 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do LLMs Compute Verbal Confidence
Mar 18, 2026Verbal confidence -- prompting LLMs to state their confidence as a number or category -- is widely used to extract uncertainty estimates from black-box models. However, how LLMs internally generate such scores remains unknown. We address two questions: first, when confidence is computed - just-in-time when requested, or automatically during answer generation and cached for later retrieval; and second, what verbal confidence represents - token log-probabilities, or a richer evaluation of answer quality? Focusing on Gemma 3 27B and Qwen 2.5 7B, we provide convergent evidence for cached retrieval. Activation steering, patching, noising, and swap experiments reveal that confidence representations emerge at answer-adjacent positions before appearing at the verbalization site. Attention blocking pinpoints the information flow: confidence is gathered from answer tokens, cached at the first post-answer position, then retrieved for output. Critically, linear probing and variance partitioning reveal that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities, suggesting a richer answer-quality evaluation rather than a simple fluency readout. These findings demonstrate that verbal confidence reflects automatic, sophisticated self-evaluation -- not post-hoc reconstruction -- with implications for understanding metacognition in LLMs and improving calibration.
Perplexity Cannot Always Tell Right from Wrong
Jan 30, 2026Perplexity -- a function measuring a model's overall level of "surprise" when encountering a particular output -- has gained significant traction in recent years, both as a loss function and as a simple-to-compute metric of model quality. Prior studies have pointed out several limitations of perplexity, often from an empirical manner. Here we leverage recent results on Transformer continuity to show in a rigorous manner how perplexity may be an unsuitable metric for model selection. Specifically, we prove that, if there is any sequence that a compact decoder-only Transformer model predicts accurately and confidently -- a necessary pre-requisite for strong generalisation -- it must imply existence of another sequence with very low perplexity, but not predicted correctly by that same model. Further, by analytically studying iso-perplexity plots, we find that perplexity will not always select for the more accurate model -- rather, any increase in model confidence must be accompanied by a commensurate rise in accuracy for the new model to be selected.
Wavelet-Induced Rotary Encodings: RoPE Meets Graphs
Sep 26, 2025We introduce WIRE: Wavelet-Induced Rotary Encodings. WIRE extends Rotary Position Encodings (RoPE), a popular algorithm in LLMs and ViTs, to graph-structured data. We demonstrate that WIRE is more general than RoPE, recovering the latter in the special case of grid graphs. WIRE also enjoys a host of desirable theoretical properties, including equivariance under node ordering permutation, compatibility with linear attention, and (under select assumptions) asymptotic dependence on graph resistive distance. We test WIRE on a range of synthetic and real-world tasks, including identifying monochromatic subgraphs, semantic segmentation of point clouds, and more standard graph benchmarks. We find it to be effective in settings where the underlying graph structure is important.
Why do LLMs attend to the first token?
Apr 03, 2025Large Language Models (LLMs) tend to attend heavily to the first token in the sequence -- creating a so-called attention sink. Many works have studied this phenomenon in detail, proposing various ways to either leverage or alleviate it. Attention sinks have been connected to quantisation difficulties, security issues, and streaming attention. Yet, while many works have provided conditions in which they occur or not, a critical question remains shallowly answered: Why do LLMs learn such patterns and how are they being used? In this work, we argue theoretically and empirically that this mechanism provides a method for LLMs to avoid over-mixing, connecting this to existing lines of work that study mathematically how information propagates in Transformers. We conduct experiments to validate our theoretical intuitions and show how choices such as context length, depth, and data packing influence the sink behaviour. We hope that this study provides a new practical perspective on why attention sinks are useful in LLMs, leading to a better understanding of the attention patterns that form during training.
Interpreting the Repeated Token Phenomenon in Large Language Models
Mar 11, 2025



Large Language Models (LLMs), despite their impressive capabilities, often fail to accurately repeat a single word when prompted to, and instead output unrelated text. This unexplained failure mode represents a vulnerability, allowing even end-users to diverge models away from their intended behavior. We aim to explain the causes for this phenomenon and link it to the concept of ``attention sinks'', an emergent LLM behavior crucial for fluency, in which the initial token receives disproportionately high attention scores. Our investigation identifies the neural circuit responsible for attention sinks and shows how long repetitions disrupt this circuit. We extend this finding to other non-repeating sequences that exhibit similar circuit disruptions. To address this, we propose a targeted patch that effectively resolves the issue without negatively impacting the model's overall performance. This study provides a mechanistic explanation for an LLM vulnerability, demonstrating how interpretability can diagnose and address issues, and offering insights that pave the way for more secure and reliable models.
Enhancing the Expressivity of Temporal Graph Networks through Source-Target Identification
Nov 06, 2024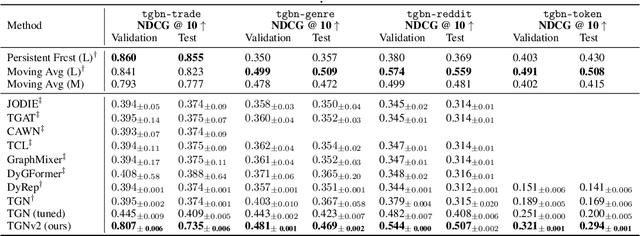
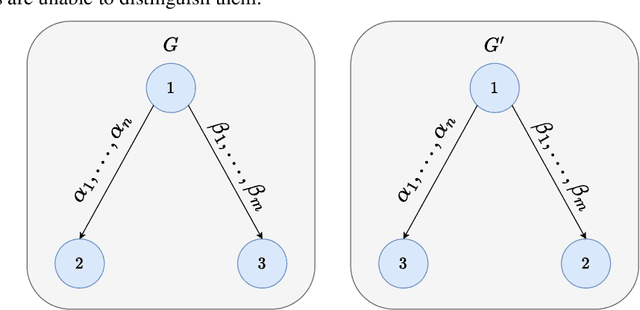

Despite the successful application of Temporal Graph Networks (TGNs) for tasks such as dynamic node classification and link prediction, they still perform poorly on the task of dynamic node affinity prediction -- where the goal is to predict `how much' two nodes will interact in the future. In fact, simple heuristic approaches such as persistent forecasts and moving averages over \emph{ground-truth labels} significantly and consistently outperform TGNs. Building on this observation, we find that computing heuristics \textit{over messages} is an equally competitive approach, outperforming TGN and all current temporal graph (TG) models on dynamic node affinity prediction. In this paper, we prove that no formulation of TGN can represent persistent forecasting or moving averages over messages, and propose to enhance the expressivity of TGNs by adding source-target identification to each interaction event message. We show that this modification is required to represent persistent forecasting, moving averages, and the broader class of autoregressive models over messages. Our proposed method, TGNv2, significantly outperforms TGN and all current TG models on all Temporal Graph Benchmark (TGB) dynamic node affinity prediction datasets.
Round and Round We Go! What makes Rotary Positional Encodings useful?
Oct 08, 2024Positional Encodings (PEs) are a critical component of Transformer-based Large Language Models (LLMs), providing the attention mechanism with important sequence-position information. One of the most popular types of encoding used today in LLMs are Rotary Positional Encodings (RoPE), that rotate the queries and keys based on their relative distance. A common belief is that RoPE is useful because it helps to decay token dependency as relative distance increases. In this work, we argue that this is unlikely to be the core reason. We study the internals of a trained Gemma 7B model to understand how RoPE is being used at a mechanical level. We find that Gemma learns to use RoPE to construct robust "positional" attention patterns by exploiting the highest frequencies. We also find that, in general, Gemma greatly prefers to use the lowest frequencies of RoPE, which we suspect are used to carry semantic information. We mathematically prove interesting behaviours of RoPE and conduct experiments to verify our findings, proposing a modification of RoPE that fixes some highlighted issues and improves performance. We believe that this work represents an interesting step in better understanding PEs in LLMs, which we believe holds crucial value for scaling LLMs to large sizes and context lengths.
softmax is not enough (for sharp out-of-distribution)
Oct 01, 2024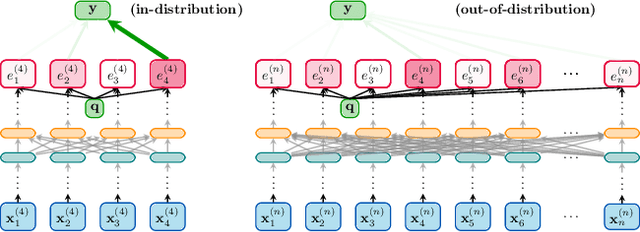

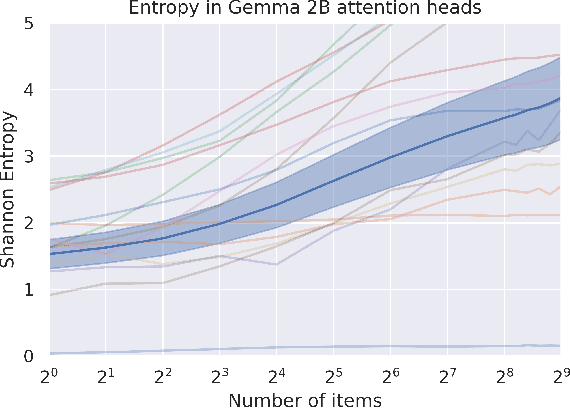
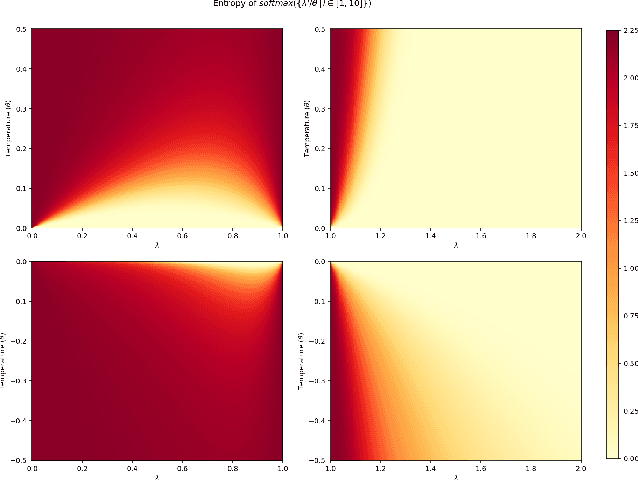
A key property of reasoning systems is the ability to make sharp decisions on their input data. For contemporary AI systems, a key carrier of sharp behaviour is the softmax function, with its capability to perform differentiable query-key lookups. It is a common belief that the predictive power of networks leveraging softmax arises from "circuits" which sharply perform certain kinds of computations consistently across many diverse inputs. However, for these circuits to be robust, they would need to generalise well to arbitrary valid inputs. In this paper, we dispel this myth: even for tasks as simple as finding the maximum key, any learned circuitry must disperse as the number of items grows at test time. We attribute this to a fundamental limitation of the softmax function to robustly approximate sharp functions, prove this phenomenon theoretically, and propose adaptive temperature as an ad-hoc technique for improving the sharpness of softmax at inference time.
Transformers need glasses! Information over-squashing in language tasks
Jun 06, 2024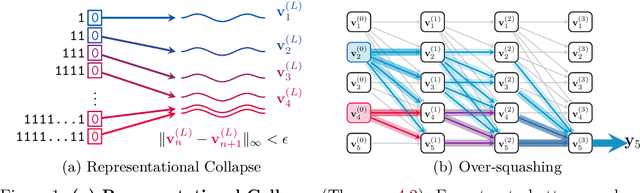

We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Bundle Neural Networks for message diffusion on graphs
May 24, 2024
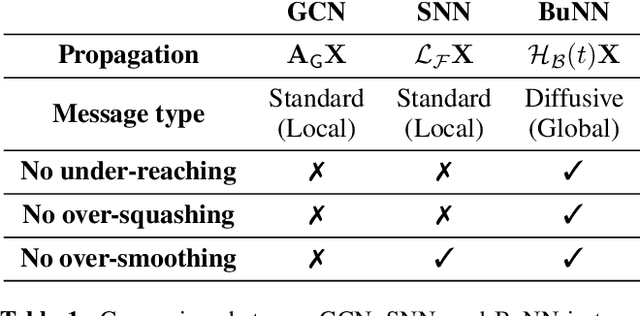
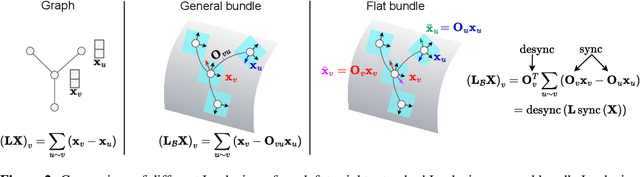
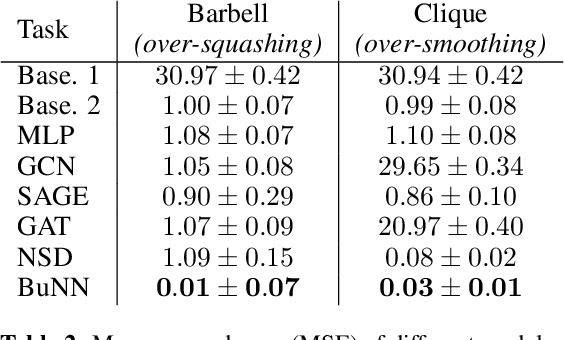
The dominant paradigm for learning on graph-structured data is message passing. Despite being a strong inductive bias, the local message passing mechanism suffers from pathological issues such as over-smoothing, over-squashing, and limited node-level expressivity. To address these limitations we propose Bundle Neural Networks (BuNN), a new type of GNN that operates via message diffusion over flat vector bundles - structures analogous to connections on Riemannian manifolds that augment the graph by assigning to each node a vector space and an orthogonal map. A BuNN layer evolves the features according to a diffusion-type partial differential equation. When discretized, BuNNs are a special case of Sheaf Neural Networks (SNNs), a recently proposed MPNN capable of mitigating over-smoothing. The continuous nature of message diffusion enables BuNNs to operate on larger scales of the graph and, therefore, to mitigate over-squashing. Finally, we prove that BuNN can approximate any feature transformation over nodes on any (potentially infinite) family of graphs given injective positional encodings, resulting in universal node-level expressivity. We support our theory via synthetic experiments and showcase the strong empirical performance of BuNNs over a range of real-world tasks, achieving state-of-the-art results on several standard benchmarks in transductive and inductive settings.