 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyScenes: A Synthetic Dataset for Aerial Scene Understanding
Dec 11, 2023



Real-world aerial scene understanding is limited by a lack of datasets that contain densely annotated images curated under a diverse set of conditions. Due to inherent challenges in obtaining such images in controlled real-world settings, we present SkyScenes, a synthetic dataset of densely annotated aerial images captured from Unmanned Aerial Vehicle (UAV) perspectives. We carefully curate SkyScenes images from CARLA to comprehensively capture diversity across layout (urban and rural maps), weather conditions, times of day, pitch angles and altitudes with corresponding semantic, instance and depth annotations. Through our experiments using SkyScenes, we show that (1) Models trained on SkyScenes generalize well to different real-world scenarios, (2) augmenting training on real images with SkyScenes data can improve real-world performance, (3) controlled variations in SkyScenes can offer insights into how models respond to changes in viewpoint conditions, and (4) incorporating additional sensor modalities (depth) can improve aerial scene understanding.
LatentDR: Improving Model Generalization Through Sample-Aware Latent Degradation and Restoration
Aug 28, 2023Despite significant advances in deep learning, models often struggle to generalize well to new, unseen domains, especially when training data is limited. To address this challenge, we propose a novel approach for distribution-aware latent augmentation that leverages the relationships across samples to guide the augmentation procedure. Our approach first degrades the samples stochastically in the latent space, mapping them to augmented labels, and then restores the samples from their corrupted versions during training. This process confuses the classifier in the degradation step and restores the overall class distribution of the original samples, promoting diverse intra-class/cross-domain variability. We extensively evaluate our approach on a diverse set of datasets and tasks, including domain generalization benchmarks and medical imaging datasets with strong domain shift, where we show our approach achieves significant improvements over existing methods for latent space augmentation. We further show that our method can be flexibly adapted to long-tail recognition tasks, demonstrating its versatility in building more generalizable models. Code is available at https://github.com/nerdslab/LatentDR.
Continual VQA for Disaster Response Systems
Sep 21, 2022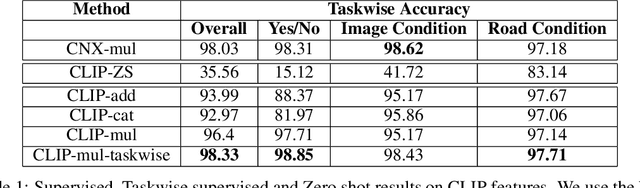
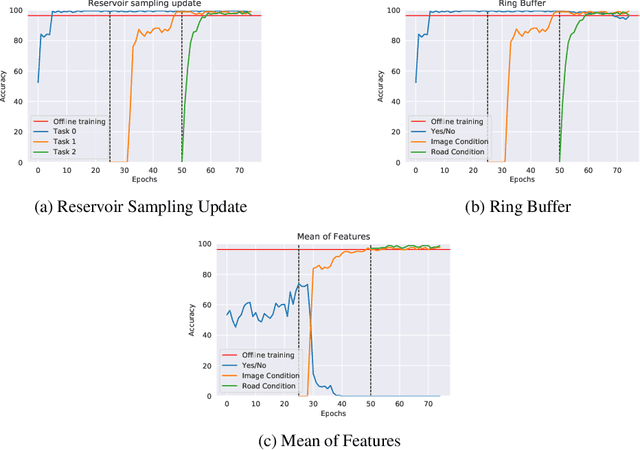
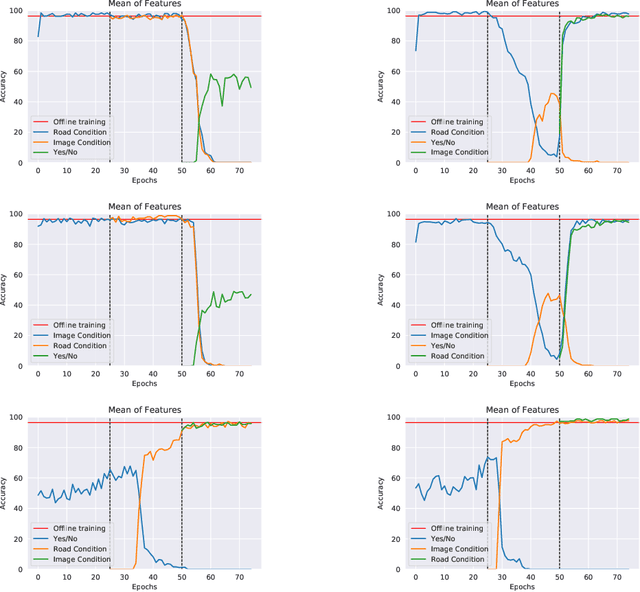
Visual Question Answering (VQA) is a multi-modal task that involves answering questions from an input image, semantically understanding the contents of the image and answering it in natural language. Using VQA for disaster management is an important line of research due to the scope of problems that are answered by the VQA system. However, the main challenge is the delay caused by the generation of labels in the assessment of the affected areas. To tackle this, we deployed pre-trained CLIP model, which is trained on visual-image pairs. however, we empirically see that the model has poor zero-shot performance. Thus, we instead use pre-trained embeddings of text and image from this model for our supervised training and surpass previous state-of-the-art results on the FloodNet dataset. We expand this to a continual setting, which is a more real-life scenario. We tackle the problem of catastrophic forgetting using various experience replay methods. Our training runs are available at: https://wandb.ai/compyle/continual_vqa_final
An Efficient Modern Baseline for FloodNet VQA
May 30, 2022


Designing efficient and reliable VQA systems remains a challenging problem, more so in the case of disaster management and response systems. In this work, we revisit fundamental combination methods like concatenation, addition and element-wise multiplication with modern image and text feature abstraction models. We design a simple and efficient system which outperforms pre-existing methods on the FloodNet dataset and achieves state-of-the-art performance. This simplified system requires significantly less training and inference time than modern VQA architectures. We also study the performance of various backbones and report their consolidated results. Code is available at https://github.com/sahilkhose/floodnet_vqa.
Transformer based ensemble for emotion detection
Apr 10, 2022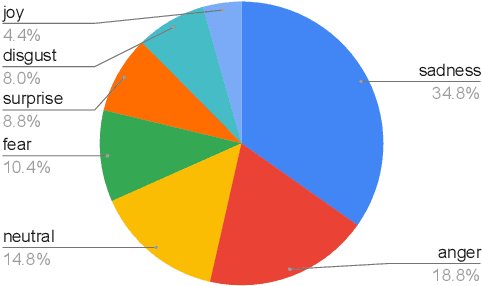
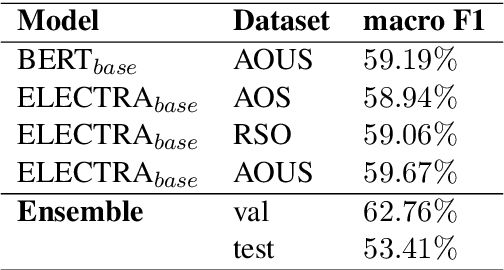
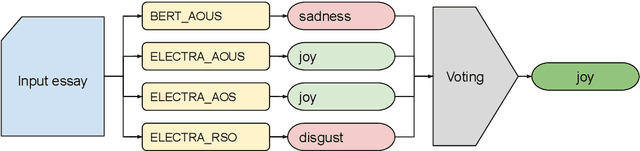
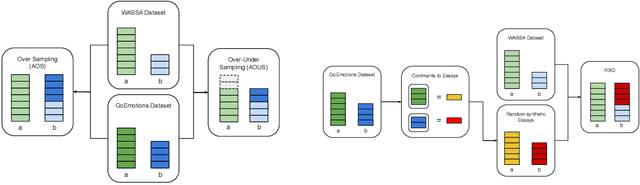
Detecting emotions in languages is important to accomplish a complete interaction between humans and machines. This paper describes our contribution to the WASSA 2022 shared task which handles this crucial task of emotion detection. We have to identify the following emotions: sadness, surprise, neutral, anger, fear, disgust, joy based on a given essay text. We are using an ensemble of ELECTRA and BERT models to tackle this problem achieving an F1 score of $62.76\%$. Our codebase (https://bit.ly/WASSA_shared_task) and our WandB project (https://wandb.ai/acl_wassa_pictxmanipal/acl_wassa) is publicly available.
A Studious Approach to Semi-Supervised Learning
Sep 18, 2021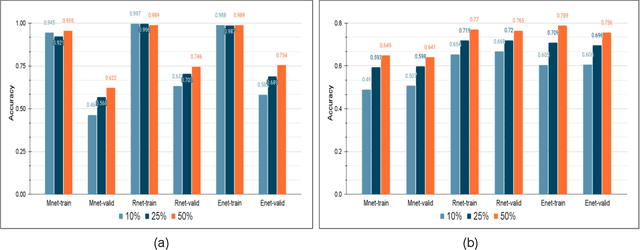
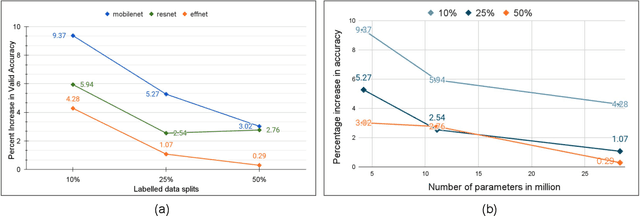
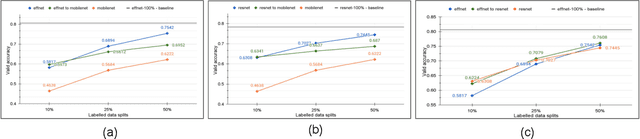
The problem of learning from few labeled examples while using large amounts of unlabeled data has been approached by various semi-supervised methods. Although these methods can achieve superior performance, the models are often not deployable due to the large number of parameters. This paper is an ablation study of distillation in a semi-supervised setting, which not just reduces the number of parameters of the model but can achieve this while improving the performance over the baseline supervised model and making it better at generalizing. After the supervised pretraining, the network is used as a teacher model, and a student network is trained over the soft labels that the teacher model generates over the entire unlabeled data. We find that the fewer the labels, the more this approach benefits from a smaller student network. This brings forward the potential of distillation as an effective solution to enhance performance in semi-supervised computer vision tasks while maintaining deployability.
XCI-Sketch: Extraction of Color Information from Images for Generation of Colored Outlines and Sketches
Aug 26, 2021
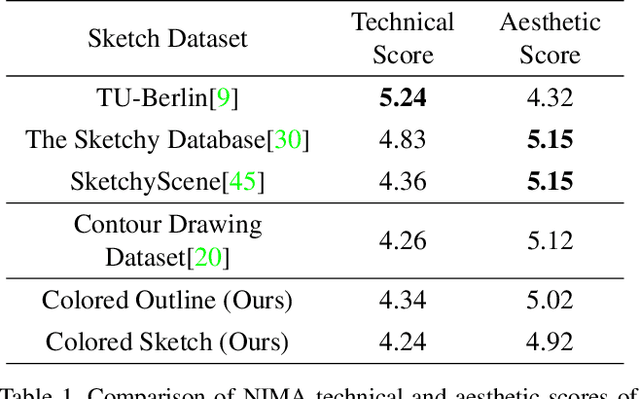
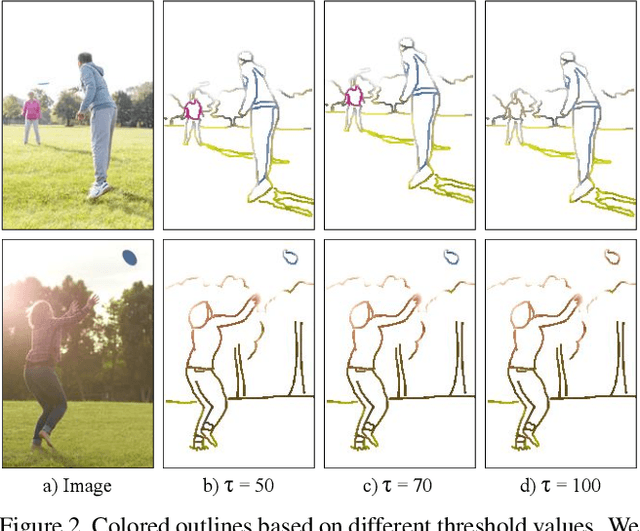

Sketches are a medium to convey a visual scene from an individual's creative perspective. The addition of color substantially enhances the overall expressivity of a sketch. This paper proposes two methods to mimic human-drawn colored sketches by utilizing the Contour Drawing Dataset. Our first approach renders colored outline sketches by applying image processing techniques aided by k-means color clustering. The second method uses a generative adversarial network to develop a model that can generate colored sketches from previously unobserved images. We assess the results obtained through quantitative and qualitative evaluations.
Semi-Supervised Classification and Segmentation on High Resolution Aerial Images
May 16, 2021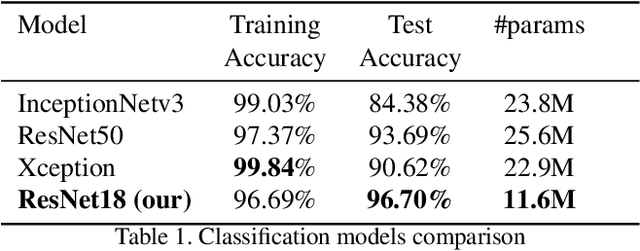
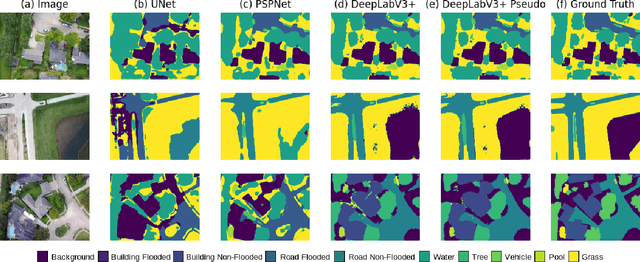

FloodNet is a high-resolution image dataset acquired by a small UAV platform, DJI Mavic Pro quadcopters, after Hurricane Harvey. The dataset presents a unique challenge of advancing the damage assessment process for post-disaster scenarios using unlabeled and limited labeled dataset. We propose a solution to address their classification and semantic segmentation challenge. We approach this problem by generating pseudo labels for both classification and segmentation during training and slowly incrementing the amount by which the pseudo label loss affects the final loss. Using this semi-supervised method of training helped us improve our baseline supervised loss by a huge margin for classification, allowing the model to generalize and perform better on the validation and test splits of the dataset. In this paper, we compare and contrast the various methods and models for image classification and semantic segmentation on the FloodNet dataset.
BERT based Transformers lead the way in Extraction of Health Information from Social Media
Apr 15, 2021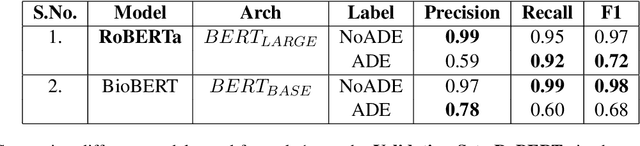



This paper describes our submissions for the Social Media Mining for Health (SMM4H)2021 shared tasks. We participated in 2 tasks:(1) Classification, extraction and normalization of adverse drug effect (ADE) mentions in English tweets (Task-1) and (2) Classification of COVID-19 tweets containing symptoms(Task-6). Our approach for the first task uses the language representation model RoBERTa with a binary classification head. For the second task, we use BERTweet, based on RoBERTa. Fine-tuning is performed on the pre-trained models for both tasks. The models are placed on top of a custom domain-specific processing pipeline. Our system ranked first among all the submissions for subtask-1(a) with an F1-score of 61%. For subtask-1(b), our system obtained an F1-score of 50% with improvements up to +8% F1 over the score averaged across all submissions. The BERTweet model achieved an F1 score of 94% on SMM4H 2021 Task-6.