 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSpec: Relevance and Specificity Grounded Online Filtering for Learning on Video-Text Data Streams
Apr 21, 2025The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these issues while also allowing swift adaptations in scenarios demanding real-time responsiveness. One strategy to enhance the efficiency and effectiveness of learning involves identifying and prioritizing data that enhances performance on target downstream tasks. We propose Relevance and Specificity-based online filtering framework (ReSpec) that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zeroshot video retrieval tasks, using as little as 5% of the data while incurring minimal compute. The source code is available at https://github.com/cdjkim/ReSpec.
Autonomous Robotic Radio Source Localization via a Novel Gaussian Mixture Filtering Approach
Mar 13, 2025This study proposes a new Gaussian Mixture Filter (GMF) to improve the estimation performance for the autonomous robotic radio signal source search and localization problem in unknown environments. The proposed filter is first tested with a benchmark numerical problem to validate the performance with other state-of-practice approaches such as Particle Gaussian Mixture (PGM) filters and Particle Filter (PF). Then the proposed approach is tested and compared against PF and PGM filters in real-world robotic field experiments to validate its impact for real-world robotic applications. The considered real-world scenarios have partial observability with the range-only measurement and uncertainty with the measurement model. The results show that the proposed filter can handle this partial observability effectively whilst showing improved performance compared to PF, reducing the computation requirements while demonstrating improved robustness over compared techniques.
Sample Selection via Contrastive Fragmentation for Noisy Label Regression
Feb 25, 2025As with many other problems, real-world regression is plagued by the presence of noisy labels, an inevitable issue that demands our attention. Fortunately, much real-world data often exhibits an intrinsic property of continuously ordered correlations between labels and features, where data points with similar labels are also represented with closely related features. In response, we propose a novel approach named ConFrag, where we collectively model the regression data by transforming them into disjoint yet contrasting fragmentation pairs. This enables the training of more distinctive representations, enhancing the ability to select clean samples. Our ConFrag framework leverages a mixture of neighboring fragments to discern noisy labels through neighborhood agreement among expert feature extractors. We extensively perform experiments on six newly curated benchmark datasets of diverse domains, including age prediction, price prediction, and music production year estimation. We also introduce a metric called Error Residual Ratio (ERR) to better account for varying degrees of label noise. Our approach consistently outperforms fourteen state-of-the-art baselines, being robust against symmetric and random Gaussian label noise.
Enabling Novel Mission Operations and Interactions with ROSA: The Robot Operating System Agent
Oct 09, 2024The advancement of robotic systems has revolutionized numerous industries, yet their operation often demands specialized technical knowledge, limiting accessibility for non-expert users. This paper introduces ROSA (Robot Operating System Agent), an AI-powered agent that bridges the gap between the Robot Operating System (ROS) and natural language interfaces. By leveraging state-of-the-art language models and integrating open-source frameworks, ROSA enables operators to interact with robots using natural language, translating commands into actions and interfacing with ROS through well-defined tools. ROSA's design is modular and extensible, offering seamless integration with both ROS1 and ROS2, along with safety mechanisms like parameter validation and constraint enforcement to ensure secure, reliable operations. While ROSA is originally designed for ROS, it can be extended to work with other robotics middle-wares to maximize compatibility across missions. ROSA enhances human-robot interaction by democratizing access to complex robotic systems, empowering users of all expertise levels with multi-modal capabilities such as speech integration and visual perception. Ethical considerations are thoroughly addressed, guided by foundational principles like Asimov's Three Laws of Robotics, ensuring that AI integration promotes safety, transparency, privacy, and accountability. By making robotic technology more user-friendly and accessible, ROSA not only improves operational efficiency but also sets a new standard for responsible AI use in robotics and potentially future mission operations. This paper introduces ROSA's architecture and showcases initial mock-up operations in JPL's Mars Yard, a laboratory, and a simulation using three different robots. The core ROSA library is available as open-source.
Fast and Scalable Signal Inference for Active Robotic Source Seeking
Jan 06, 2023



In active source seeking, a robot takes repeated measurements in order to locate a signal source in a cluttered and unknown environment. A key component of an active source seeking robot planner is a model that can produce estimates of the signal at unknown locations with uncertainty quantification. This model allows the robot to plan for future measurements in the environment. Traditionally, this model has been in the form of a Gaussian process, which has difficulty scaling and cannot represent obstacles. %In this work, We propose a global and local factor graph model for active source seeking, which allows the model to scale to a large number of measurements and represent unknown obstacles in the environment. We combine this model with extensions to a highly scalable planner to form a system for large-scale active source seeking. We demonstrate that our approach outperforms baseline methods in both simulated and real robot experiments.
Continual Learning on Noisy Data Streams via Self-Purified Replay
Oct 14, 2021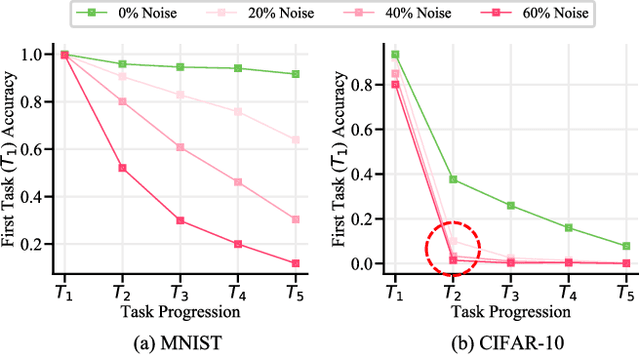
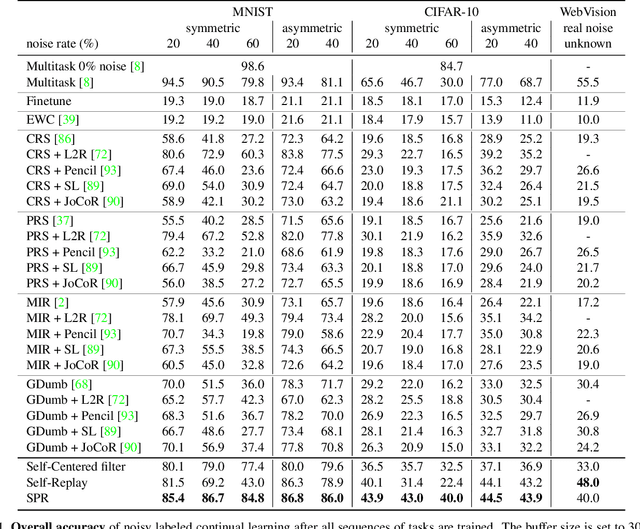
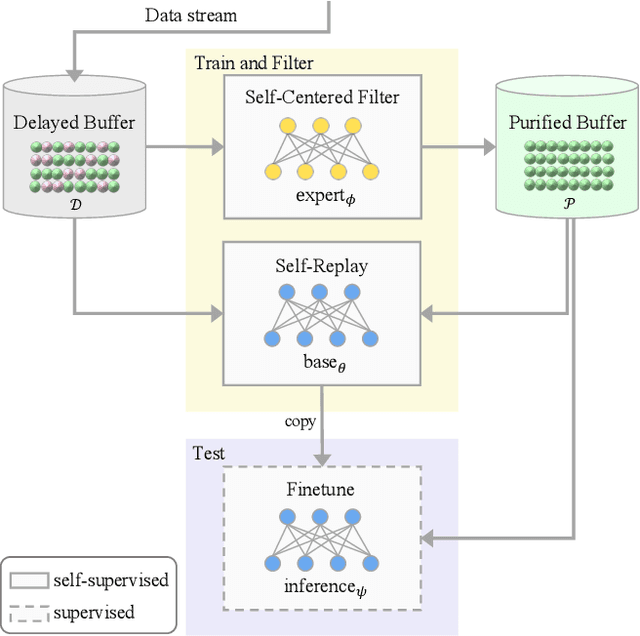
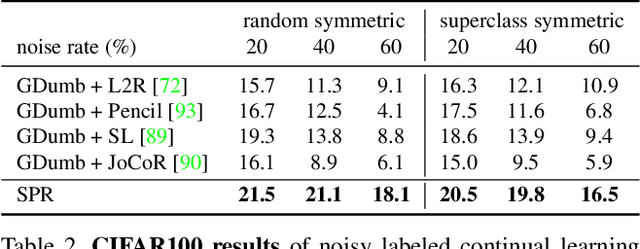
Continually learning in the real world must overcome many challenges, among which noisy labels are a common and inevitable issue. In this work, we present a repla-ybased continual learning framework that simultaneously addresses both catastrophic forgetting and noisy labels for the first time. Our solution is based on two observations; (i) forgetting can be mitigated even with noisy labels via self-supervised learning, and (ii) the purity of the replay buffer is crucial. Building on this regard, we propose two key components of our method: (i) a self-supervised replay technique named Self-Replay which can circumvent erroneous training signals arising from noisy labeled data, and (ii) the Self-Centered filter that maintains a purified replay buffer via centrality-based stochastic graph ensembles. The empirical results on MNIST, CIFAR-10, CIFAR-100, and WebVision with real-world noise demonstrate that our framework can maintain a highly pure replay buffer amidst noisy streamed data while greatly outperforming the combinations of the state-of-the-art continual learning and noisy label learning methods. The source code is available at http://vision.snu.ac.kr/projects/SPR
Learning to Schedule Communication in Multi-agent Reinforcement Learning
Feb 05, 2019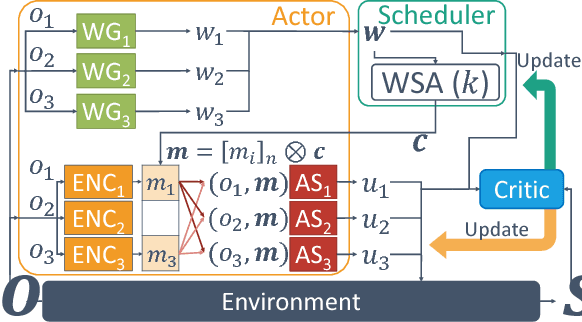

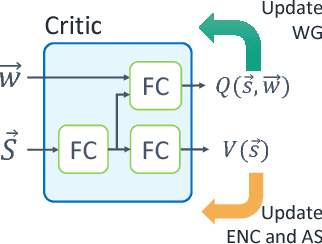

Many real-world reinforcement learning tasks require multiple agents to make sequential decisions under the agents' interaction, where well-coordinated actions among the agents are crucial to achieve the target goal better at these tasks. One way to accelerate the coordination effect is to enable multiple agents to communicate with each other in a distributed manner and behave as a group. In this paper, we study a practical scenario when (i) the communication bandwidth is limited and (ii) the agents share the communication medium so that only a restricted number of agents are able to simultaneously use the medium, as in the state-of-the-art wireless networking standards. This calls for a certain form of communication scheduling. In that regard, we propose a multi-agent deep reinforcement learning framework, called SchedNet, in which agents learn how to schedule themselves, how to encode the messages, and how to select actions based on received messages. SchedNet is capable of deciding which agents should be entitled to broadcasting their (encoded) messages, by learning the importance of each agent's partially observed information. We evaluate SchedNet against multiple baselines under two different applications, namely, cooperative communication and navigation, and predator-prey. Our experiments show a non-negligible performance gap between SchedNet and other mechanisms such as the ones without communication and with vanilla scheduling methods, e.g., round robin, ranging from 32% to 43%.