 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025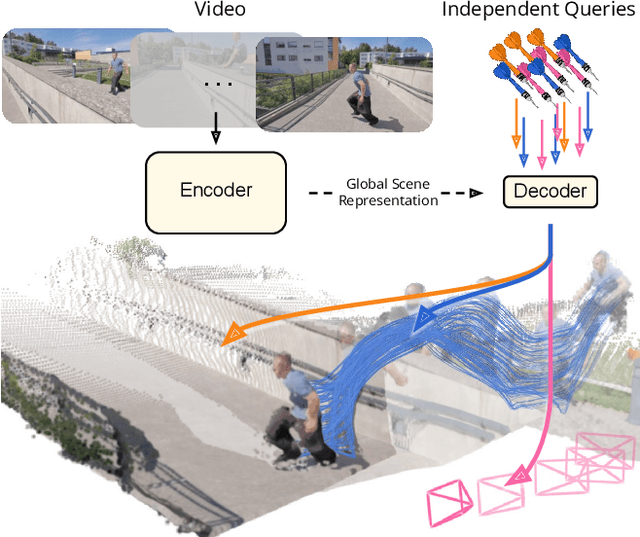

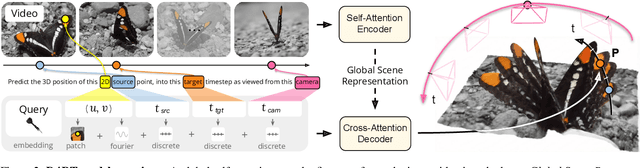
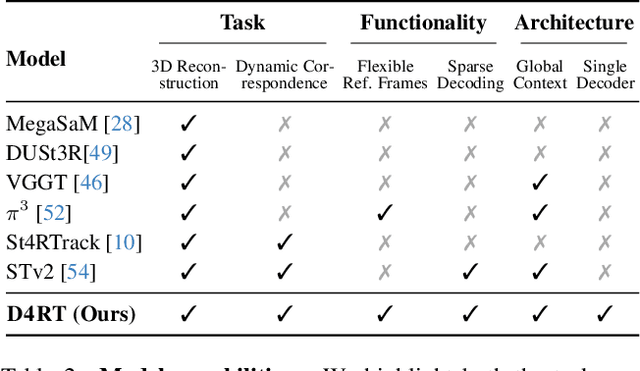
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023



For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
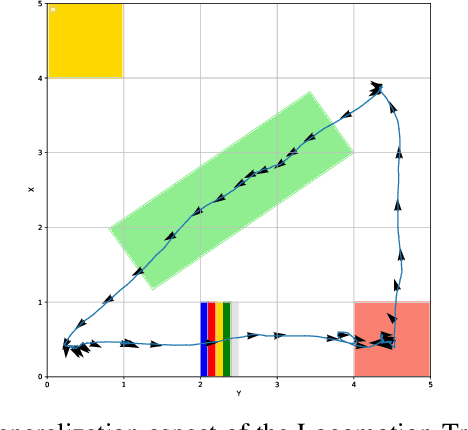
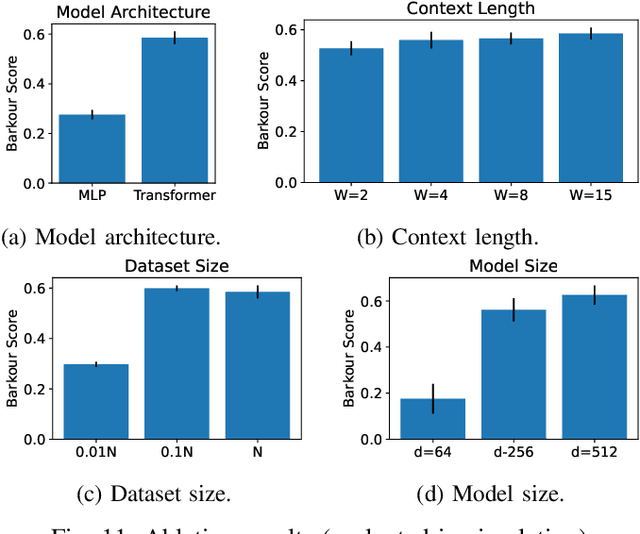

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
MO2: Model-Based Offline Options
Sep 05, 2022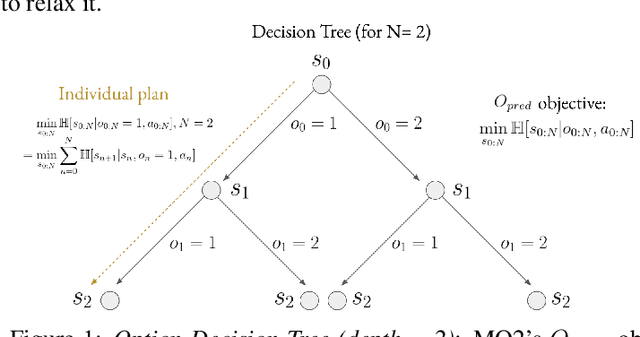

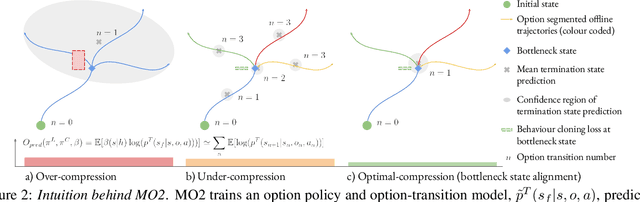
The ability to discover useful behaviours from past experience and transfer them to new tasks is considered a core component of natural embodied intelligence. Inspired by neuroscience, discovering behaviours that switch at bottleneck states have been long sought after for inducing plans of minimum description length across tasks. Prior approaches have either only supported online, on-policy, bottleneck state discovery, limiting sample-efficiency, or discrete state-action domains, restricting applicability. To address this, we introduce Model-Based Offline Options (MO2), an offline hindsight framework supporting sample-efficient bottleneck option discovery over continuous state-action spaces. Once bottleneck options are learnt offline over source domains, they are transferred online to improve exploration and value estimation on the transfer domain. Our experiments show that on complex long-horizon continuous control tasks with sparse, delayed rewards, MO2's properties are essential and lead to performance exceeding recent option learning methods. Additional ablations further demonstrate the impact on option predictability and credit assignment.
The CLRS Algorithmic Reasoning Benchmark
Jun 04, 2022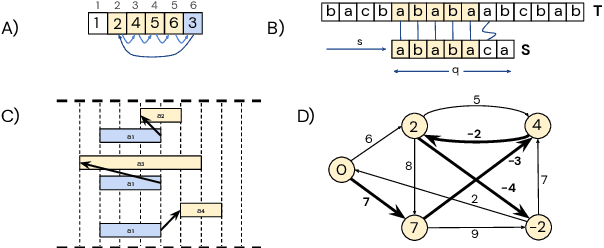
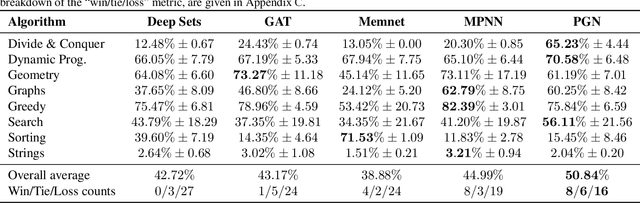

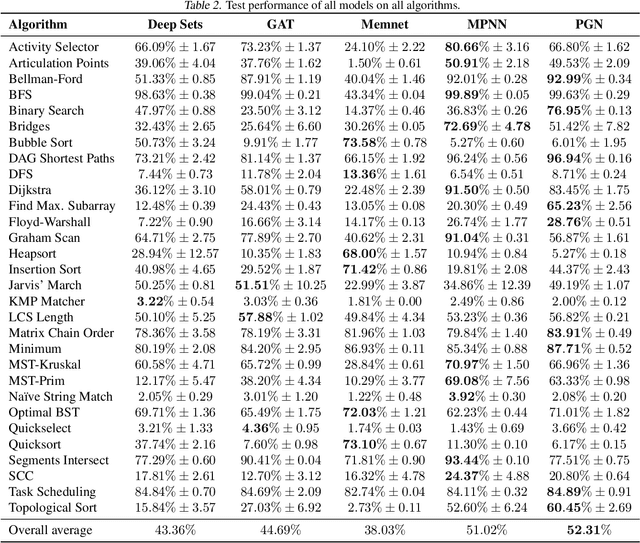
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms. Several important works have investigated whether neural networks can effectively reason like algorithms, typically by learning to execute them. The common trend in the area, however, is to generate targeted kinds of algorithmic data to evaluate specific hypotheses, making results hard to transfer across publications, and increasing the barrier of entry. To consolidate progress and work towards unified evaluation, we propose the CLRS Algorithmic Reasoning Benchmark, covering classical algorithms from the Introduction to Algorithms textbook. Our benchmark spans a variety of algorithmic reasoning procedures, including sorting, searching, dynamic programming, graph algorithms, string algorithms and geometric algorithms. We perform extensive experiments to demonstrate how several popular algorithmic reasoning baselines perform on these tasks, and consequently, highlight links to several open challenges. Our library is readily available at https://github.com/deepmind/clrs.