 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Uncertainty Layers for Reliable Uncertainty Estimation
Jun 21, 2023



Assessing the predictive uncertainty of deep neural networks is crucial for safety-related applications of deep learning. Although Bayesian deep learning offers a principled framework for estimating model uncertainty, the approaches that are commonly used to approximate the posterior often fail to deliver reliable estimates of predictive uncertainty. In this paper we propose a novel criterion for predictive uncertainty, that a model's predictive variance should be grounded in the empirical density of the input. It should produce higher uncertainty for inputs that are improbable in the training data and lower uncertainty for those inputs that are more probable. To operationalize this criterion, we develop the density uncertainty layer, an architectural element for a stochastic neural network that guarantees that the density uncertain criterion is satisfied. We study neural networks with density uncertainty layers on the CIFAR-10 and CIFAR-100 uncertainty benchmarks. Compared to existing approaches, we find that density uncertainty layers provide reliable uncertainty estimates and robust out-of-distribution detection performance.
Variational Laplace Autoencoders
Nov 30, 2022



Variational autoencoders employ an amortized inference model to approximate the posterior of latent variables. However, such amortized variational inference faces two challenges: (1) the limited posterior expressiveness of fully-factorized Gaussian assumption and (2) the amortization error of the inference model. We present a novel approach that addresses both challenges. First, we focus on ReLU networks with Gaussian output and illustrate their connection to probabilistic PCA. Building on this observation, we derive an iterative algorithm that finds the mode of the posterior and apply full-covariance Gaussian posterior approximation centered on the mode. Subsequently, we present a general framework named Variational Laplace Autoencoders (VLAEs) for training deep generative models. Based on the Laplace approximation of the latent variable posterior, VLAEs enhance the expressiveness of the posterior while reducing the amortization error. Empirical results on MNIST, Omniglot, Fashion-MNIST, SVHN and CIFAR10 show that the proposed approach significantly outperforms other recent amortized or iterative methods on the ReLU networks.
Normalized Contrastive Learning for Text-Video Retrieval
Nov 30, 2022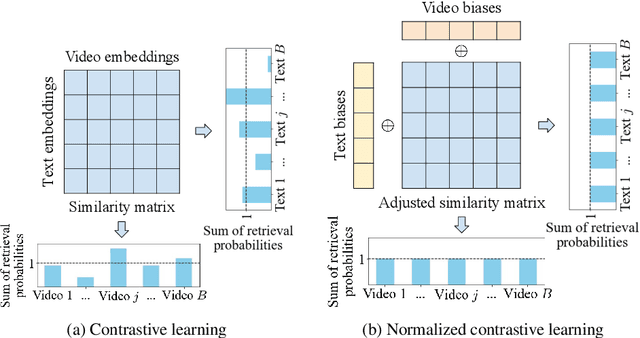
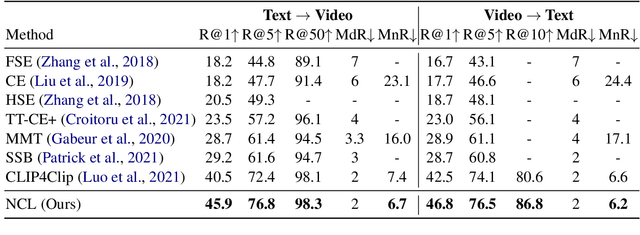
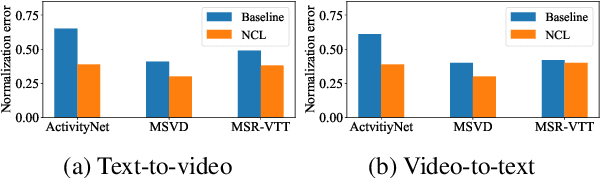
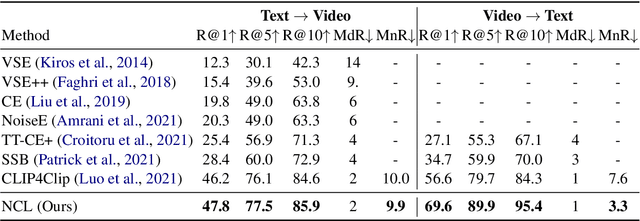
Cross-modal contrastive learning has led the recent advances in multimodal retrieval with its simplicity and effectiveness. In this work, however, we reveal that cross-modal contrastive learning suffers from incorrect normalization of the sum retrieval probabilities of each text or video instance. Specifically, we show that many test instances are either over- or under-represented during retrieval, significantly hurting the retrieval performance. To address this problem, we propose Normalized Contrastive Learning (NCL) which utilizes the Sinkhorn-Knopp algorithm to compute the instance-wise biases that properly normalize the sum retrieval probabilities of each instance so that every text and video instance is fairly represented during cross-modal retrieval. Empirical study shows that NCL brings consistent and significant gains in text-video retrieval on different model architectures, with new state-of-the-art multimodal retrieval metrics on the ActivityNet, MSVD, and MSR-VTT datasets without any architecture engineering.
Unsupervised Representation Learning via Neural Activation Coding
Dec 07, 2021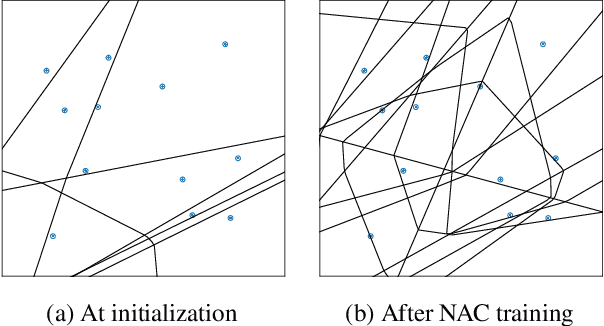
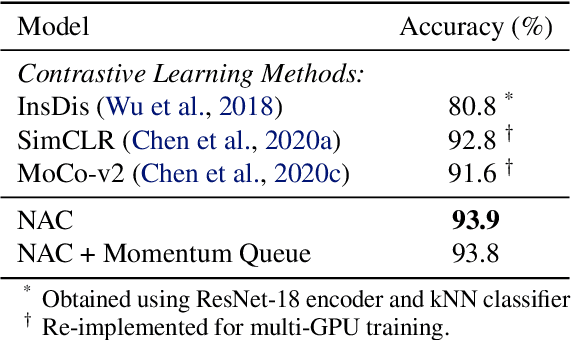
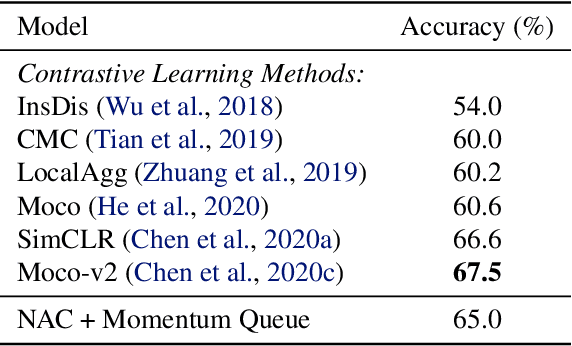
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
A Hierarchical Latent Structure for Variational Conversation Modeling
Apr 12, 2018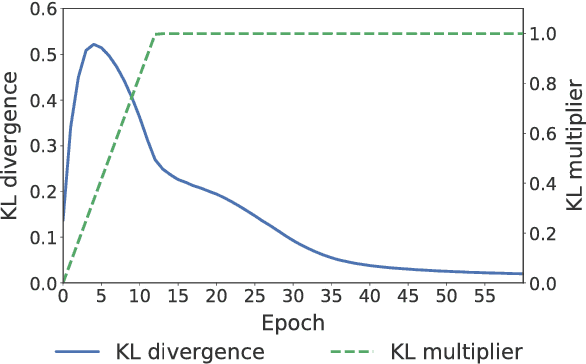
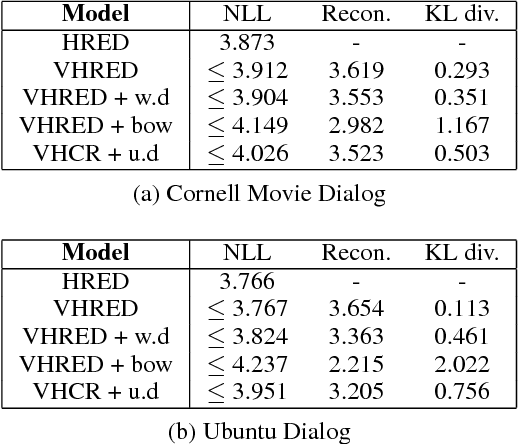
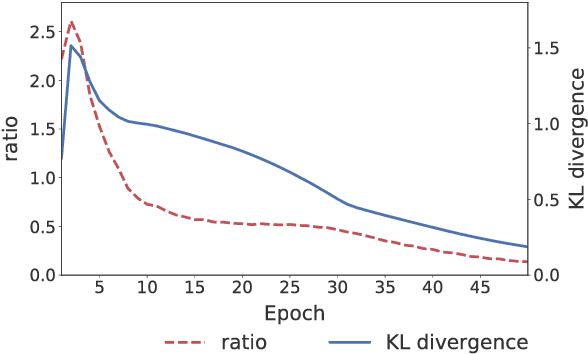

Variational autoencoders (VAE) combined with hierarchical RNNs have emerged as a powerful framework for conversation modeling. However, they suffer from the notorious degeneration problem, where the decoders learn to ignore latent variables and reduce to vanilla RNNs. We empirically show that this degeneracy occurs mostly due to two reasons. First, the expressive power of hierarchical RNN decoders is often high enough to model the data using only its decoding distributions without relying on the latent variables. Second, the conditional VAE structure whose generation process is conditioned on a context, makes the range of training targets very sparse; that is, the RNN decoders can easily overfit to the training data ignoring the latent variables. To solve the degeneration problem, we propose a novel model named Variational Hierarchical Conversation RNNs (VHCR), involving two key ideas of (1) using a hierarchical structure of latent variables, and (2) exploiting an utterance drop regularization. With evaluations on two datasets of Cornell Movie Dialog and Ubuntu Dialog Corpus, we show that our VHCR successfully utilizes latent variables and outperforms state-of-the-art models for conversation generation. Moreover, it can perform several new utterance control tasks, thanks to its hierarchical latent structure.