 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
May 14, 2026Generating realistic human motion is a central yet unsolved challenge in video generation. While reinforcement learning (RL)-based post-training has driven recent gains in general video quality, extending it to human motion remains bottlenecked by a reward signal that cannot reliably score motion realism. Existing video rewards primarily rely on 2D perceptual signals, without explicitly modeling the 3D body state, contact, and dynamics underlying articulated human motion, and often assign high scores to videos with floating bodies or physically implausible movements. To address this, we propose PhyMotion, a structured, fine-grained motion reward that grounds recovered 3D human trajectories in a physics simulator and evaluates motion quality along multiple dimensions of physical feasibility. Concretely, we recover SMPL body meshes from generated videos, retarget them onto a humanoid in the MuJoCo physics simulator, and evaluate the resulting motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility. Each component provides a continuous and interpretable signal tied to a specific aspect of motion quality, allowing the reward to capture which aspects of motion are physically correct or violated. Experiments show that PhyMotion achieves stronger correlation with human judgments than existing reward formulations. These gains carry over to RL-based post-training, where optimizing PhyMotion leads to larger and more consistent improvements than optimizing existing rewards, improving motion realism across both autoregressive and bidirectional video generators under both automatic metrics and blind human evaluation (+68 Elo gain). Ablations show that the three axes provide complementary supervision signals, while the reward preserves overall video generation quality with only modest training overhead.
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Mar 16, 2026Simulation-to-real transfer remains a central challenge in robotics, as mismatches between simulated and real-world dynamics often lead to failures. While reinforcement learning offers a principled mechanism for adaptation, existing sim-to-real finetuning methods struggle with exploration and long-horizon credit assignment in the low-data regimes typical of real-world robotics. We introduce Simulation Distillation (SimDist), a sim-to-real framework that distills structural priors from a simulator into a latent world model and enables rapid real-world adaptation via online planning and supervised dynamics finetuning. By transferring reward and value models directly from simulation, SimDist provides dense planning signals from raw perception without requiring value learning during deployment. As a result, real-world adaptation reduces to short-horizon system identification, avoiding long-horizon credit assignment and enabling fast, stable improvement. Across precise manipulation and quadruped locomotion tasks, SimDist substantially outperforms prior methods in data efficiency, stability, and final performance. Project website and code: https://sim-dist.github.io/
World Model Failure Classification and Anomaly Detection for Autonomous Inspection
Feb 18, 2026Autonomous inspection robots for monitoring industrial sites can reduce costs and risks associated with human-led inspection. However, accurate readings can be challenging due to occlusions, limited viewpoints, or unexpected environmental conditions. We propose a hybrid framework that combines supervised failure classification with anomaly detection, enabling classification of inspection tasks as a success, known failure, or anomaly (i.e., out-of-distribution) case. Our approach uses a world model backbone with compressed video inputs. This policy-agnostic, distribution-free framework determines classifications based on two decision functions set by conformal prediction (CP) thresholds before a human observer does. We evaluate the framework on gauge inspection feeds collected from office and industrial sites and demonstrate real-time deployment on a Boston Dynamics Spot. Experiments show over 90% accuracy in distinguishing between successes, failures, and OOD cases, with classifications occurring earlier than a human observer. These results highlight the potential for robust, anticipatory failure detection in autonomous inspection tasks or as a feedback signal for model training to assess and improve the quality of training data. Project website: https://autoinspection-classification.github.io
Delay-Aware Diffusion Policy: Bridging the Observation-Execution Gap in Dynamic Tasks
Dec 08, 2025
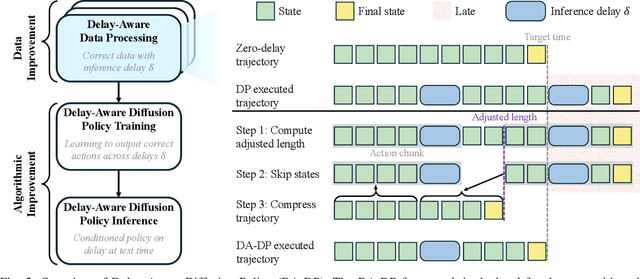


As a robot senses and selects actions, the world keeps changing. This inference delay creates a gap of tens to hundreds of milliseconds between the observed state and the state at execution. In this work, we take the natural generalization from zero delay to measured delay during training and inference. We introduce Delay-Aware Diffusion Policy (DA-DP), a framework for explicitly incorporating inference delays into policy learning. DA-DP corrects zero-delay trajectories to their delay-compensated counterparts, and augments the policy with delay conditioning. We empirically validate DA-DP on a variety of tasks, robots, and delays and find its success rate more robust to delay than delay-unaware methods. DA-DP is architecture agnostic and transfers beyond diffusion policies, offering a general pattern for delay-aware imitation learning. More broadly, DA-DP encourages evaluation protocols that report performance as a function of measured latency, not just task difficulty.
Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers
Nov 18, 2025We propose Confidence-Guided Token Merging (Co-Me), an acceleration mechanism for visual geometric transformers without retraining or finetuning the base model. Co-Me distilled a light-weight confidence predictor to rank tokens by uncertainty and selectively merge low-confidence ones, effectively reducing computation while maintaining spatial coverage. Compared to similarity-based merging or pruning, the confidence signal in Co-Me reliably indicates regions emphasized by the transformer, enabling substantial acceleration without degrading performance. Co-Me applies seamlessly to various multi-view and streaming visual geometric transformers, achieving speedups that scale with sequence length. When applied to VGGT and MapAnything, Co-Me achieves up to $11.3\times$ and $7.2\times$ speedup, making visual geometric transformers practical for real-time 3D perception and reconstruction.
VENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
StageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening
Sep 16, 2025Humanoid robots promise to operate in everyday human environments without requiring modifications to the surroundings. Among the many skills needed, opening doors is essential, as doors are the most common gateways in built spaces and often limit where a robot can go. Door opening, however, poses unique challenges as it is a long-horizon task under partial observability, such as reasoning about the door's unobservable latch state that dictates whether the robot should rotate the handle or push the door. This ambiguity makes standard behavior cloning prone to mode collapse, yielding blended or out-of-sequence actions. We introduce StageACT, a stage-conditioned imitation learning framework that augments low-level policies with task-stage inputs. This effective addition increases robustness to partial observability, leading to higher success rates and shorter completion times. On a humanoid operating in a real-world office environment, StageACT achieves a 55% success rate on previously unseen doors, more than doubling the best baseline. Moreover, our method supports intentional behavior guidance through stage prompting, enabling recovery behaviors. These results highlight stage conditioning as a lightweight yet powerful mechanism for long-horizon humanoid loco-manipulation.
Adaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
May 10, 2025Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
SayComply: Grounding Field Robotic Tasks in Operational Compliance through Retrieval-Based Language Models
Nov 18, 2024



This paper addresses the problem of task planning for robots that must comply with operational manuals in real-world settings. Task planning under these constraints is essential for enabling autonomous robot operation in domains that require adherence to domain-specific knowledge. Current methods for generating robot goals and plans rely on common sense knowledge encoded in large language models. However, these models lack grounding of robot plans to domain-specific knowledge and are not easily transferable between multiple sites or customers with different compliance needs. In this work, we present SayComply, which enables grounding robotic task planning with operational compliance using retrieval-based language models. We design a hierarchical database of operational, environment, and robot embodiment manuals and procedures to enable efficient retrieval of the relevant context under the limited context length of the LLMs. We then design a task planner using a tree-based retrieval augmented generation (RAG) technique to generate robot tasks that follow user instructions while simultaneously complying with the domain knowledge in the database. We demonstrate the benefits of our approach through simulations and hardware experiments in real-world scenarios that require precise context retrieval across various types of context, outperforming the standard RAG method. Our approach bridges the gap in deploying robots that consistently adhere to operational protocols, offering a scalable and edge-deployable solution for ensuring compliance across varied and complex real-world environments. Project website: saycomply.github.io.