 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
Dec 15, 2025As humans, we are natural any-horizon reasoners, i.e., we can decide whether to iteratively skim long videos or watch short ones in full when necessary for a given task. With this in mind, one would expect video reasoning models to reason flexibly across different durations. However, SOTA models are still trained to predict answers in a single turn while processing a large number of frames, akin to watching an entire long video, requiring significant resources. This raises the question: Is it possible to develop performant any-horizon video reasoning systems? Inspired by human behavior, we first propose SAGE, an agent system that performs multi-turn reasoning on long videos while handling simpler problems in a single turn. Secondly, we introduce an easy synthetic data generation pipeline using Gemini-2.5-Flash to train the orchestrator, SAGE-MM, which lies at the core of SAGE. We further propose an effective RL post-training recipe essential for instilling any-horizon reasoning ability in SAGE-MM. Thirdly, we curate SAGE-Bench with an average duration of greater than 700 seconds for evaluating video reasoning ability in real-world entertainment use cases. Lastly, we empirically validate the effectiveness of our system, data, and RL recipe, observing notable improvements of up to 6.1% on open-ended video reasoning tasks, as well as an impressive 8.2% improvement on videos longer than 10 minutes.
ReSpec: Relevance and Specificity Grounded Online Filtering for Learning on Video-Text Data Streams
Apr 21, 2025The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these issues while also allowing swift adaptations in scenarios demanding real-time responsiveness. One strategy to enhance the efficiency and effectiveness of learning involves identifying and prioritizing data that enhances performance on target downstream tasks. We propose Relevance and Specificity-based online filtering framework (ReSpec) that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zeroshot video retrieval tasks, using as little as 5% of the data while incurring minimal compute. The source code is available at https://github.com/cdjkim/ReSpec.
Sample Selection via Contrastive Fragmentation for Noisy Label Regression
Feb 25, 2025As with many other problems, real-world regression is plagued by the presence of noisy labels, an inevitable issue that demands our attention. Fortunately, much real-world data often exhibits an intrinsic property of continuously ordered correlations between labels and features, where data points with similar labels are also represented with closely related features. In response, we propose a novel approach named ConFrag, where we collectively model the regression data by transforming them into disjoint yet contrasting fragmentation pairs. This enables the training of more distinctive representations, enhancing the ability to select clean samples. Our ConFrag framework leverages a mixture of neighboring fragments to discern noisy labels through neighborhood agreement among expert feature extractors. We extensively perform experiments on six newly curated benchmark datasets of diverse domains, including age prediction, price prediction, and music production year estimation. We also introduce a metric called Error Residual Ratio (ERR) to better account for varying degrees of label noise. Our approach consistently outperforms fourteen state-of-the-art baselines, being robust against symmetric and random Gaussian label noise.
Variational Laplace Autoencoders
Nov 30, 2022



Variational autoencoders employ an amortized inference model to approximate the posterior of latent variables. However, such amortized variational inference faces two challenges: (1) the limited posterior expressiveness of fully-factorized Gaussian assumption and (2) the amortization error of the inference model. We present a novel approach that addresses both challenges. First, we focus on ReLU networks with Gaussian output and illustrate their connection to probabilistic PCA. Building on this observation, we derive an iterative algorithm that finds the mode of the posterior and apply full-covariance Gaussian posterior approximation centered on the mode. Subsequently, we present a general framework named Variational Laplace Autoencoders (VLAEs) for training deep generative models. Based on the Laplace approximation of the latent variable posterior, VLAEs enhance the expressiveness of the posterior while reducing the amortization error. Empirical results on MNIST, Omniglot, Fashion-MNIST, SVHN and CIFAR10 show that the proposed approach significantly outperforms other recent amortized or iterative methods on the ReLU networks.
Continual Learning on Noisy Data Streams via Self-Purified Replay
Oct 14, 2021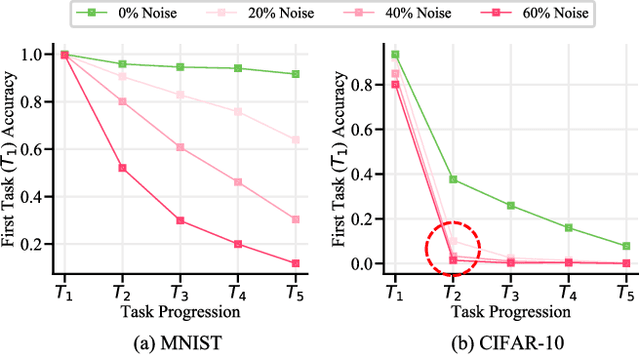
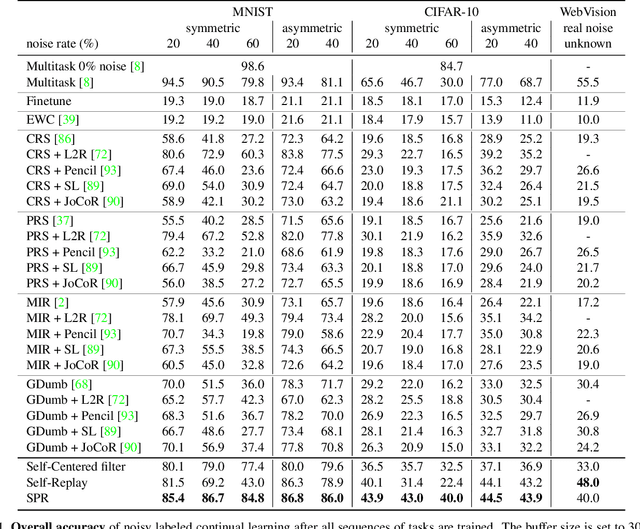
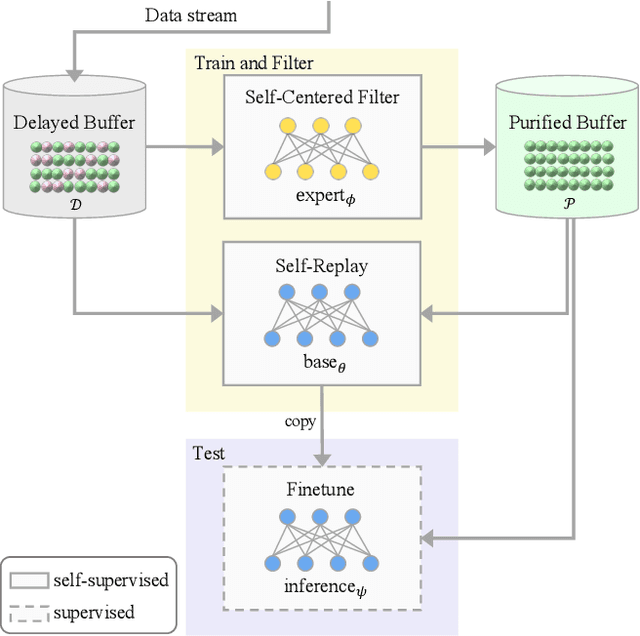
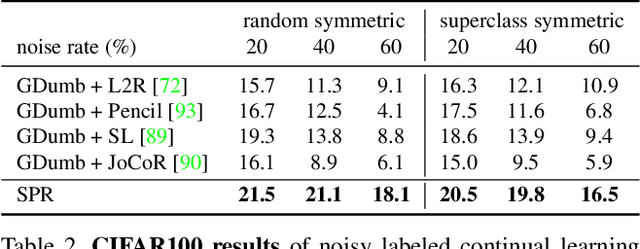
Continually learning in the real world must overcome many challenges, among which noisy labels are a common and inevitable issue. In this work, we present a repla-ybased continual learning framework that simultaneously addresses both catastrophic forgetting and noisy labels for the first time. Our solution is based on two observations; (i) forgetting can be mitigated even with noisy labels via self-supervised learning, and (ii) the purity of the replay buffer is crucial. Building on this regard, we propose two key components of our method: (i) a self-supervised replay technique named Self-Replay which can circumvent erroneous training signals arising from noisy labeled data, and (ii) the Self-Centered filter that maintains a purified replay buffer via centrality-based stochastic graph ensembles. The empirical results on MNIST, CIFAR-10, CIFAR-100, and WebVision with real-world noise demonstrate that our framework can maintain a highly pure replay buffer amidst noisy streamed data while greatly outperforming the combinations of the state-of-the-art continual learning and noisy label learning methods. The source code is available at http://vision.snu.ac.kr/projects/SPR
Imbalanced Continual Learning with Partitioning Reservoir Sampling
Sep 08, 2020



Continual learning from a sequential stream of data is a crucial challenge for machine learning research. Most studies have been conducted on this topic under the single-label classification setting along with an assumption of balanced label distribution. This work expands this research horizon towards multi-label classification. In doing so, we identify unanticipated adversity innately existent in many multi-label datasets, the long-tailed distribution. We jointly address the two independently solved problems, Catastropic Forgetting and the long-tailed label distribution by first empirically showing a new challenge of destructive forgetting of the minority concepts on the tail. Then, we curate two benchmark datasets, COCOseq and NUS-WIDEseq, that allow the study of both intra- and inter-task imbalances. Lastly, we propose a new sampling strategy for replay-based approach named Partitioning Reservoir Sampling (PRS), which allows the model to maintain a balanced knowledge of both head and tail classes. We publicly release the dataset and the code in our project page.
Generative Adversarial Parallelization
Dec 13, 2016


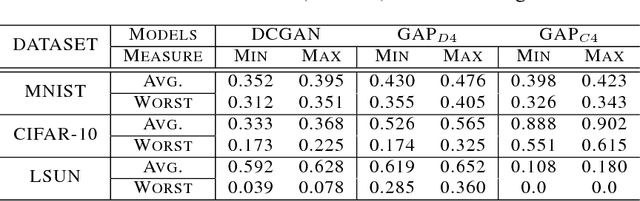
Generative Adversarial Networks have become one of the most studied frameworks for unsupervised learning due to their intuitive formulation. They have also been shown to be capable of generating convincing examples in limited domains, such as low-resolution images. However, they still prove difficult to train in practice and tend to ignore modes of the data generating distribution. Quantitatively capturing effects such as mode coverage and more generally the quality of the generative model still remain elusive. We propose Generative Adversarial Parallelization, a framework in which many GANs or their variants are trained simultaneously, exchanging their discriminators. This eliminates the tight coupling between a generator and discriminator, leading to improved convergence and improved coverage of modes. We also propose an improved variant of the recently proposed Generative Adversarial Metric and show how it can score individual GANs or their collections under the GAP model.
Generating images with recurrent adversarial networks
Dec 13, 2016
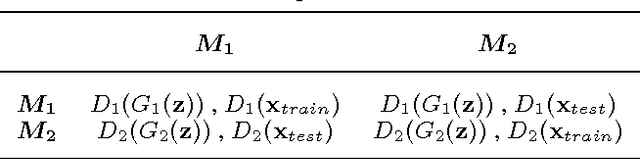


Gatys et al. (2015) showed that optimizing pixels to match features in a convolutional network with respect reference image features is a way to render images of high visual quality. We show that unrolling this gradient-based optimization yields a recurrent computation that creates images by incrementally adding onto a visual "canvas". We propose a recurrent generative model inspired by this view, and show that it can be trained using adversarial training to generate very good image samples. We also propose a way to quantitatively compare adversarial networks by having the generators and discriminators of these networks compete against each other.