 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Contrastive Learning for Text-Video Retrieval
Nov 30, 2022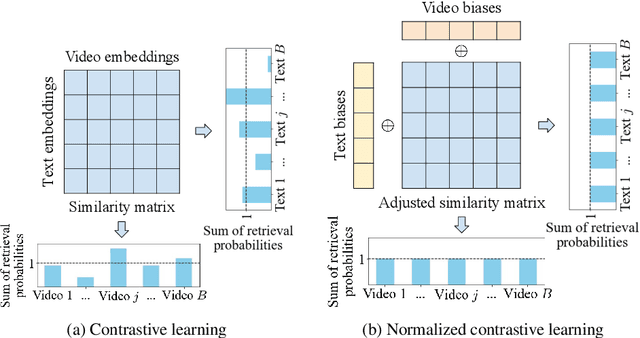
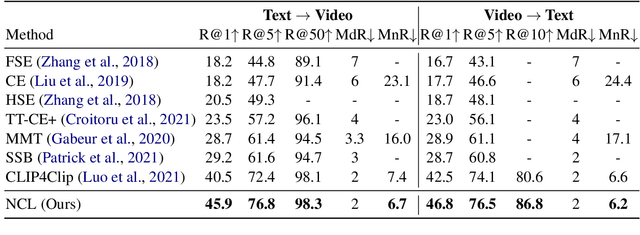
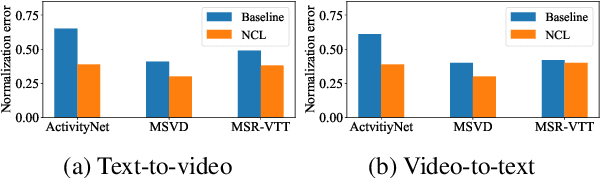
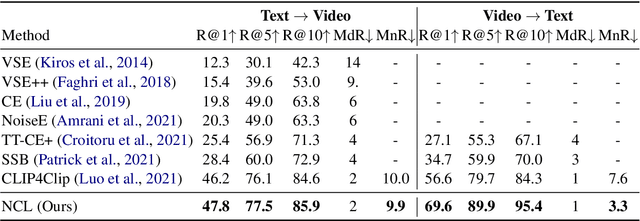
Cross-modal contrastive learning has led the recent advances in multimodal retrieval with its simplicity and effectiveness. In this work, however, we reveal that cross-modal contrastive learning suffers from incorrect normalization of the sum retrieval probabilities of each text or video instance. Specifically, we show that many test instances are either over- or under-represented during retrieval, significantly hurting the retrieval performance. To address this problem, we propose Normalized Contrastive Learning (NCL) which utilizes the Sinkhorn-Knopp algorithm to compute the instance-wise biases that properly normalize the sum retrieval probabilities of each instance so that every text and video instance is fairly represented during cross-modal retrieval. Empirical study shows that NCL brings consistent and significant gains in text-video retrieval on different model architectures, with new state-of-the-art multimodal retrieval metrics on the ActivityNet, MSVD, and MSR-VTT datasets without any architecture engineering.
SF-Net: Single-Frame Supervision for Temporal Action Localization
Mar 20, 2020In this paper, we study an intermediate form of supervision, i.e., single-frame supervision, for temporal action localization (TAL). To obtain the single-frame supervision, the annotators are asked to identify only a single frame within the temporal window of an action. This can significantly reduce the labor cost of obtaining full supervision which requires annotating the action boundary. Compared to the weak supervision that only annotates the video-level label, the single-frame supervision introduces extra temporal action signals while maintaining low annotation overhead. To make full use of such single-frame supervision, we propose a unified system called SF-Net. First, we propose to predict an actionness score for each video frame. Along with a typical category score, the actionness score can provide comprehensive information about the occurrence of a potential action and aid the temporal boundary refinement during inference. Second, we mine pseudo action and background frames based on the single-frame annotations. We identify pseudo action frames by adaptively expanding each annotated single frame to its nearby, contextual frames and we mine pseudo background frames from all the unannotated frames across multiple videos. Together with the ground-truth labeled frames, these pseudo-labeled frames are further used for training the classifier. In extensive experiments on THUMOS14, GTEA, and BEOID, SF-Net significantly improves upon state-of-the-art weakly-supervised methods in terms of both segment localization and single-frame localization. Notably, SF-Net achieves comparable results to its fully-supervised counterpart which requires much more resource intensive annotations.
Neural Cross-Lingual Coreference Resolution and its Application to Entity Linking
Jun 26, 2018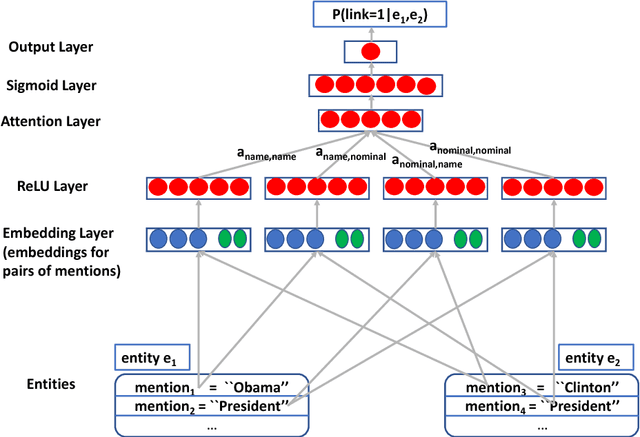
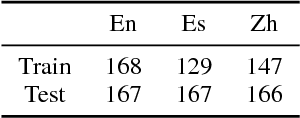
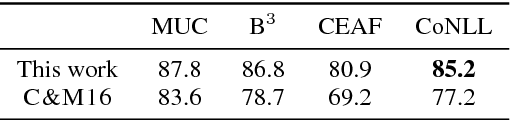

We propose an entity-centric neural cross-lingual coreference model that builds on multi-lingual embeddings and language-independent features. We perform both intrinsic and extrinsic evaluations of our model. In the intrinsic evaluation, we show that our model, when trained on English and tested on Chinese and Spanish, achieves competitive results to the models trained directly on Chinese and Spanish respectively. In the extrinsic evaluation, we show that our English model helps achieve superior entity linking accuracy on Chinese and Spanish test sets than the top 2015 TAC system without using any annotated data from Chinese or Spanish.
Neural Cross-Lingual Entity Linking
Dec 05, 2017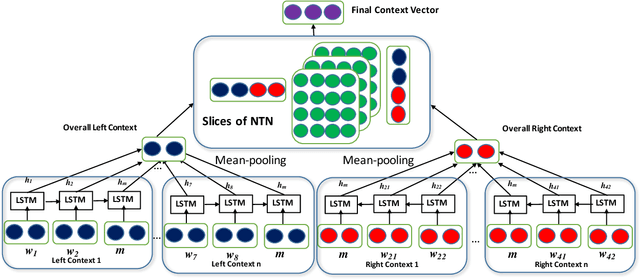

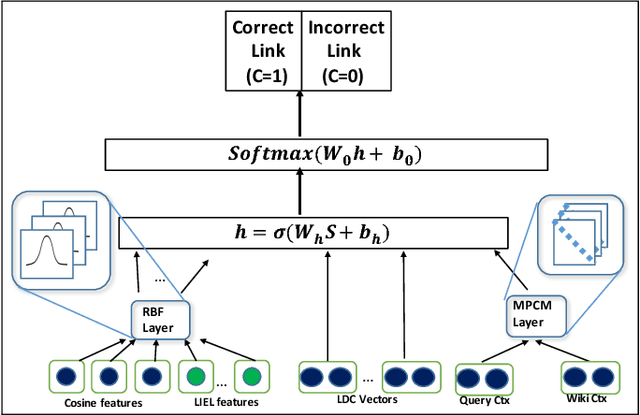

A major challenge in Entity Linking (EL) is making effective use of contextual information to disambiguate mentions to Wikipedia that might refer to different entities in different contexts. The problem exacerbates with cross-lingual EL which involves linking mentions written in non-English documents to entries in the English Wikipedia: to compare textual clues across languages we need to compute similarity between textual fragments across languages. In this paper, we propose a neural EL model that trains fine-grained similarities and dissimilarities between the query and candidate document from multiple perspectives, combined with convolution and tensor networks. Further, we show that this English-trained system can be applied, in zero-shot learning, to other languages by making surprisingly effective use of multi-lingual embeddings. The proposed system has strong empirical evidence yielding state-of-the-art results in English as well as cross-lingual: Spanish and Chinese TAC 2015 datasets.