 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompCap: Improving Multimodal Large Language Models with Composite Captions
Dec 06, 2024



How well can Multimodal Large Language Models (MLLMs) understand composite images? Composite images (CIs) are synthetic visuals created by merging multiple visual elements, such as charts, posters, or screenshots, rather than being captured directly by a camera. While CIs are prevalent in real-world applications, recent MLLM developments have primarily focused on interpreting natural images (NIs). Our research reveals that current MLLMs face significant challenges in accurately understanding CIs, often struggling to extract information or perform complex reasoning based on these images. We find that existing training data for CIs are mostly formatted for question-answer tasks (e.g., in datasets like ChartQA and ScienceQA), while high-quality image-caption datasets, critical for robust vision-language alignment, are only available for NIs. To bridge this gap, we introduce Composite Captions (CompCap), a flexible framework that leverages Large Language Models (LLMs) and automation tools to synthesize CIs with accurate and detailed captions. Using CompCap, we curate CompCap-118K, a dataset containing 118K image-caption pairs across six CI types. We validate the effectiveness of CompCap-118K by supervised fine-tuning MLLMs of three sizes: xGen-MM-inst.-4B and LLaVA-NeXT-Vicuna-7B/13B. Empirical results show that CompCap-118K significantly enhances MLLMs' understanding of CIs, yielding average gains of 1.7%, 2.0%, and 2.9% across eleven benchmarks, respectively.
Normalized Contrastive Learning for Text-Video Retrieval
Nov 30, 2022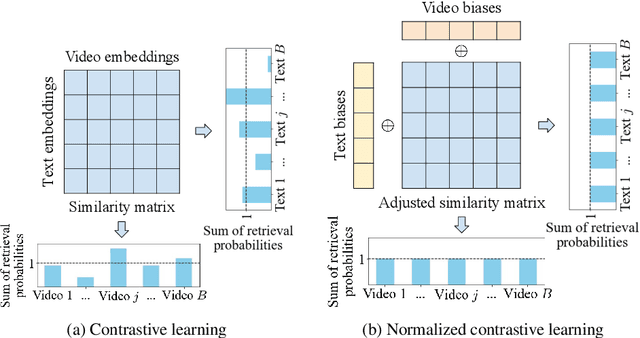
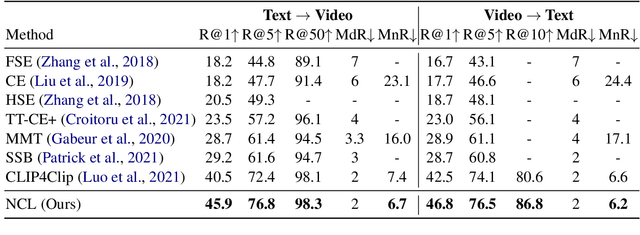
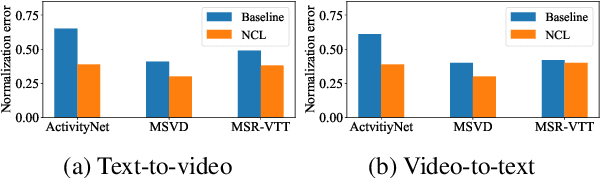
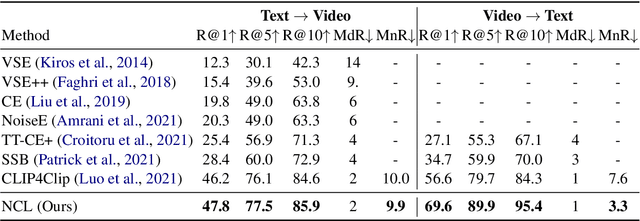
Cross-modal contrastive learning has led the recent advances in multimodal retrieval with its simplicity and effectiveness. In this work, however, we reveal that cross-modal contrastive learning suffers from incorrect normalization of the sum retrieval probabilities of each text or video instance. Specifically, we show that many test instances are either over- or under-represented during retrieval, significantly hurting the retrieval performance. To address this problem, we propose Normalized Contrastive Learning (NCL) which utilizes the Sinkhorn-Knopp algorithm to compute the instance-wise biases that properly normalize the sum retrieval probabilities of each instance so that every text and video instance is fairly represented during cross-modal retrieval. Empirical study shows that NCL brings consistent and significant gains in text-video retrieval on different model architectures, with new state-of-the-art multimodal retrieval metrics on the ActivityNet, MSVD, and MSR-VTT datasets without any architecture engineering.
Fighting FIRe with FIRE: Assessing the Validity of Text-to-Video Retrieval Benchmarks
Oct 10, 2022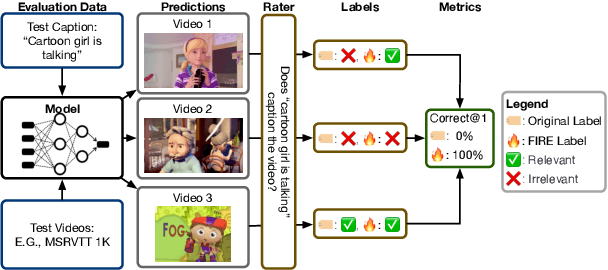
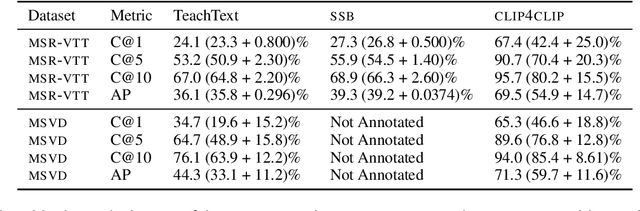
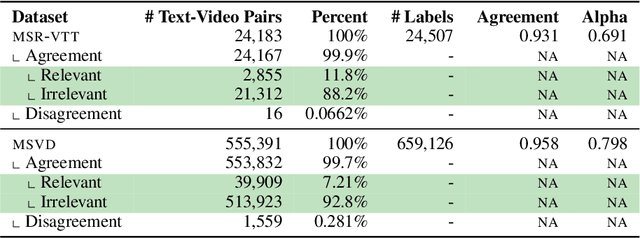
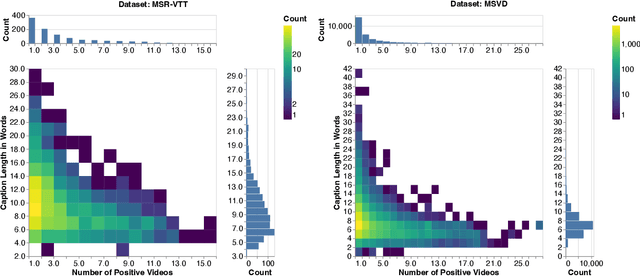
Searching vast troves of videos with textual descriptions is a core multimodal retrieval task. Owing to the lack of a purpose-built dataset for text-to-video retrieval, video captioning datasets have been re-purposed to evaluate models by (1) treating captions as positive matches to their respective videos and (2) all other videos as negatives. However, this methodology leads to a fundamental flaw during evaluation: since captions are marked as relevant only to their original video, many alternate videos also match the caption, which creates false-negative caption-video pairs. We show that when these false negatives are corrected, a recent state-of-the-art model gains 25% recall points -- a difference that threatens the validity of the benchmark itself. To diagnose and mitigate this issue, we annotate and release 683K additional caption-video pairs. Using these, we recompute effectiveness scores for three models on two standard benchmarks (MSR-VTT and MSVD). We find that (1) the recomputed metrics are up to 25% recall points higher for the best models, (2) these benchmarks are nearing saturation for Recall@10, (3) caption length (generality) is related to the number of positives, and (4) annotation costs can be mitigated by choosing evaluation sizes corresponding to desired effect size to detect. We recommend retiring these benchmarks in their current form and make recommendations for future text-to-video retrieval benchmarks.
A Comparative Analysis of Content-based Geolocation in Blogs and Tweets
Nov 19, 2018

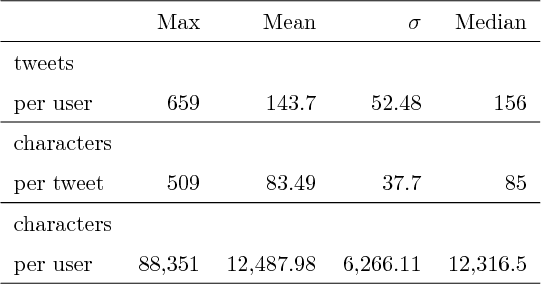

The geolocation of online information is an essential component in any geospatial application. While most of the previous work on geolocation has focused on Twitter, in this paper we quantify and compare the performance of text-based geolocation methods on social media data drawn from both Blogger and Twitter. We introduce a novel set of location specific features that are both highly informative and easily interpretable, and show that we can achieve error rate reductions of up to 12.5% with respect to the best previously proposed geolocation features. We also show that despite posting longer text, Blogger users are significantly harder to geolocate than Twitter users. Additionally, we investigate the effect of training and testing on different media (cross-media predictions), or combining multiple social media sources (multi-media predictions). Finally, we explore the geolocability of social media in relation to three user dimensions: state, gender, and industry.
Speaker Naming in Movies
Sep 24, 2018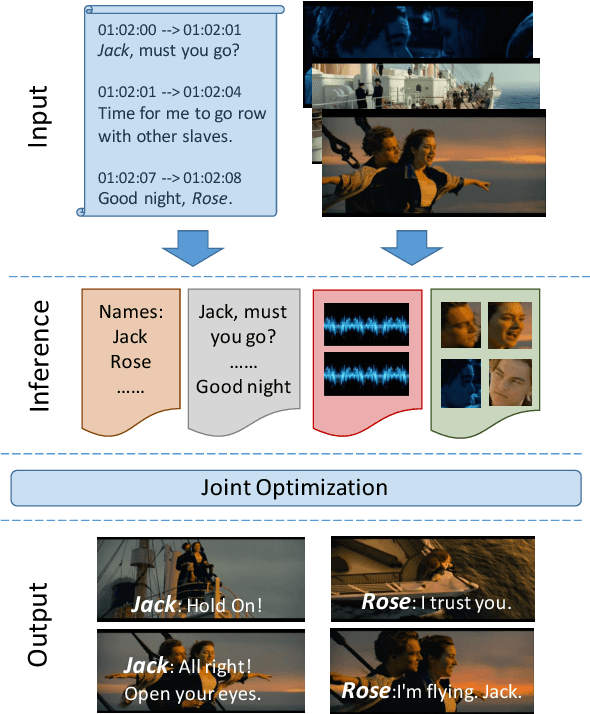
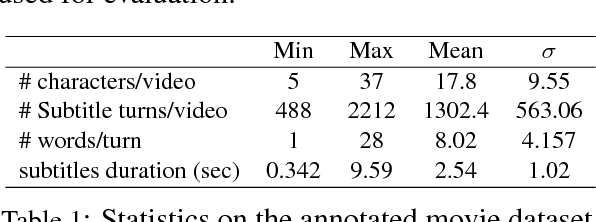
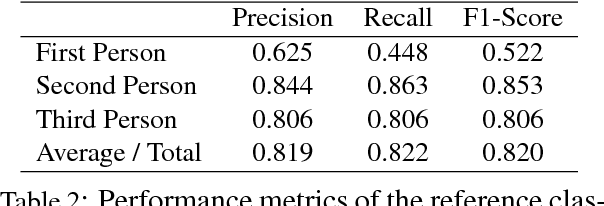
We propose a new model for speaker naming in movies that leverages visual, textual, and acoustic modalities in an unified optimization framework. To evaluate the performance of our model, we introduce a new dataset consisting of six episodes of the Big Bang Theory TV show and eighteen full movies covering different genres. Our experiments show that our multimodal model significantly outperforms several competitive baselines on the average weighted F-score metric. To demonstrate the effectiveness of our framework, we design an end-to-end memory network model that leverages our speaker naming model and achieves state-of-the-art results on the subtitles task of the MovieQA 2017 Challenge.