 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers need glasses! Information over-squashing in language tasks
Jun 06, 2024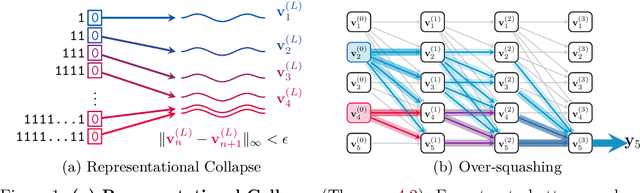

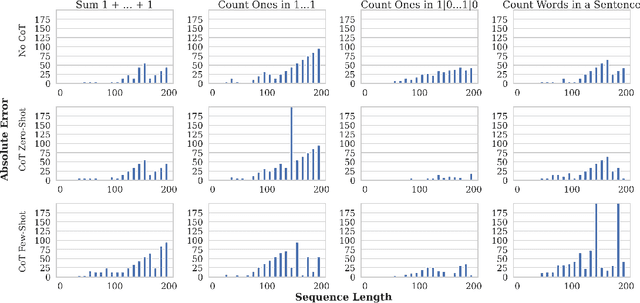
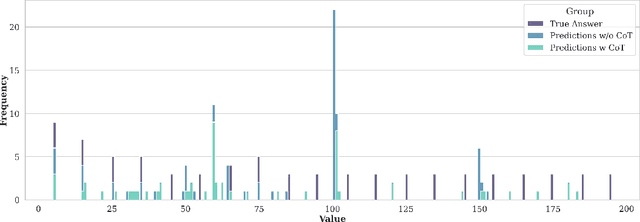
We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024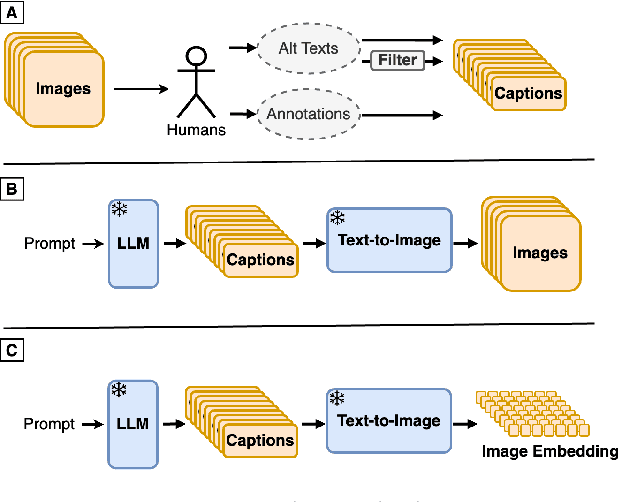
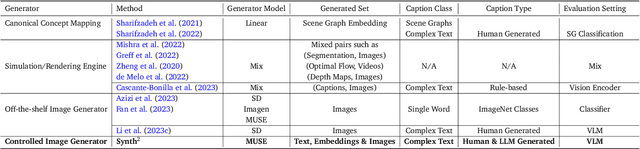


The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
Transformers generalize differently from information stored in context vs in weights
Oct 11, 2022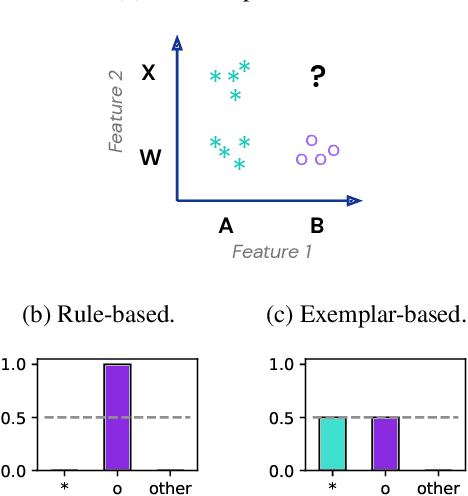
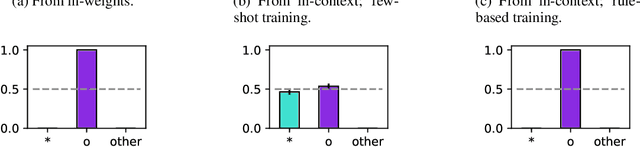
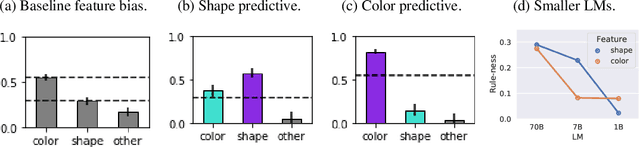
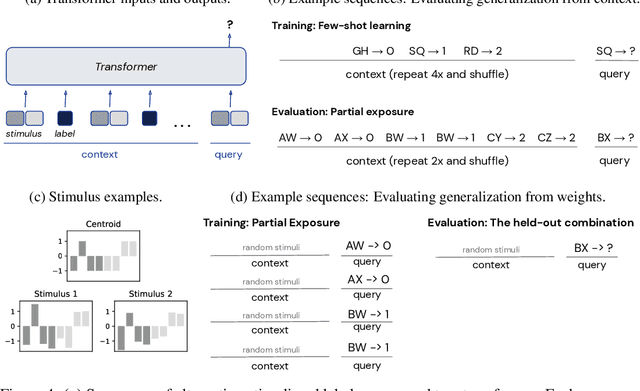
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
Language models show human-like content effects on reasoning
Jul 14, 2022



Abstract reasoning is a key ability for an intelligent system. Large language models achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human abstract reasoning is also imperfect, and depends on our knowledge and beliefs about the content of the reasoning problem. For example, humans reason much more reliably about logical rules that are grounded in everyday situations than arbitrary rules about abstract attributes. The training experiences of language models similarly endow them with prior expectations that reflect human knowledge and beliefs. We therefore hypothesized that language models would show human-like content effects on abstract reasoning problems. We explored this hypothesis across three logical reasoning tasks: natural language inference, judging the logical validity of syllogisms, and the Wason selection task (Wason, 1968). We find that state of the art large language models (with 7 or 70 billion parameters; Hoffman et al., 2022) reflect many of the same patterns observed in humans across these tasks -- like humans, models reason more effectively about believable situations than unrealistic or abstract ones. Our findings have implications for understanding both these cognitive effects, and the factors that contribute to language model performance.
MEMO: A Deep Network for Flexible Combination of Episodic Memories
Jan 29, 2020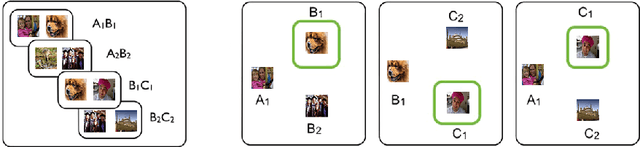
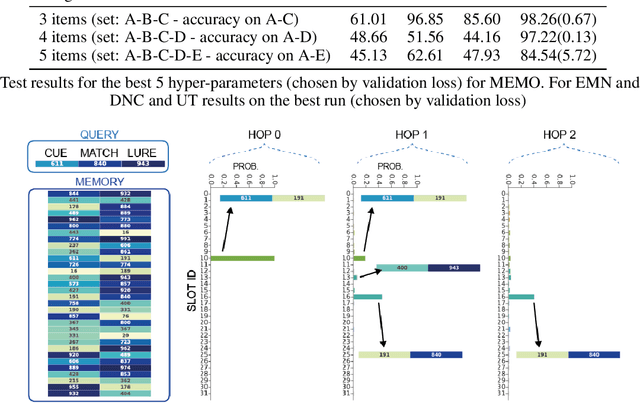
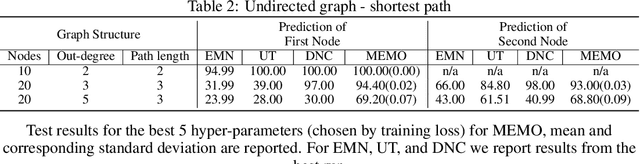

Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures. This task is thought to capture the essence of reasoning -- the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances. This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI.
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Dec 05, 2017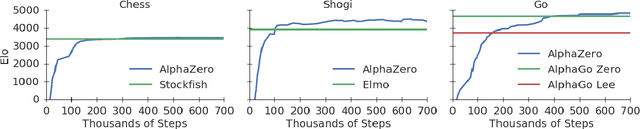
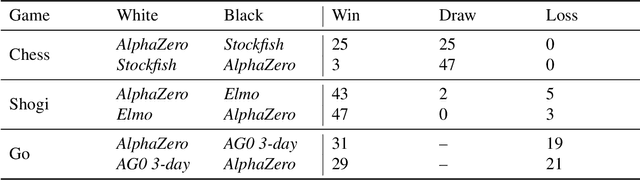
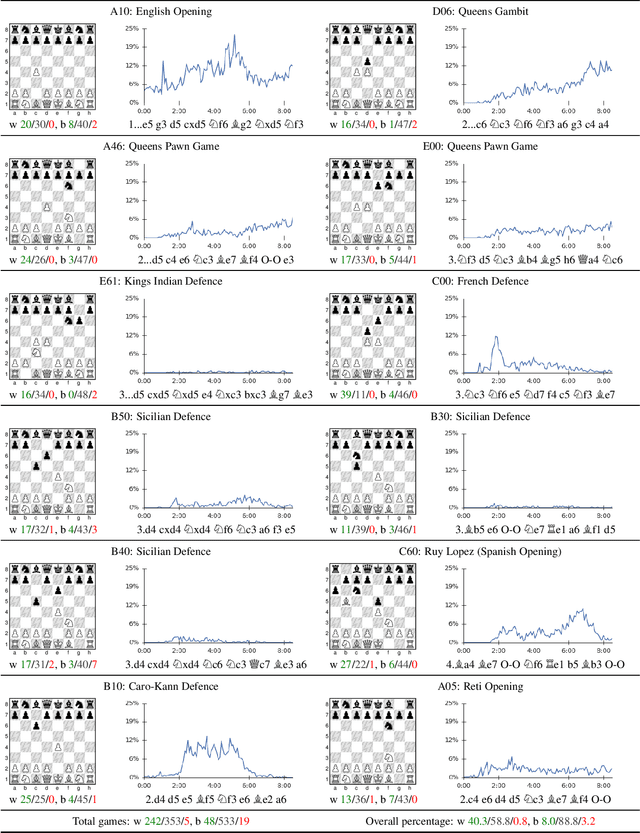
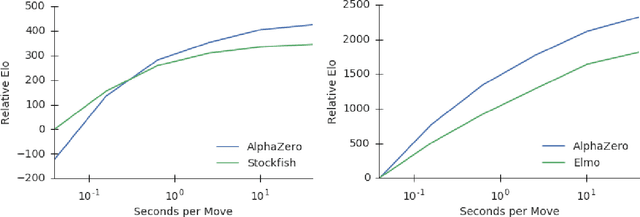
The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017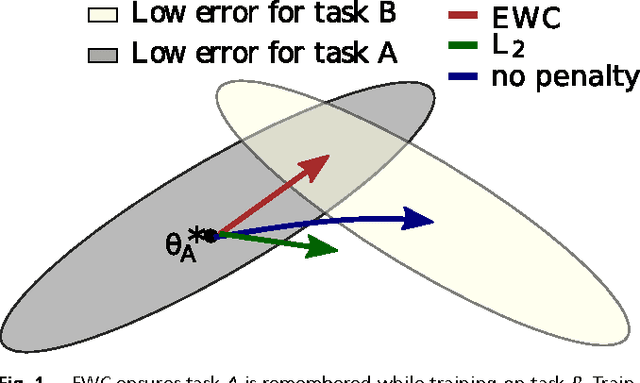
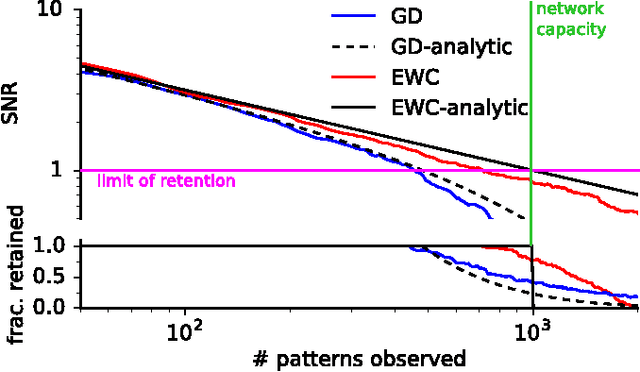
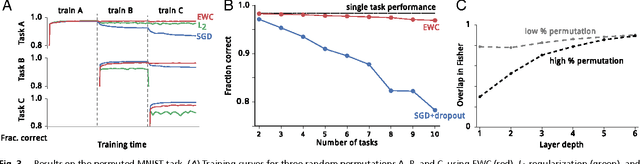
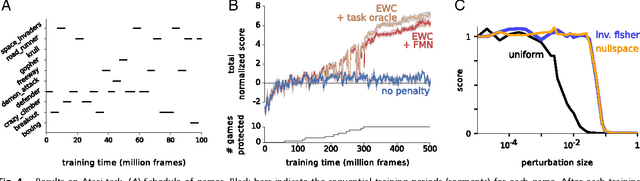
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
Learning to reinforcement learn
Jan 23, 2017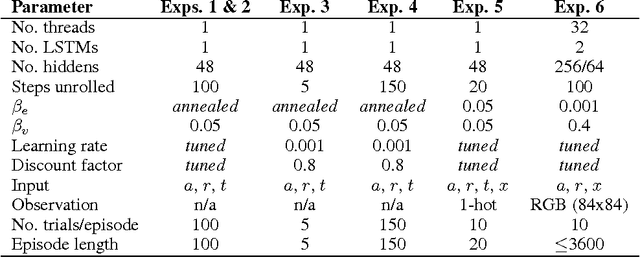
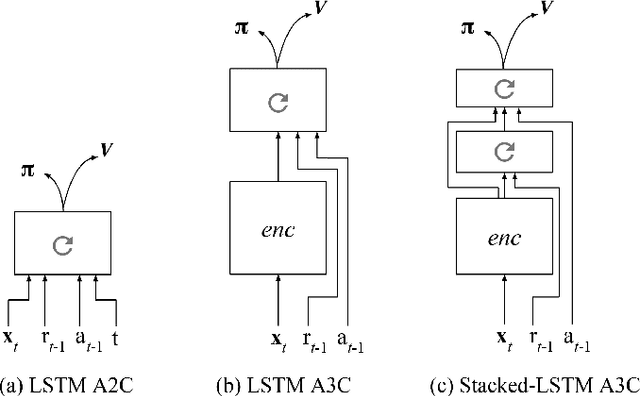
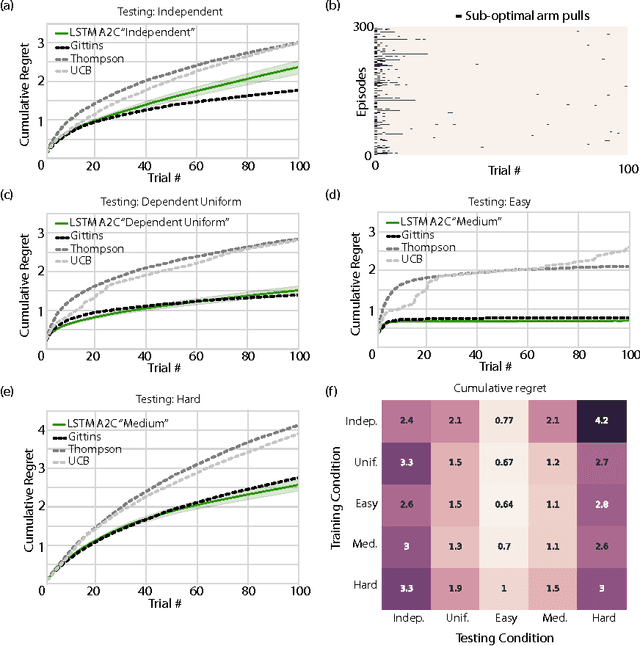
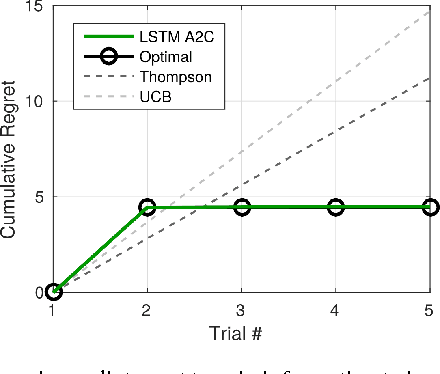
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.
Learning to Navigate in Complex Environments
Jan 13, 2017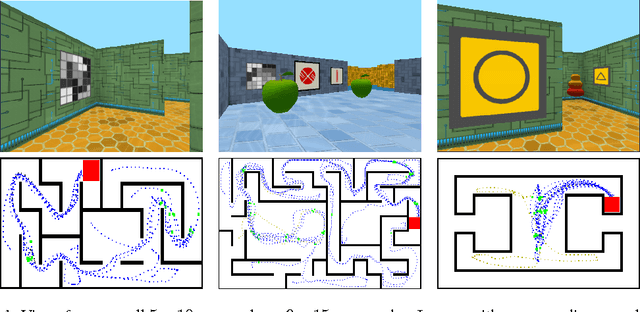
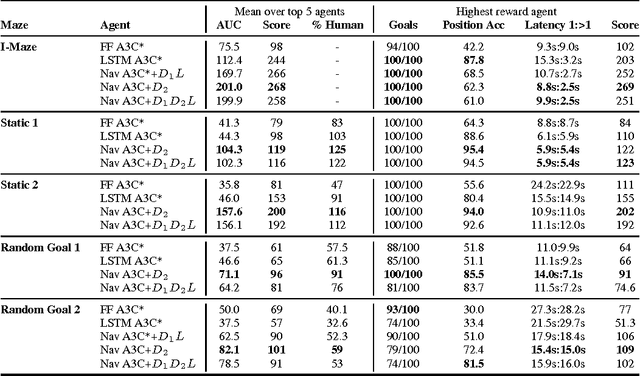
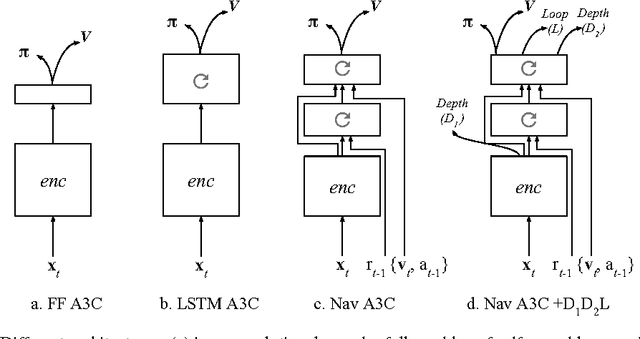
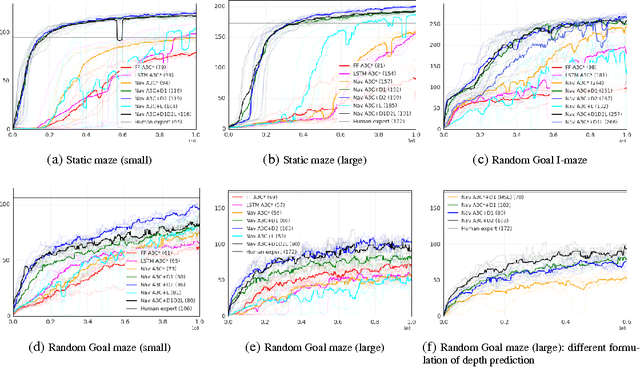
Learning to navigate in complex environments with dynamic elements is an important milestone in developing AI agents. In this work we formulate the navigation question as a reinforcement learning problem and show that data efficiency and task performance can be dramatically improved by relying on additional auxiliary tasks leveraging multimodal sensory inputs. In particular we consider jointly learning the goal-driven reinforcement learning problem with auxiliary depth prediction and loop closure classification tasks. This approach can learn to navigate from raw sensory input in complicated 3D mazes, approaching human-level performance even under conditions where the goal location changes frequently. We provide detailed analysis of the agent behaviour, its ability to localise, and its network activity dynamics, showing that the agent implicitly learns key navigation abilities.