 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStageACT: Stage-Conditioned Imitation for Robust Humanoid Door Opening
Sep 16, 2025Humanoid robots promise to operate in everyday human environments without requiring modifications to the surroundings. Among the many skills needed, opening doors is essential, as doors are the most common gateways in built spaces and often limit where a robot can go. Door opening, however, poses unique challenges as it is a long-horizon task under partial observability, such as reasoning about the door's unobservable latch state that dictates whether the robot should rotate the handle or push the door. This ambiguity makes standard behavior cloning prone to mode collapse, yielding blended or out-of-sequence actions. We introduce StageACT, a stage-conditioned imitation learning framework that augments low-level policies with task-stage inputs. This effective addition increases robustness to partial observability, leading to higher success rates and shorter completion times. On a humanoid operating in a real-world office environment, StageACT achieves a 55% success rate on previously unseen doors, more than doubling the best baseline. Moreover, our method supports intentional behavior guidance through stage prompting, enabling recovery behaviors. These results highlight stage conditioning as a lightweight yet powerful mechanism for long-horizon humanoid loco-manipulation.
Speaker Naming in Movies
Sep 24, 2018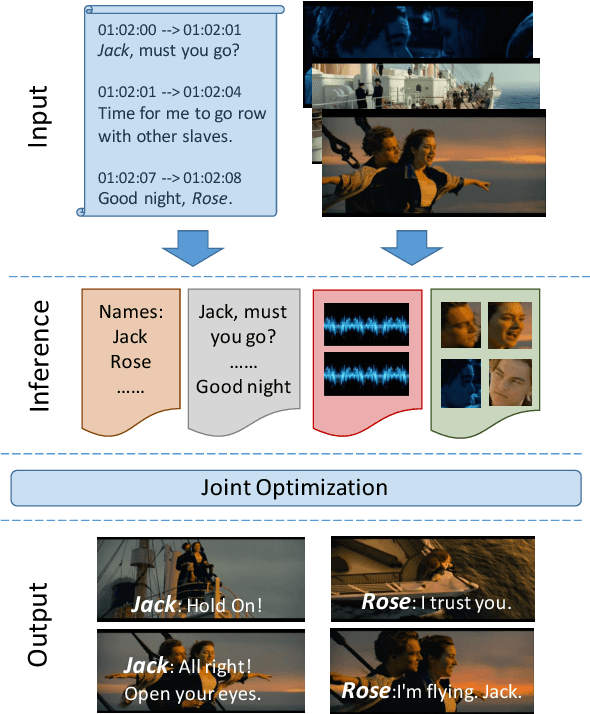
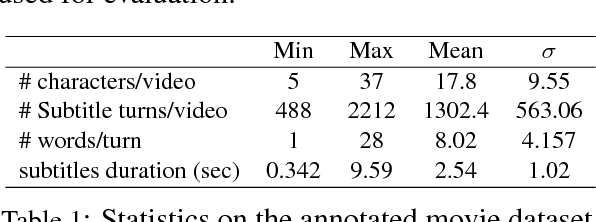
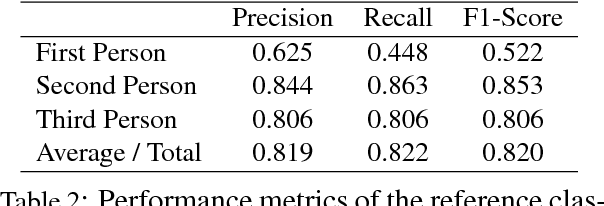
We propose a new model for speaker naming in movies that leverages visual, textual, and acoustic modalities in an unified optimization framework. To evaluate the performance of our model, we introduce a new dataset consisting of six episodes of the Big Bang Theory TV show and eighteen full movies covering different genres. Our experiments show that our multimodal model significantly outperforms several competitive baselines on the average weighted F-score metric. To demonstrate the effectiveness of our framework, we design an end-to-end memory network model that leverages our speaker naming model and achieves state-of-the-art results on the subtitles task of the MovieQA 2017 Challenge.