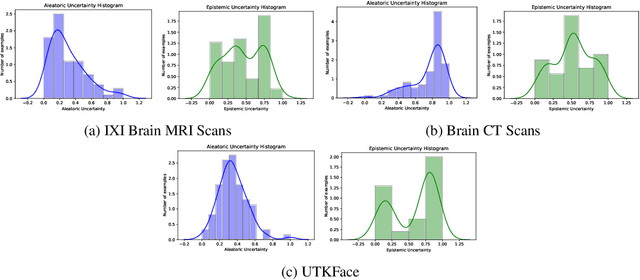
Trusting the predictions of deep learning models in safety critical settings such as the medical domain is still not a viable option. Distentangled uncertainty quantification in the field of medical imaging has received little attention. In this paper, we study disentangled uncertainties in image to image translation tasks in the medical domain. We compare multiple uncertainty quantification methods, namely Ensembles, Flipout, Dropout, and DropConnect, while using CycleGAN to convert T1-weighted brain MRI scans to T2-weighted brain MRI scans. We further evaluate uncertainty behavior in the presence of out of distribution data (Brain CT and RGB Face Images), showing that epistemic uncertainty can be used to detect out of distribution inputs, which should increase reliability of model outputs.
Evaluating Predictive Uncertainty and Robustness to Distributional Shift Using Real World Data
Nov 08, 2021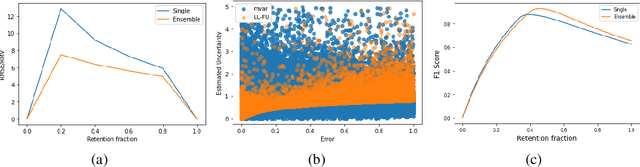
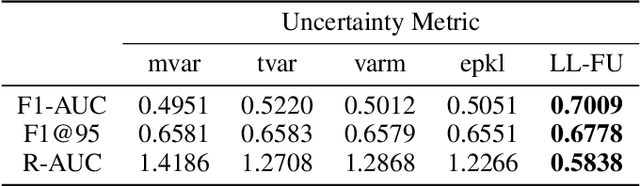
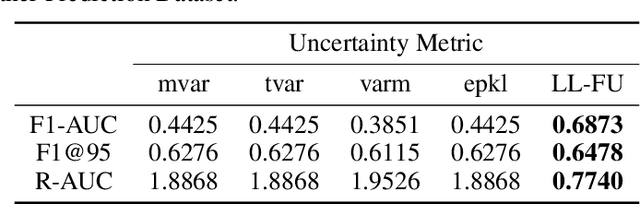

Most machine learning models operate under the assumption that the training, testing and deployment data is independent and identically distributed (i.i.d.). This assumption doesn't generally hold true in a natural setting. Usually, the deployment data is subject to various types of distributional shifts. The magnitude of a model's performance is proportional to this shift in the distribution of the dataset. Thus it becomes necessary to evaluate a model's uncertainty and robustness to distributional shifts to get a realistic estimate of its expected performance on real-world data. Present methods to evaluate uncertainty and model's robustness are lacking and often fail to paint the full picture. Moreover, most analysis so far has primarily focused on classification tasks. In this paper, we propose more insightful metrics for general regression tasks using the Shifts Weather Prediction Dataset. We also present an evaluation of the baseline methods using these metrics.
BERT based Transformers lead the way in Extraction of Health Information from Social Media
Apr 15, 2021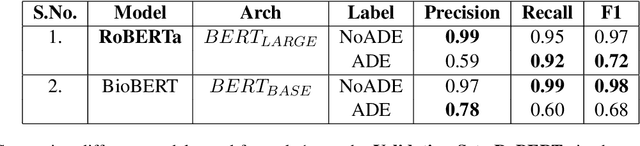



This paper describes our submissions for the Social Media Mining for Health (SMM4H)2021 shared tasks. We participated in 2 tasks:(1) Classification, extraction and normalization of adverse drug effect (ADE) mentions in English tweets (Task-1) and (2) Classification of COVID-19 tweets containing symptoms(Task-6). Our approach for the first task uses the language representation model RoBERTa with a binary classification head. For the second task, we use BERTweet, based on RoBERTa. Fine-tuning is performed on the pre-trained models for both tasks. The models are placed on top of a custom domain-specific processing pipeline. Our system ranked first among all the submissions for subtask-1(a) with an F1-score of 61%. For subtask-1(b), our system obtained an F1-score of 50% with improvements up to +8% F1 over the score averaged across all submissions. The BERTweet model achieved an F1 score of 94% on SMM4H 2021 Task-6.