 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Stochasticity in LLMs
Apr 08, 2026In this work, we demonstrate that reliable stochastic sampling is a fundamental yet unfulfilled requirement for Large Language Models (LLMs) operating as agents. Agentic systems are frequently required to sample from distributions, often inferred from observed data, a process which needs to be emulated by the LLM. This leads to a distinct failure point: while standard RL agents rely on external sampling mechanisms, LLMs fail to map their internal probability estimates to their stochastic outputs. Through rigorous empirical analysis across multiple model families, model sizes, prompting styles, and distributions, we demonstrate the extent of this failure. Crucially, we show that while powerful frontier models can convert provided random seeds to target distributions, their ability to sample directly from specific distributions is fundamentally flawed.
Understanding Performance Gap Between Parallel and Sequential Sampling in Large Reasoning Models
Apr 07, 2026Large Reasoning Models (LRMs) have shown remarkable performance on challenging questions, such as math and coding. However, to obtain a high quality solution, one may need to sample more than once. In principal, there are two sampling strategies that can be composed to form more complex processes: sequential sampling and parallel sampling. In this paper, we first compare these two approaches with rigor, and observe, aligned with previous works, that parallel sampling seems to outperform sequential sampling even though the latter should have more representation power. To understand the underline reasons, we make three hypothesis on the reason behind this behavior: (i) parallel sampling outperforms due to the aggregator operator; (ii) sequential sampling is harmed by needing to use longer contexts; (iii) sequential sampling leads to less exploration due to conditioning on previous answers. The empirical evidence on various model families and sizes (Qwen3, DeepSeek-R1 distilled models, Gemini 2.5) and question domains (math and coding) suggests that the aggregation and context length do not seem to be the main culprit behind the performance gap. In contrast, the lack of exploration seems to play a considerably larger role, and we argue that this is one main cause for the performance gap.
Mining Generalizable Activation Functions
Feb 05, 2026The choice of activation function is an active area of research, with different proposals aimed at improving optimization, while maintaining expressivity. Additionally, the activation function can significantly alter the implicit inductive bias of the architecture, controlling its non-linear behavior. In this paper, in line with previous work, we argue that evolutionary search provides a useful framework for finding new activation functions, while we also make two novel observations. The first is that modern pipelines, such as AlphaEvolve, which relies on frontier LLMs as a mutator operator, allows for a much wider and flexible search space; e.g., over all possible python functions within a certain FLOP budget, eliminating the need for manually constructed search spaces. In addition, these pipelines will be biased towards meaningful activation functions, given their ability to represent common knowledge, leading to a potentially more efficient search of the space. The second observation is that, through this framework, one can target not only performance improvements but also activation functions that encode particular inductive biases. This can be done by using performance on out-of-distribution data as a fitness function, reflecting the degree to which the architecture respects the inherent structure in the data in a manner independent of distribution shifts. We carry an empirical exploration of this proposal and show that relatively small scale synthetic datasets can be sufficient for AlphaEvolve to discover meaningful activations.
Perplexity Cannot Always Tell Right from Wrong
Jan 30, 2026Perplexity -- a function measuring a model's overall level of "surprise" when encountering a particular output -- has gained significant traction in recent years, both as a loss function and as a simple-to-compute metric of model quality. Prior studies have pointed out several limitations of perplexity, often from an empirical manner. Here we leverage recent results on Transformer continuity to show in a rigorous manner how perplexity may be an unsuitable metric for model selection. Specifically, we prove that, if there is any sequence that a compact decoder-only Transformer model predicts accurately and confidently -- a necessary pre-requisite for strong generalisation -- it must imply existence of another sequence with very low perplexity, but not predicted correctly by that same model. Further, by analytically studying iso-perplexity plots, we find that perplexity will not always select for the more accurate model -- rather, any increase in model confidence must be accompanied by a commensurate rise in accuracy for the new model to be selected.
Leveraging Classical Algorithms for Graph Neural Networks
Oct 24, 2025Neural networks excel at processing unstructured data but often fail to generalise out-of-distribution, whereas classical algorithms guarantee correctness but lack flexibility. We explore whether pretraining Graph Neural Networks (GNNs) on classical algorithms can improve their performance on molecular property prediction tasks from the Open Graph Benchmark: ogbg-molhiv (HIV inhibition) and ogbg-molclintox (clinical toxicity). GNNs trained on 24 classical algorithms from the CLRS Algorithmic Reasoning Benchmark are used to initialise and freeze selected layers of a second GNN for molecular prediction. Compared to a randomly initialised baseline, the pretrained models achieve consistent wins or ties, with the Segments Intersect algorithm pretraining yielding a 6% absolute gain on ogbg-molhiv and Dijkstra pretraining achieving a 3% gain on ogbg-molclintox. These results demonstrate embedding classical algorithmic priors into GNNs provides useful inductive biases, boosting performance on complex, real-world graph data.
Wavelet-Induced Rotary Encodings: RoPE Meets Graphs
Sep 26, 2025We introduce WIRE: Wavelet-Induced Rotary Encodings. WIRE extends Rotary Position Encodings (RoPE), a popular algorithm in LLMs and ViTs, to graph-structured data. We demonstrate that WIRE is more general than RoPE, recovering the latter in the special case of grid graphs. WIRE also enjoys a host of desirable theoretical properties, including equivariance under node ordering permutation, compatibility with linear attention, and (under select assumptions) asymptotic dependence on graph resistive distance. We test WIRE on a range of synthetic and real-world tasks, including identifying monochromatic subgraphs, semantic segmentation of point clouds, and more standard graph benchmarks. We find it to be effective in settings where the underlying graph structure is important.
KNARsack: Teaching Neural Algorithmic Reasoners to Solve Pseudo-Polynomial Problems
Sep 17, 2025Neural algorithmic reasoning (NAR) is a growing field that aims to embed algorithmic logic into neural networks by imitating classical algorithms. In this extended abstract, we detail our attempt to build a neural algorithmic reasoner that can solve Knapsack, a pseudo-polynomial problem bridging classical algorithms and combinatorial optimisation, but omitted in standard NAR benchmarks. Our neural algorithmic reasoner is designed to closely follow the two-phase pipeline for the Knapsack problem, which involves first constructing the dynamic programming table and then reconstructing the solution from it. The approach, which models intermediate states through dynamic programming supervision, achieves better generalization to larger problem instances than a direct-prediction baseline that attempts to select the optimal subset only from the problem inputs.
What makes a good feedforward computational graph?
Feb 10, 2025



As implied by the plethora of literature on graph rewiring, the choice of computational graph employed by a neural network can make a significant impact on its downstream performance. Certain effects related to the computational graph, such as under-reaching and over-squashing, may even render the model incapable of learning certain functions. Most of these effects have only been thoroughly studied in the domain of undirected graphs; however, recent years have seen a significant rise in interest in feedforward computational graphs: directed graphs without any back edges. In this paper, we study the desirable properties of a feedforward computational graph, discovering two important complementary measures: fidelity and mixing time, and evaluating a few popular choices of graphs through the lens of these measures. Our study is backed by both theoretical analyses of the metrics' asymptotic behaviour for various graphs, as well as correlating these metrics to the performance of trained neural network models using the corresponding graphs.
Amplifying human performance in combinatorial competitive programming
Nov 29, 2024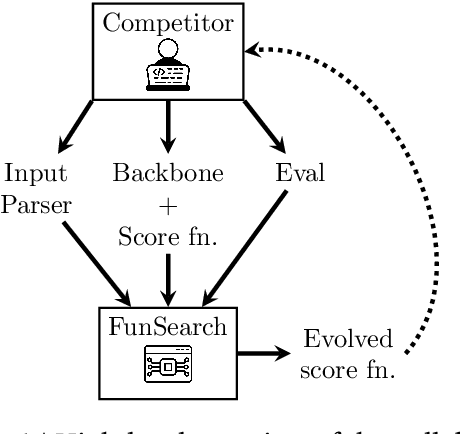

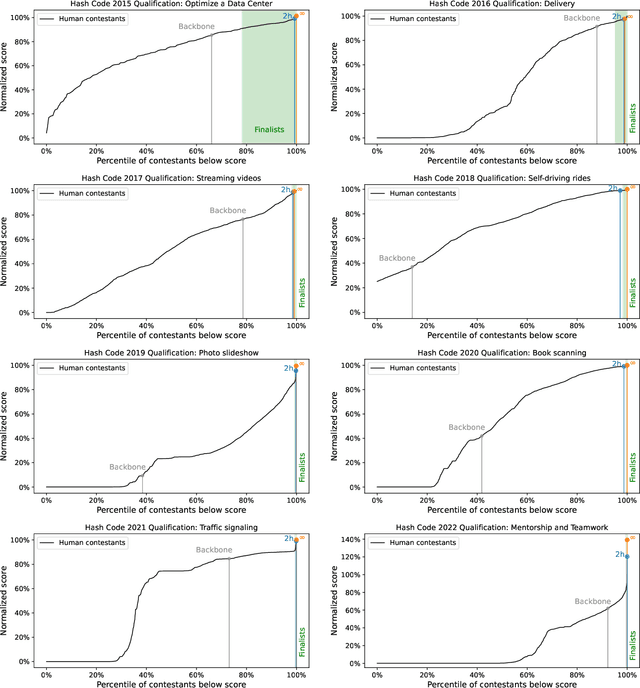
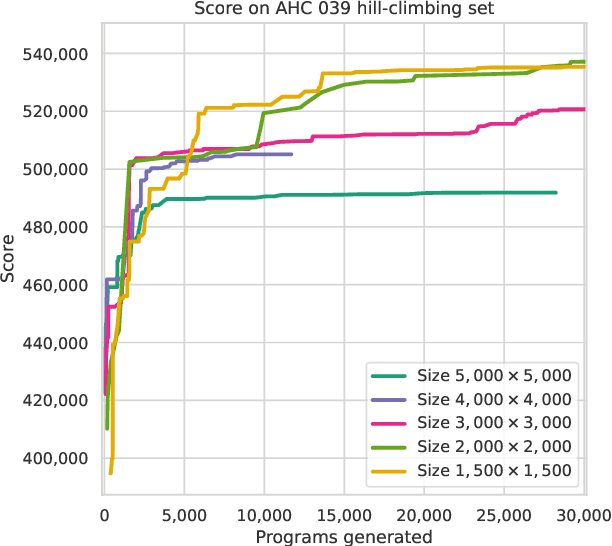
Recent years have seen a significant surge in complex AI systems for competitive programming, capable of performing at admirable levels against human competitors. While steady progress has been made, the highest percentiles still remain out of reach for these methods on standard competition platforms such as Codeforces. Here we instead focus on combinatorial competitive programming, where the target is to find as-good-as-possible solutions to otherwise computationally intractable problems, over specific given inputs. We hypothesise that this scenario offers a unique testbed for human-AI synergy, as human programmers can write a backbone of a heuristic solution, after which AI can be used to optimise the scoring function used by the heuristic. We deploy our approach on previous iterations of Hash Code, a global team programming competition inspired by NP-hard software engineering problems at Google, and we leverage FunSearch to evolve our scoring functions. Our evolved solutions significantly improve the attained scores from their baseline, successfully breaking into the top percentile on all previous Hash Code online qualification rounds, and outperforming the top human teams on several. Our method is also performant on an optimisation problem that featured in a recent held-out AtCoder contest.
NAR-*ICP: Neural Execution of Classical ICP-based Pointcloud Registration Algorithms
Oct 14, 2024



This study explores the intersection of neural networks and classical robotics algorithms through the Neural Algorithmic Reasoning (NAR) framework, allowing to train neural networks to effectively reason like classical robotics algorithms by learning to execute them. Algorithms are integral to robotics and safety-critical applications due to their predictable and consistent performance through logical and mathematical principles. In contrast, while neural networks are highly adaptable, handling complex, high-dimensional data and generalising across tasks, they often lack interpretability and transparency in their internal computations. We propose a Graph Neural Network (GNN)-based learning framework, NAR-*ICP, which learns the intermediate algorithmic steps of classical ICP-based pointcloud registration algorithms, and extend the CLRS Algorithmic Reasoning Benchmark with classical robotics perception algorithms. We evaluate our approach across diverse datasets, from real-world to synthetic, demonstrating its flexibility in handling complex and noisy inputs, along with its potential to be used as part of a larger learning system. Our results indicate that our method achieves superior performance across all benchmarks and datasets, consistently surpassing even the algorithms it has been trained on, further demonstrating its ability to generalise beyond the capabilities of traditional algorithms.