 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo
Dec 01, 2022We introduce MuJoCo MPC (MJPC), an open-source, interactive application and software framework for real-time predictive control, based on MuJoCo physics. MJPC allows the user to easily author and solve complex robotics tasks, and currently supports three shooting-based planners: derivative-based iLQG and Gradient Descent, and a simple derivative-free method we call Predictive Sampling. Predictive Sampling was designed as an elementary baseline, mostly for its pedagogical value, but turned out to be surprisingly competitive with the more established algorithms. This work does not present algorithmic advances, and instead, prioritises performant algorithms, simple code, and accessibility of model-based methods via intuitive and interactive software. MJPC is available at: github.com/deepmind/mujoco_mpc, a video summary can be viewed at: dpmd.ai/mjpc.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022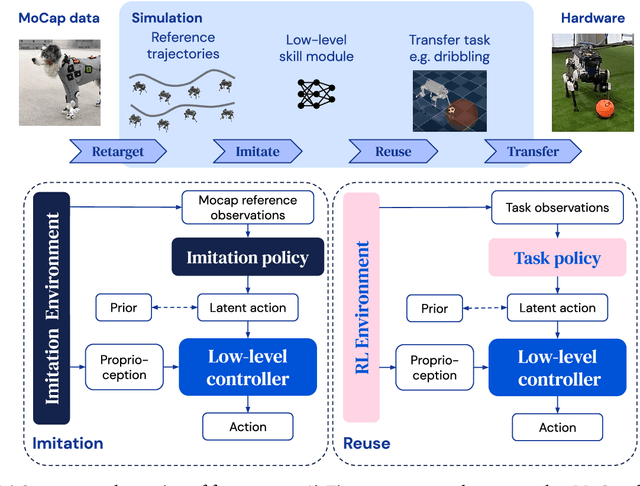

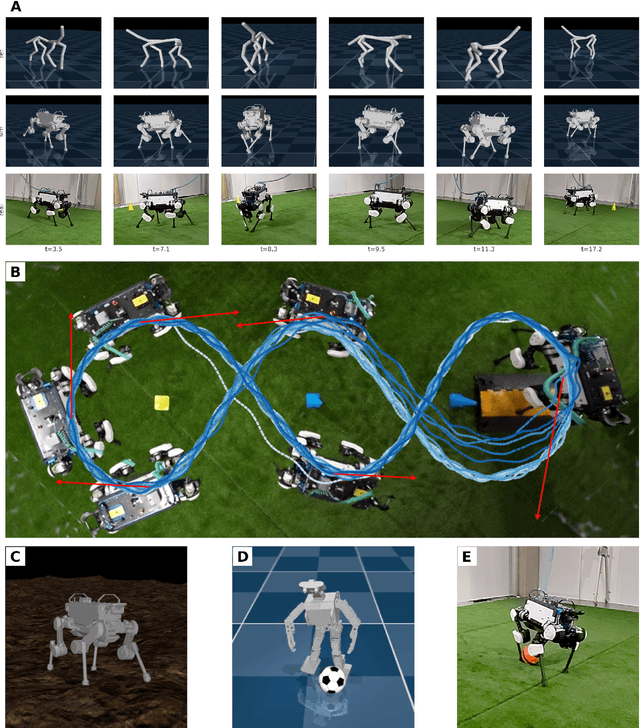
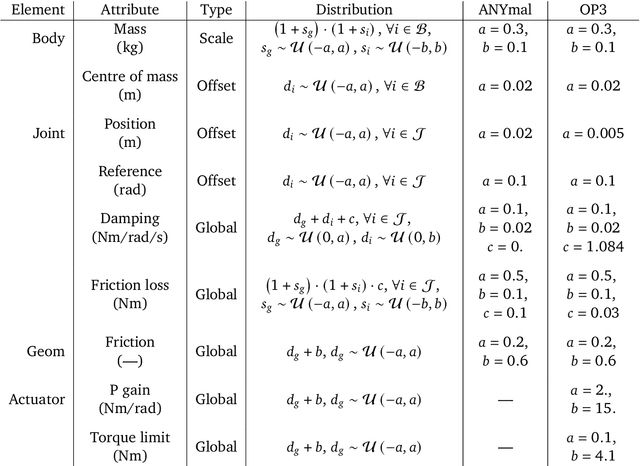
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021

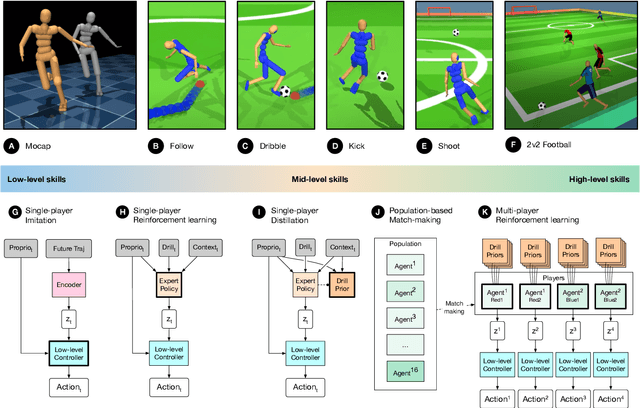

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Physically Embedded Planning Problems: New Challenges for Reinforcement Learning
Sep 11, 2020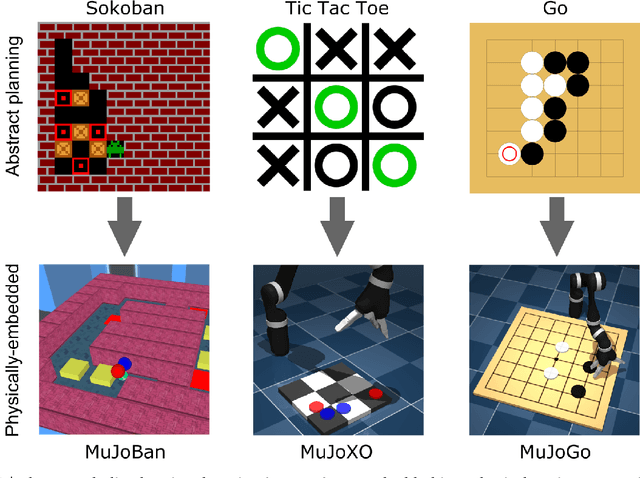


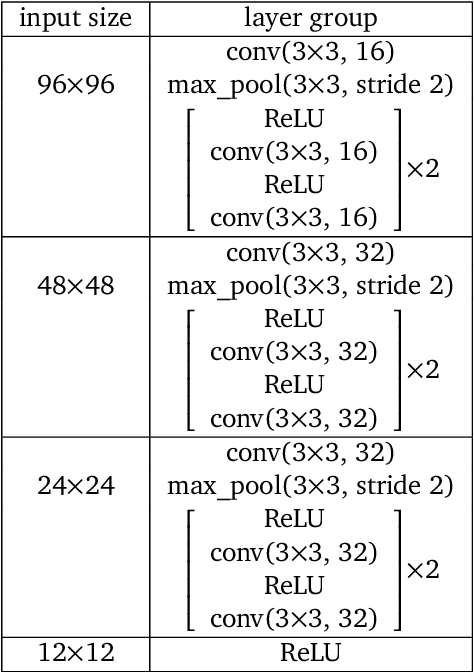
Recent work in deep reinforcement learning (RL) has produced algorithms capable of mastering challenging games such as Go, chess, or shogi. In these works the RL agent directly observes the natural state of the game and controls that state directly with its actions. However, when humans play such games, they do not just reason about the moves but also interact with their physical environment. They understand the state of the game by looking at the physical board in front of them and modify it by manipulating pieces using touch and fine-grained motor control. Mastering complicated physical systems with abstract goals is a central challenge for artificial intelligence, but it remains out of reach for existing RL algorithms. To encourage progress towards this goal we introduce a set of physically embedded planning problems and make them publicly available. We embed challenging symbolic tasks (Sokoban, tic-tac-toe, and Go) in a physics engine to produce a set of tasks that require perception, reasoning, and motor control over long time horizons. Although existing RL algorithms can tackle the symbolic versions of these tasks, we find that they struggle to master even the simplest of their physically embedded counterparts. As a first step towards characterizing the space of solution to these tasks, we introduce a strong baseline that uses a pre-trained expert game player to provide hints in the abstract space to an RL agent's policy while training it on the full sensorimotor control task. The resulting agent solves many of the tasks, underlining the need for methods that bridge the gap between abstract planning and embodied control.
Towards General and Autonomous Learning of Core Skills: A Case Study in Locomotion
Aug 06, 2020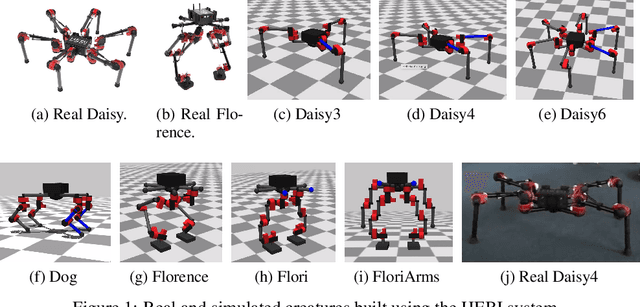
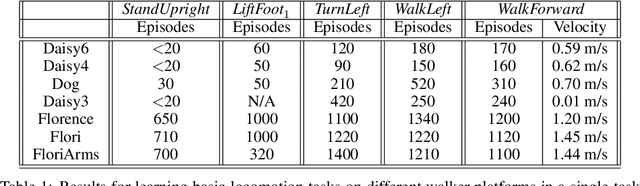
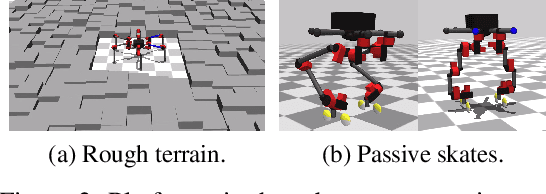

Modern Reinforcement Learning (RL) algorithms promise to solve difficult motor control problems directly from raw sensory inputs. Their attraction is due in part to the fact that they can represent a general class of methods that allow to learn a solution with a reasonably set reward and minimal prior knowledge, even in situations where it is difficult or expensive for a human expert. For RL to truly make good on this promise, however, we need algorithms and learning setups that can work across a broad range of problems with minimal problem specific adjustments or engineering. In this paper, we study this idea of generality in the locomotion domain. We develop a learning framework that can learn sophisticated locomotion behavior for a wide spectrum of legged robots, such as bipeds, tripeds, quadrupeds and hexapods, including wheeled variants. Our learning framework relies on a data-efficient, off-policy multi-task RL algorithm and a small set of reward functions that are semantically identical across robots. To underline the general applicability of the method, we keep the hyper-parameter settings and reward definitions constant across experiments and rely exclusively on on-board sensing. For nine different types of robots, including a real-world quadruped robot, we demonstrate that the same algorithm can rapidly learn diverse and reusable locomotion skills without any platform specific adjustments or additional instrumentation of the learning setup.
dm_control: Software and Tasks for Continuous Control
Jun 22, 2020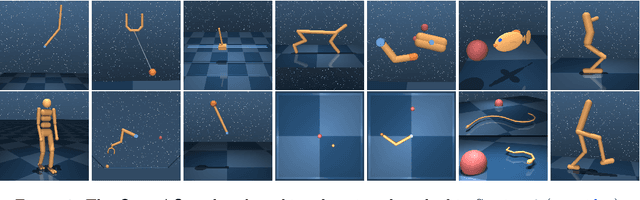

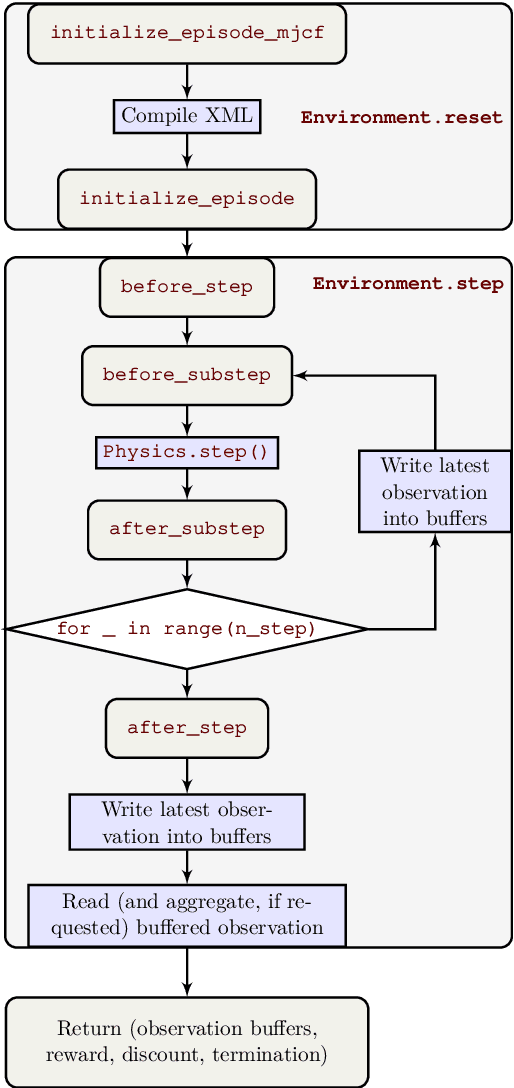
The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures. The PyMJCF and Composer libraries enable procedural model manipulation and task authoring. The Control Suite is a fixed set of tasks with standardised structure, intended to serve as performance benchmarks. The Locomotion framework provides high-level abstractions and examples of locomotion tasks. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included. dm_control is publicly available at https://www.github.com/deepmind/dm_control
Reusable neural skill embeddings for vision-guided whole body movement and object manipulation
Nov 15, 2019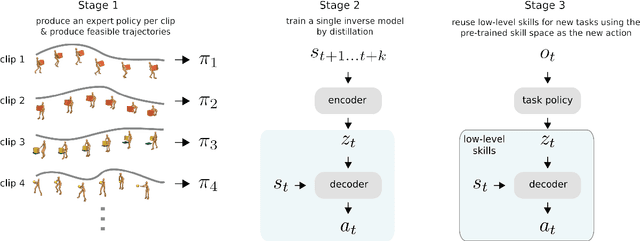
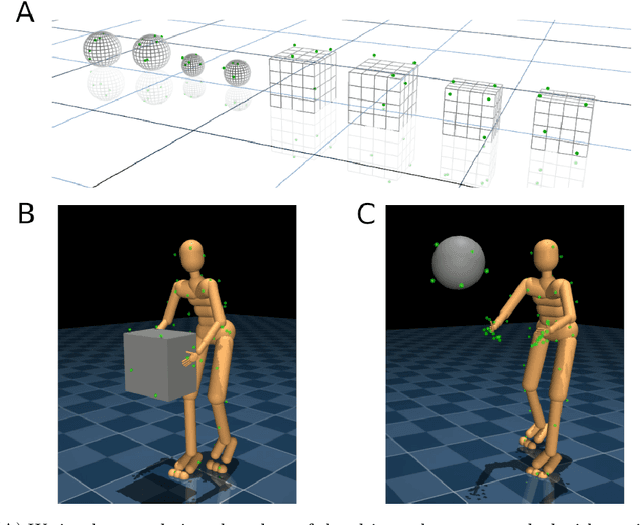
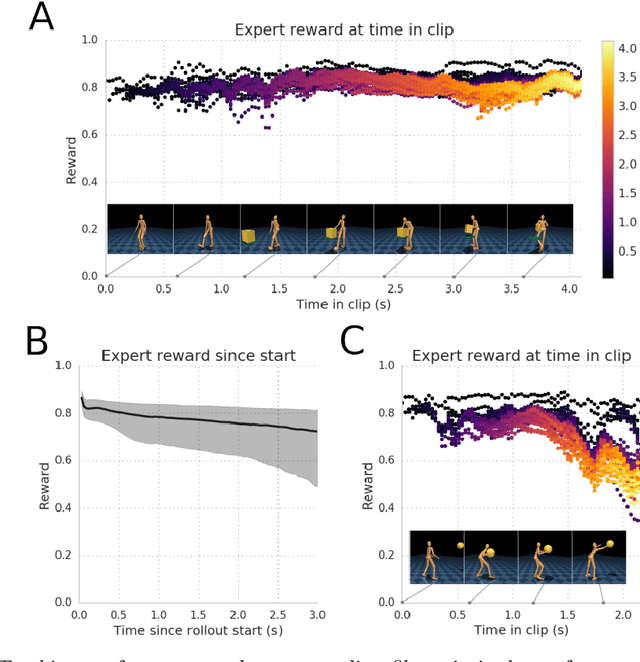
Both in simulation settings and robotics, there is an ambition to produce flexible control systems that can enable complex bodies to perform dynamic locomotion and natural object manipulation. In previous work, we developed a framework to train locomotor skills and reuse these skills for whole-body visuomotor tasks. Here, we extend this line of work to tasks involving whole body movement as well as visually guided manipulation of objects. This setting poses novel challenges in terms of task specification, exploration, and generalization. We develop an integrated approach consisting of a flexible motor primitive module, demonstrations, an instructed training regime as well as curricula in the form of task variations. We demonstrate the utility of our approach for solving challenging whole body tasks that require joint locomotion and manipulation, and characterize its behavioral robustness. We also provide a high-level overview video, see https://youtu.be/t0RDGSnE3cM .
Emergent Coordination Through Competition
Feb 21, 2019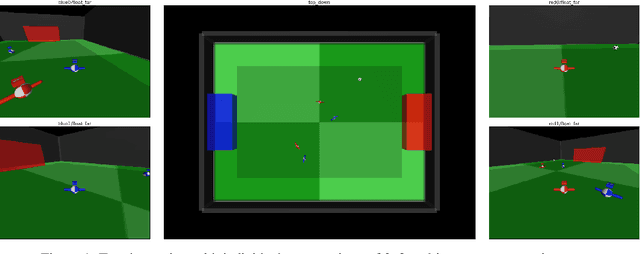
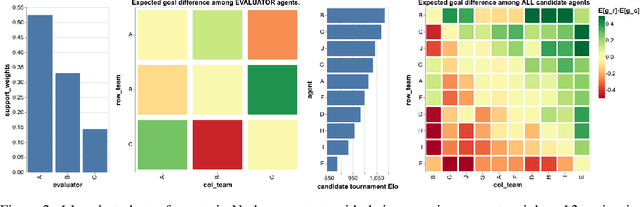
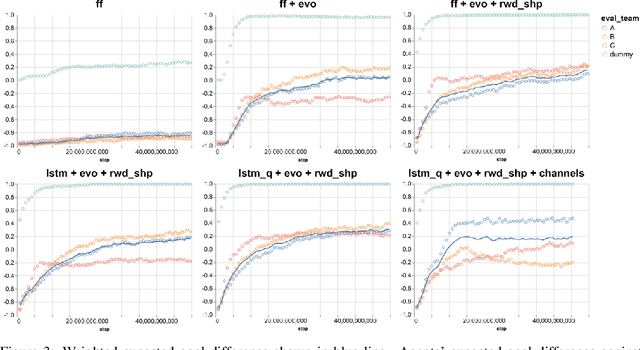
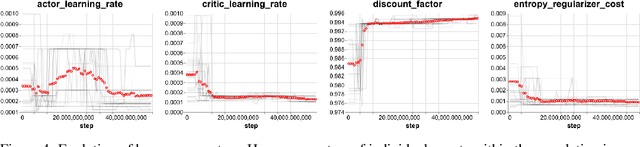
We study the emergence of cooperative behaviors in reinforcement learning agents by introducing a challenging competitive multi-agent soccer environment with continuous simulated physics. We demonstrate that decentralized, population-based training with co-play can lead to a progression in agents' behaviors: from random, to simple ball chasing, and finally showing evidence of cooperation. Our study highlights several of the challenges encountered in large scale multi-agent training in continuous control. In particular, we demonstrate that the automatic optimization of simple shaping rewards, not themselves conducive to co-operative behavior, can lead to long-horizon team behavior. We further apply an evaluation scheme, grounded by game theoretic principals, that can assess agent performance in the absence of pre-defined evaluation tasks or human baselines.
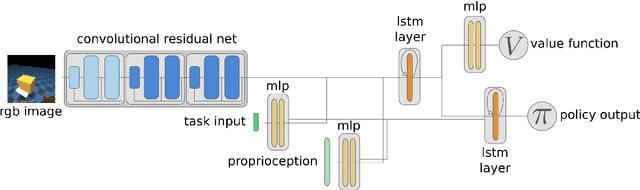
Hierarchical visuomotor control of humanoids
Jan 15, 2019



We aim to build complex humanoid agents that integrate perception, motor control, and memory. In this work, we partly factor this problem into low-level motor control from proprioception and high-level coordination of the low-level skills informed by vision. We develop an architecture capable of surprisingly flexible, task-directed motor control of a relatively high-DoF humanoid body by combining pre-training of low-level motor controllers with a high-level, task-focused controller that switches among low-level sub-policies. The resulting system is able to control a physically-simulated humanoid body to solve tasks that require coupling visual perception from an unstabilized egocentric RGB camera during locomotion in the environment. For a supplementary video link, see https://youtu.be/7GISvfbykLE .