 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Force Fields Are Ready For Ground State Catalyst Discovery
Sep 26, 2022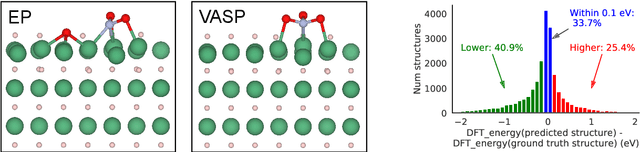
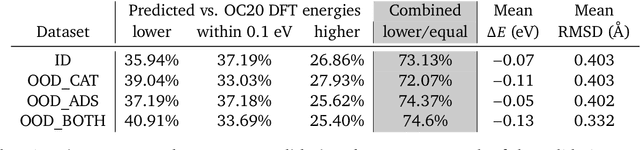
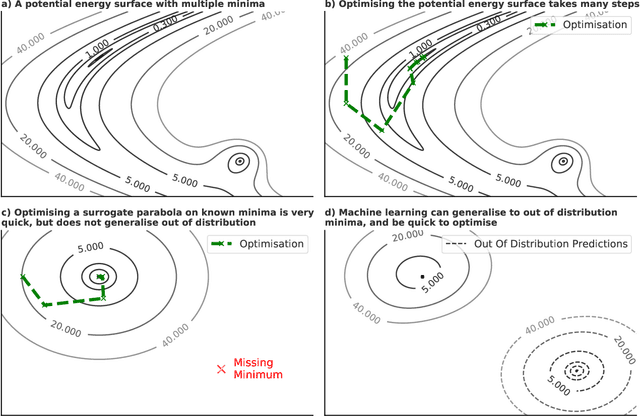
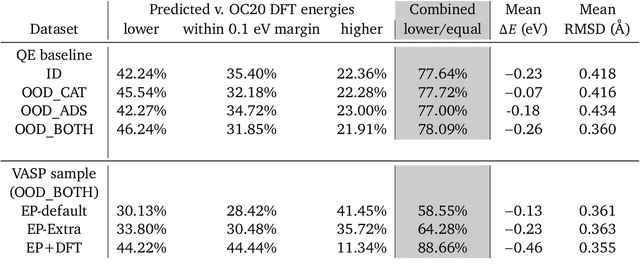
We present evidence that learned density functional theory (``DFT'') force fields are ready for ground state catalyst discovery. Our key finding is that relaxation using forces from a learned potential yields structures with similar or lower energy to those relaxed using the RPBE functional in over 50\% of evaluated systems, despite the fact that the predicted forces differ significantly from the ground truth. This has the surprising implication that learned potentials may be ready for replacing DFT in challenging catalytic systems such as those found in the Open Catalyst 2020 dataset. Furthermore, we show that a force field trained on a locally harmonic energy surface with the same minima as a target DFT energy is also able to find lower or similar energy structures in over 50\% of cases. This ``Easy Potential'' converges in fewer steps than a standard model trained on true energies and forces, which further accelerates calculations. Its success illustrates a key point: learned potentials can locate energy minima even when the model has high force errors. The main requirement for structure optimisation is simply that the learned potential has the correct minima. Since learned potentials are fast and scale linearly with system size, our results open the possibility of quickly finding ground states for large systems.
Very Deep Graph Neural Networks Via Noise Regularisation
Jun 15, 2021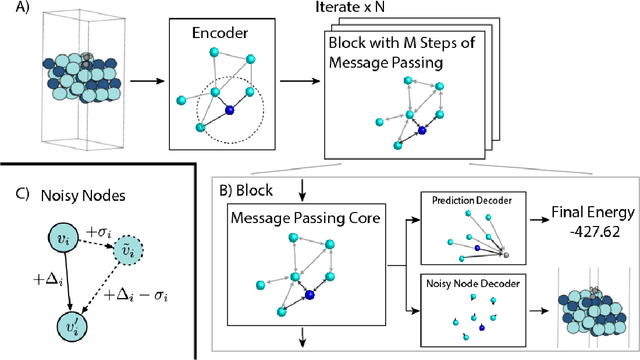
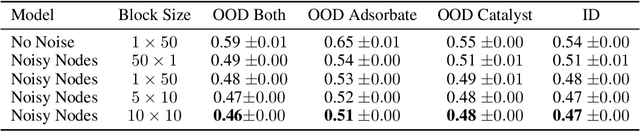
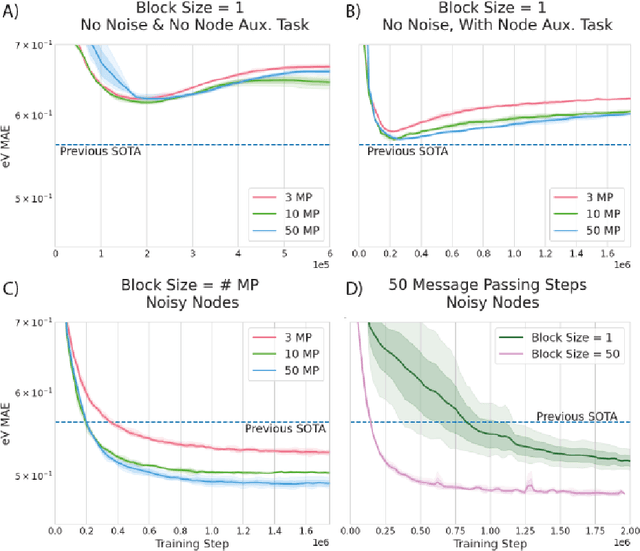
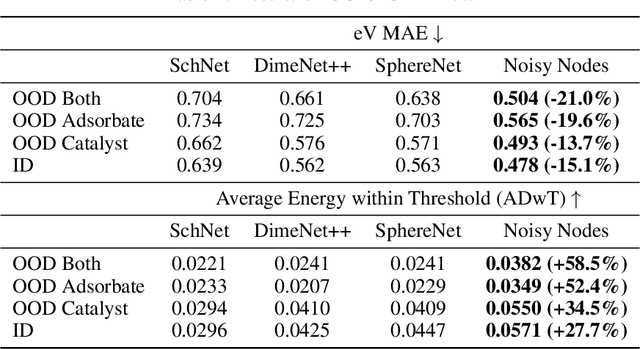
Graph Neural Networks (GNNs) perform learned message passing over an input graph, but conventional wisdom says performing more than handful of steps makes training difficult and does not yield improved performance. Here we show the contrary. We train a deep GNN with up to 100 message passing steps and achieve several state-of-the-art results on two challenging molecular property prediction benchmarks, Open Catalyst 2020 IS2RE and QM9. Our approach depends crucially on a novel but simple regularisation method, which we call ``Noisy Nodes'', in which we corrupt the input graph with noise and add an auxiliary node autoencoder loss if the task is graph property prediction. Our results show this regularisation method allows the model to monotonically improve in performance with increased message passing steps. Our work opens new opportunities for reaping the benefits of deep neural networks in the space of graph and other structured prediction problems.
Distral: Robust Multitask Reinforcement Learning
Jul 13, 2017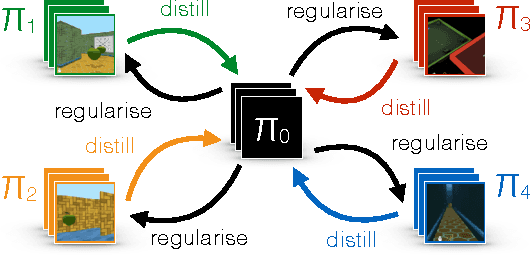

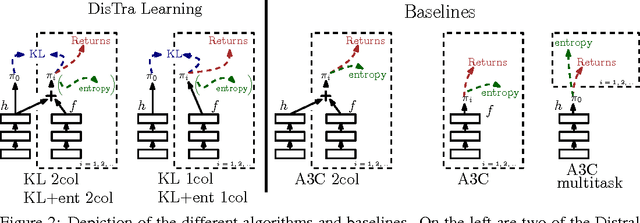
Most deep reinforcement learning algorithms are data inefficient in complex and rich environments, limiting their applicability to many scenarios. One direction for improving data efficiency is multitask learning with shared neural network parameters, where efficiency may be improved through transfer across related tasks. In practice, however, this is not usually observed, because gradients from different tasks can interfere negatively, making learning unstable and sometimes even less data efficient. Another issue is the different reward schemes between tasks, which can easily lead to one task dominating the learning of a shared model. We propose a new approach for joint training of multiple tasks, which we refer to as Distral (Distill & transfer learning). Instead of sharing parameters between the different workers, we propose to share a "distilled" policy that captures common behaviour across tasks. Each worker is trained to solve its own task while constrained to stay close to the shared policy, while the shared policy is trained by distillation to be the centroid of all task policies. Both aspects of the learning process are derived by optimizing a joint objective function. We show that our approach supports efficient transfer on complex 3D environments, outperforming several related methods. Moreover, the proposed learning process is more robust and more stable---attributes that are critical in deep reinforcement learning.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017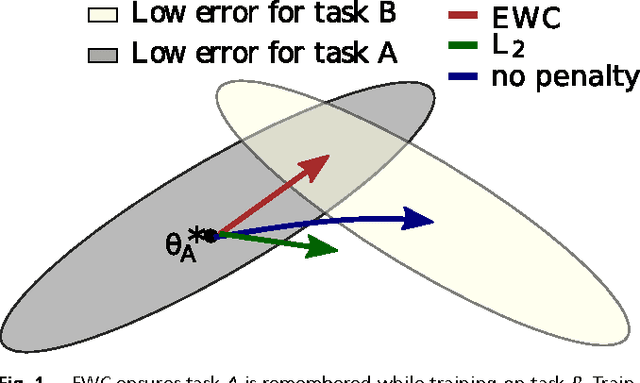
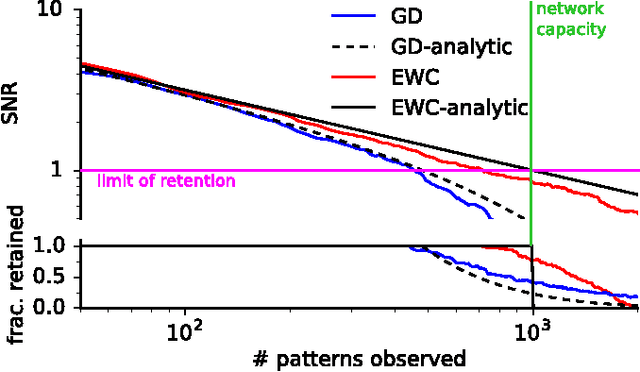
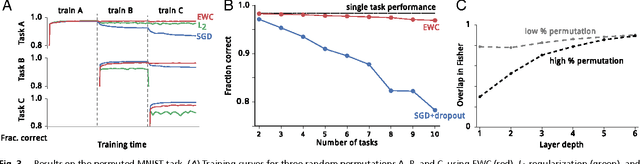
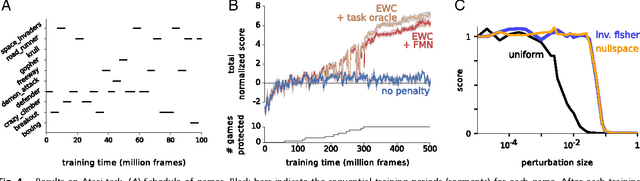
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
Progressive Neural Networks
Sep 07, 2016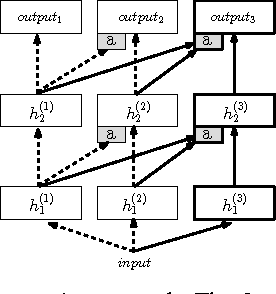
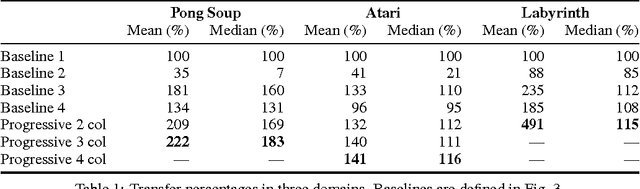

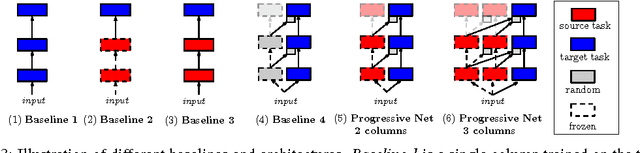
Learning to solve complex sequences of tasks--while both leveraging transfer and avoiding catastrophic forgetting--remains a key obstacle to achieving human-level intelligence. The progressive networks approach represents a step forward in this direction: they are immune to forgetting and can leverage prior knowledge via lateral connections to previously learned features. We evaluate this architecture extensively on a wide variety of reinforcement learning tasks (Atari and 3D maze games), and show that it outperforms common baselines based on pretraining and finetuning. Using a novel sensitivity measure, we demonstrate that transfer occurs at both low-level sensory and high-level control layers of the learned policy.
Policy Distillation
Jan 07, 2016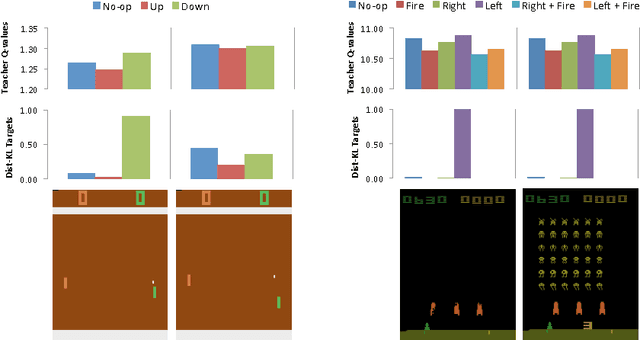
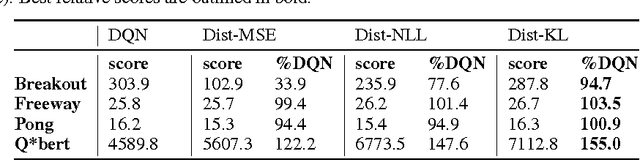
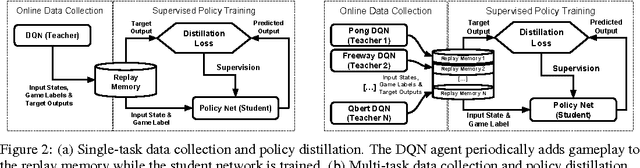
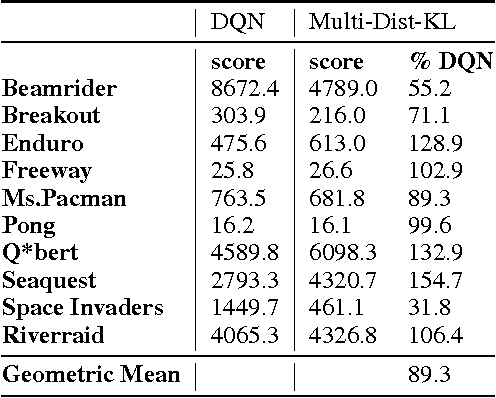
Policies for complex visual tasks have been successfully learned with deep reinforcement learning, using an approach called deep Q-networks (DQN), but relatively large (task-specific) networks and extensive training are needed to achieve good performance. In this work, we present a novel method called policy distillation that can be used to extract the policy of a reinforcement learning agent and train a new network that performs at the expert level while being dramatically smaller and more efficient. Furthermore, the same method can be used to consolidate multiple task-specific policies into a single policy. We demonstrate these claims using the Atari domain and show that the multi-task distilled agent outperforms the single-task teachers as well as a jointly-trained DQN agent.