 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentDR: Improving Model Generalization Through Sample-Aware Latent Degradation and Restoration
Aug 28, 2023Despite significant advances in deep learning, models often struggle to generalize well to new, unseen domains, especially when training data is limited. To address this challenge, we propose a novel approach for distribution-aware latent augmentation that leverages the relationships across samples to guide the augmentation procedure. Our approach first degrades the samples stochastically in the latent space, mapping them to augmented labels, and then restores the samples from their corrupted versions during training. This process confuses the classifier in the degradation step and restores the overall class distribution of the original samples, promoting diverse intra-class/cross-domain variability. We extensively evaluate our approach on a diverse set of datasets and tasks, including domain generalization benchmarks and medical imaging datasets with strong domain shift, where we show our approach achieves significant improvements over existing methods for latent space augmentation. We further show that our method can be flexibly adapted to long-tail recognition tasks, demonstrating its versatility in building more generalizable models. Code is available at https://github.com/nerdslab/LatentDR.
Half-Hop: A graph upsampling approach for slowing down message passing
Aug 17, 2023
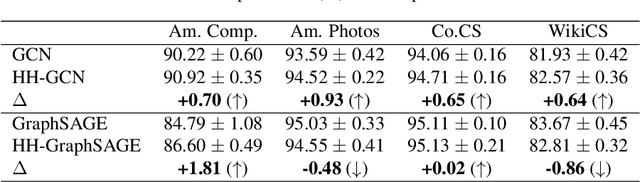

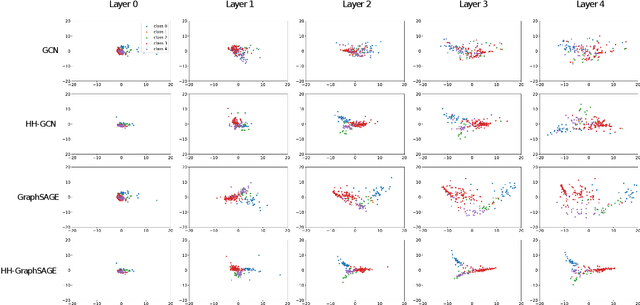
Message passing neural networks have shown a lot of success on graph-structured data. However, there are many instances where message passing can lead to over-smoothing or fail when neighboring nodes belong to different classes. In this work, we introduce a simple yet general framework for improving learning in message passing neural networks. Our approach essentially upsamples edges in the original graph by adding "slow nodes" at each edge that can mediate communication between a source and a target node. Our method only modifies the input graph, making it plug-and-play and easy to use with existing models. To understand the benefits of slowing down message passing, we provide theoretical and empirical analyses. We report results on several supervised and self-supervised benchmarks, and show improvements across the board, notably in heterophilic conditions where adjacent nodes are more likely to have different labels. Finally, we show how our approach can be used to generate augmentations for self-supervised learning, where slow nodes are randomly introduced into different edges in the graph to generate multi-scale views with variable path lengths.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023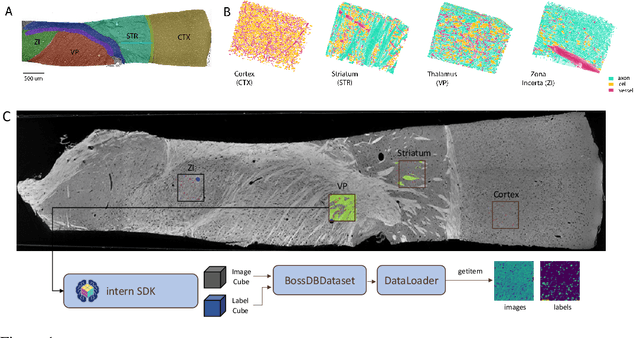
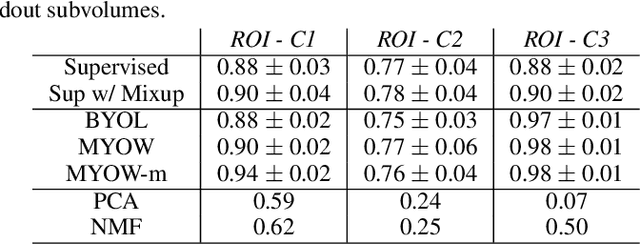

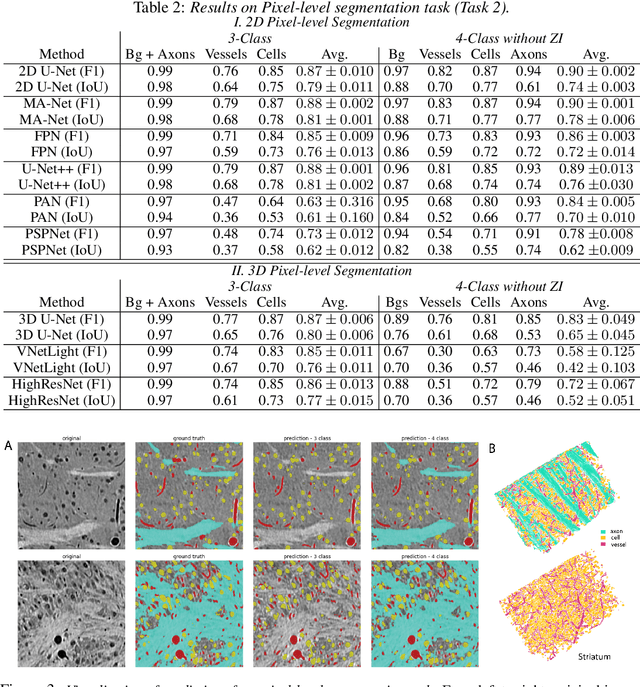
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
FlowGNN: A Dataflow Architecture for Universal Graph Neural Network Inference via Multi-Queue Streaming
Apr 27, 2022
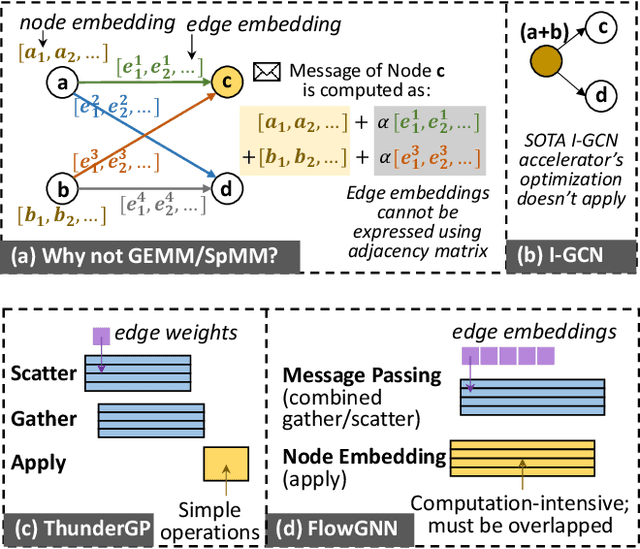
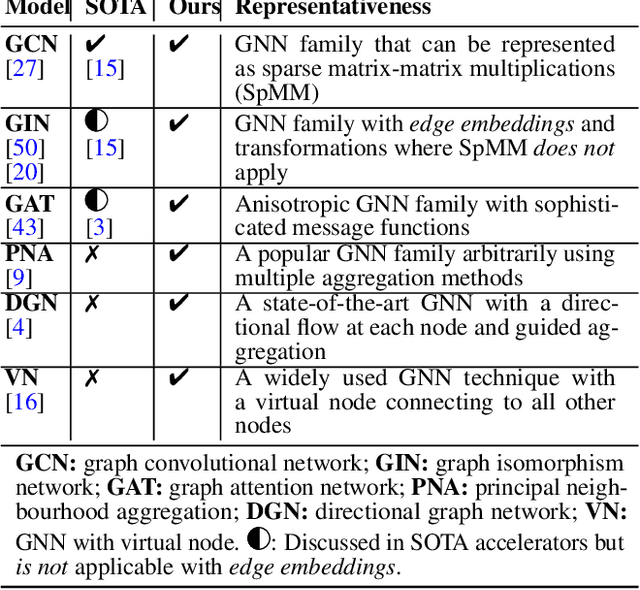
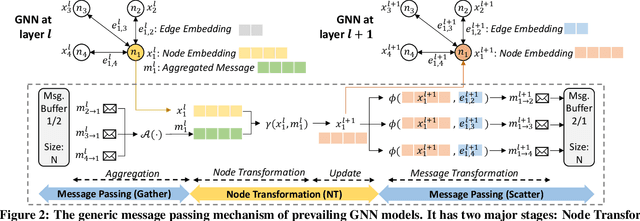
Graph neural networks (GNNs) have recently exploded in popularity thanks to their broad applicability to graph-related problems such as quantum chemistry, drug discovery, and high energy physics. However, meeting demand for novel GNN models and fast inference simultaneously is challenging because of the gap between developing efficient accelerators and the rapid creation of new GNN models. Prior art focuses on the acceleration of specific classes of GNNs, such as Graph Convolutional Network (GCN), but lacks the generality to support a wide range of existing or new GNN models. Meanwhile, most work rely on graph pre-processing to exploit data locality, making them unsuitable for real-time applications. To address these limitations, in this work, we propose a generic dataflow architecture for GNN acceleration, named FlowGNN, which can flexibly support the majority of message-passing GNNs. The contributions are three-fold. First, we propose a novel and scalable dataflow architecture, which flexibly supports a wide range of GNN models with message-passing mechanism. The architecture features a configurable dataflow optimized for simultaneous computation of node embedding, edge embedding, and message passing, which is generally applicable to all models. We also propose a rich library of model-specific components. Second, we deliver ultra-fast real-time GNN inference without any graph pre-processing, making it agnostic to dynamically changing graph structures. Third, we verify our architecture on the Xilinx Alveo U50 FPGA board and measure the on-board end-to-end performance. We achieve a speed-up of up to 51-254x against CPU (6226R) and 1.3-477x against GPU (A6000) (with batch sizes 1 through 1024); we also outperform the SOTA GNN accelerator I-GCN by 1.03x and 1.25x across two datasets. Our implementation code and on-board measurement are publicly available on GitHub.
GenGNN: A Generic FPGA Framework for Graph Neural Network Acceleration
Jan 20, 2022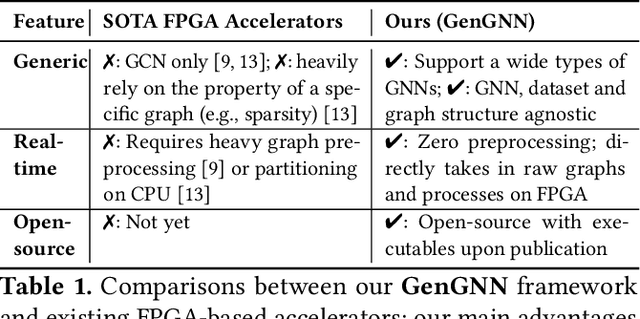
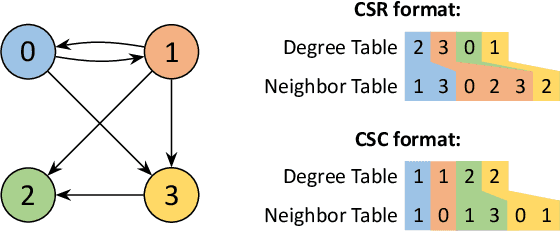
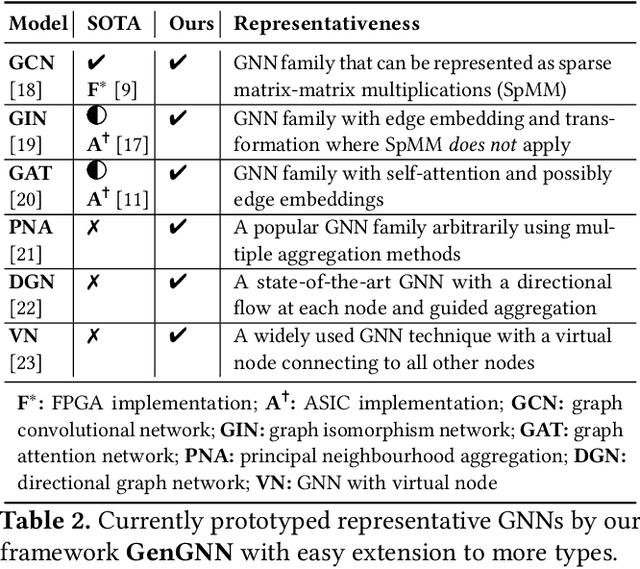
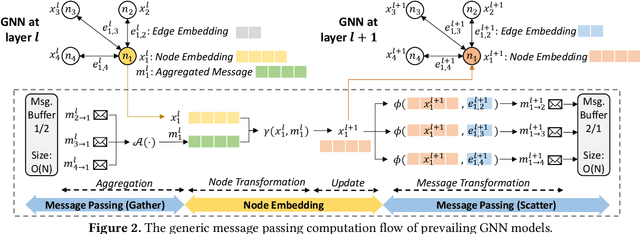
Graph neural networks (GNNs) have recently exploded in popularity thanks to their broad applicability to ubiquitous graph-related problems such as quantum chemistry, drug discovery, and high energy physics. However, meeting demand for novel GNN models and fast inference simultaneously is challenging because of the gap between the difficulty in developing efficient FPGA accelerators and the rapid pace of creation of new GNN models. Prior art focuses on the acceleration of specific classes of GNNs but lacks the generality to work across existing models or to extend to new and emerging GNN models. In this work, we propose a generic GNN acceleration framework using High-Level Synthesis (HLS), named GenGNN, with two-fold goals. First, we aim to deliver ultra-fast GNN inference without any graph pre-processing for real-time requirements. Second, we aim to support a diverse set of GNN models with the extensibility to flexibly adapt to new models. The framework features an optimized message-passing structure applicable to all models, combined with a rich library of model-specific components. We verify our implementation on-board on the Xilinx Alveo U50 FPGA and observe a speed-up of up to 25x against CPU (6226R) baseline and 13x against GPU (A6000) baseline. Our HLS code will be open-source on GitHub upon acceptance.