 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Mitigation and Intent Inference: A Dual-Mode Human-Machine Joint Planning System
Mar 08, 2026Effective human-robot collaboration in open-world environments requires joint planning under uncertain conditions. However, existing approaches often treat humans as passive supervisors, preventing autonomous agents from becoming human-like teammates that can actively model teammate behaviors, reason about knowledge gaps, query, and elicit responses through communication to resolve uncertainties. To address these limitations, we propose a unified human-robot joint planning system designed to tackle dual sources of uncertainty: task-relevant knowledge gaps and latent human intent. Our system operates in two complementary modes. First, an uncertainty-mitigation joint planning module enables two-way conversations to resolve semantic ambiguity and object uncertainty. It utilizes an LLM-assisted active elicitation mechanism and a hypothesis-augmented A^* search, subsequently computing an optimal querying policy via dynamic programming to minimize interaction and verification costs. Second, a real-time intent-aware collaboration module maintains a probabilistic belief over the human's latent task intent via spatial and directional cues, enabling dynamic, coordination-aware task selection for agents without explicit communication. We validate the proposed system in both Gazebo simulations and real-world UAV deployments integrated with a Vision-Language Model (VLM)-based 3D semantic perception pipeline. Experimental results demonstrate that the system significantly cuts the interaction cost by 51.9% in uncertainty-mitigation planning and reduces the task execution time by 25.4% in intent-aware cooperation compared to the baselines.
Equivariant Reinforcement Learning Frameworks for Quadrotor Low-Level Control
Feb 27, 2025



Improving sampling efficiency and generalization capability is critical for the successful data-driven control of quadrotor unmanned aerial vehicles (UAVs) that are inherently unstable. While various reinforcement learning (RL) approaches have been applied to autonomous quadrotor flight, they often require extensive training data, posing multiple challenges and safety risks in practice. To address these issues, we propose data-efficient, equivariant monolithic and modular RL frameworks for quadrotor low-level control. Specifically, by identifying the rotational and reflectional symmetries in quadrotor dynamics and encoding these symmetries into equivariant network models, we remove redundancies of learning in the state-action space. This approach enables the optimal control action learned in one configuration to automatically generalize into other configurations via symmetry, thereby enhancing data efficiency. Experimental results demonstrate that our equivariant approaches significantly outperform their non-equivariant counterparts in terms of learning efficiency and flight performance.
Vision-in-the-loop Simulation for Deep Monocular Pose Estimation of UAV in Ocean Environment
Feb 08, 2025This paper proposes a vision-in-the-loop simulation environment for deep monocular pose estimation of a UAV operating in an ocean environment. Recently, a deep neural network with a transformer architecture has been successfully trained to estimate the pose of a UAV relative to the flight deck of a research vessel, overcoming several limitations of GPS-based approaches. However, validating the deep pose estimation scheme in an actual ocean environment poses significant challenges due to the limited availability of research vessels and the associated operational costs. To address these issues, we present a photo-realistic 3D virtual environment leveraging recent advancements in Gaussian splatting, a novel technique that represents 3D scenes by modeling image pixels as Gaussian distributions in 3D space, creating a lightweight and high-quality visual model from multiple viewpoints. This approach enables the creation of a virtual environment integrating multiple real-world images collected in situ. The resulting simulation enables the indoor testing of flight maneuvers while verifying all aspects of flight software, hardware, and the deep monocular pose estimation scheme. This approach provides a cost-effective solution for testing and validating the autonomous flight of shipboard UAVs, specifically focusing on vision-based control and estimation algorithms.
Deep Transformer Network for Monocular Pose Estimation of Ship-Based UAV
Jun 13, 2024This paper introduces a deep transformer network for estimating the relative 6D pose of a Unmanned Aerial Vehicle (UAV) with respect to a ship using monocular images. A synthetic dataset of ship images is created and annotated with 2D keypoints of multiple ship parts. A Transformer Neural Network model is trained to detect these keypoints and estimate the 6D pose of each part. The estimates are integrated using Bayesian fusion. The model is tested on synthetic data and in-situ flight experiments, demonstrating robustness and accuracy in various lighting conditions. The position estimation error is approximately 0.8\% and 1.0\% of the distance to the ship for the synthetic data and the flight experiments, respectively. The method has potential applications for ship-based autonomous UAV landing and navigation.
Collaborative AI Teaming in Unknown Environments via Active Goal Deduction
Mar 22, 2024With the advancements of artificial intelligence (AI), we're seeing more scenarios that require AI to work closely with other agents, whose goals and strategies might not be known beforehand. However, existing approaches for training collaborative agents often require defined and known reward signals and cannot address the problem of teaming with unknown agents that often have latent objectives/rewards. In response to this challenge, we propose teaming with unknown agents framework, which leverages kernel density Bayesian inverse learning method for active goal deduction and utilizes pre-trained, goal-conditioned policies to enable zero-shot policy adaptation. We prove that unbiased reward estimates in our framework are sufficient for optimal teaming with unknown agents. We further evaluate the framework of redesigned multi-agent particle and StarCraft II micromanagement environments with diverse unknown agents of different behaviors/rewards. Empirical results demonstrate that our framework significantly advances the teaming performance of AI and unknown agents in a wide range of collaborative scenarios.
Multi-Agent Reinforcement Learning for the Low-Level Control of a Quadrotor UAV
Nov 10, 2023



This paper presents multi-agent reinforcement learning frameworks for the low-level control of a quadrotor UAV. While single-agent reinforcement learning has been successfully applied to quadrotors, training a single monolithic network is often data-intensive and time-consuming. To address this, we decompose the quadrotor dynamics into the translational dynamics and the yawing dynamics, and assign a reinforcement learning agent to each part for efficient training and performance improvements. The proposed multi-agent framework for quadrotor low-level control that leverages the underlying structures of the quadrotor dynamics is a unique contribution. Further, we introduce regularization terms to mitigate steady-state errors and to avoid aggressive control inputs. Through benchmark studies with sim-to-sim transfer, it is illustrated that the proposed multi-agent reinforcement learning substantially improves the convergence rate of the training and the stability of the controlled dynamics.
Constrained Imitation Learning for a Flapping Wing Unmanned Aerial Vehicle
Jun 08, 2022



This paper presents a data-driven optimal control policy for a micro flapping wing unmanned aerial vehicle. First, a set of optimal trajectories are computed off-line based on a geometric formulation of dynamics that captures the nonlinear coupling between the large angle flapping motion and the quasi-steady aerodynamics. Then, it is transformed into a feedback control system according to the framework of imitation learning. In particular, an additional constraint is incorporated through the learning process to enhance the stability properties of the resulting controlled dynamics. Compared with conventional methods, the proposed constrained imitation learning eliminates the need to generate additional optimal trajectories on-line, without sacrificing stability. As such, the computational efficiency is substantially improved. Furthermore, this establishes the first nonlinear control system that stabilizes the coupled longitudinal and lateral dynamics of flapping wing aerial vehicle without relying on averaging or linearization. These are illustrated by numerical examples for a simulated model inspired by Monarch butterflies.
Equivariant Reinforcement Learning for Quadrotor UAV
Jun 02, 2022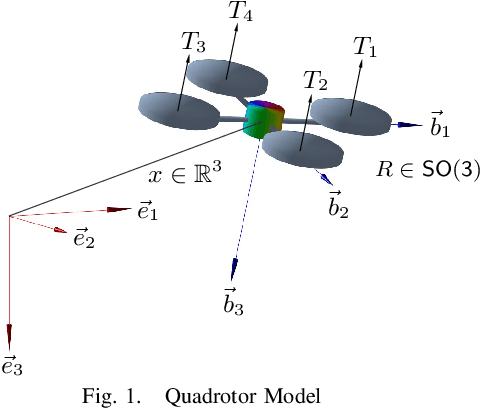
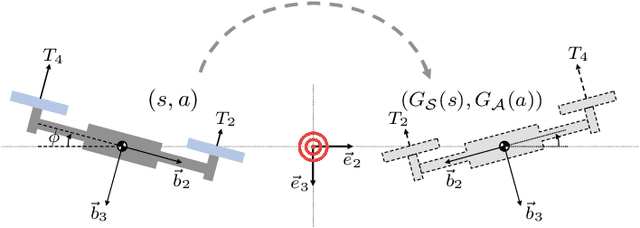
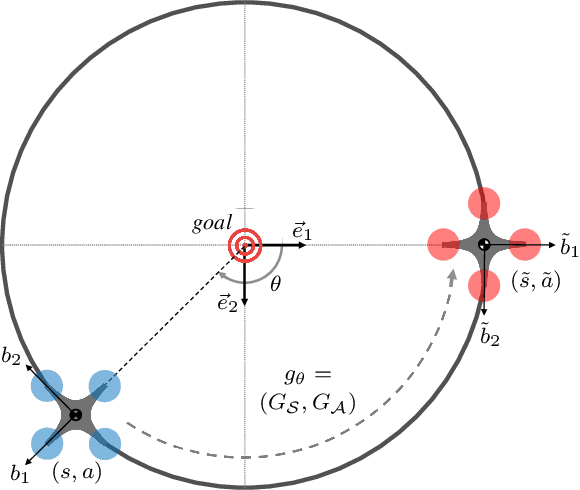
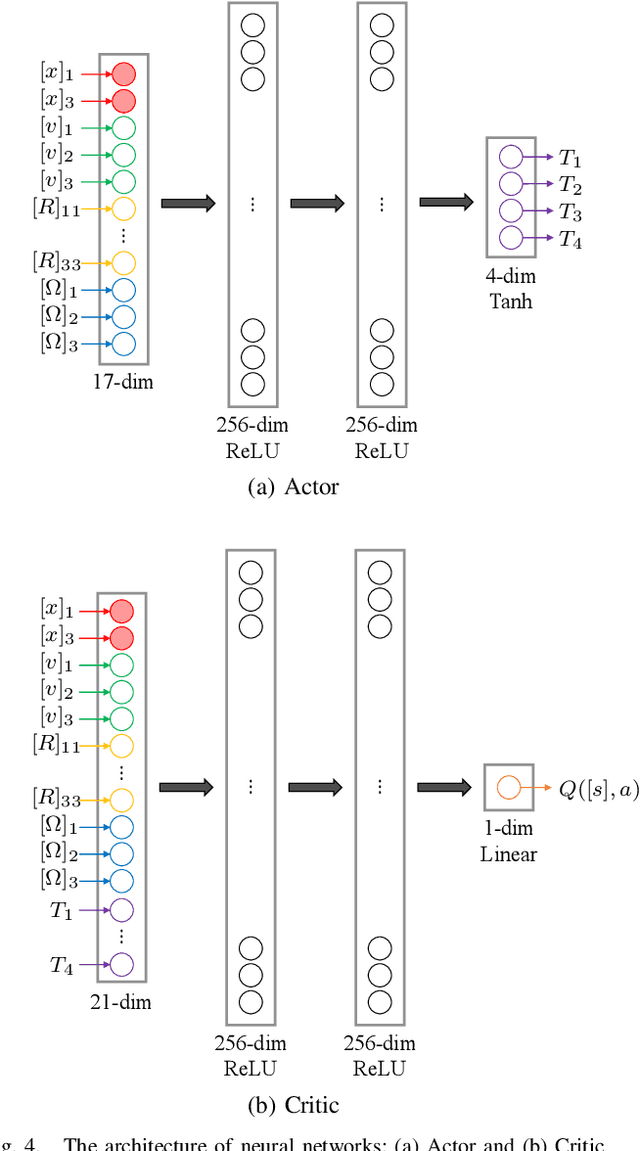
This paper presents an equivariant reinforcement learning framework for quadrotor unmanned aerial vehicles. Successful training of reinforcement learning often requires numerous interactions with the environments, which hinders its applicability especially when the available computational resources are limited, or when there is no reliable simulation model. We identified an equivariance property of the quadrotor dynamics such that the dimension of the state required in the training is reduced by one, thereby improving the sampling efficiency of reinforcement learning substantially. This is illustrated by numerical examples with popular reinforcement learning techniques of TD3 and SAC.
Enlarging Discriminative Power by Adding an Extra Class in Unsupervised Domain Adaptation
Feb 19, 2020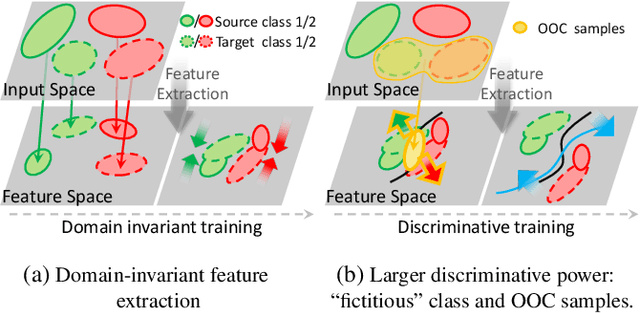
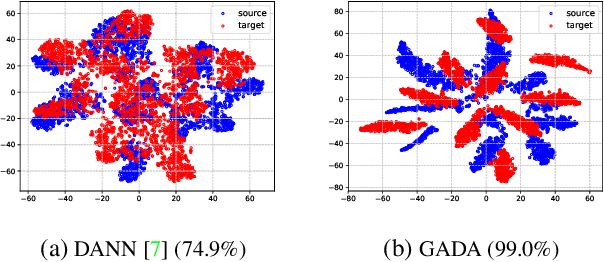
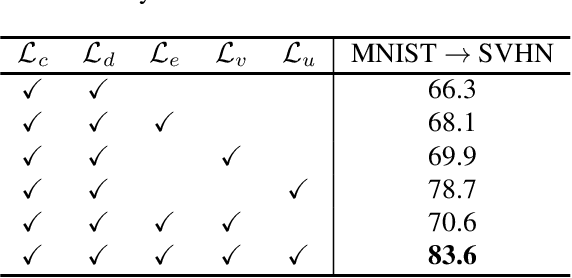
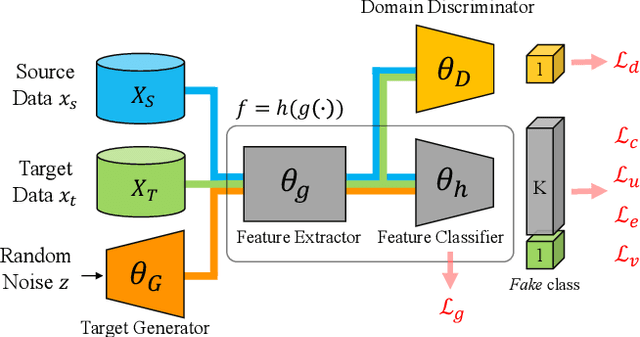
In this paper, we study the problem of unsupervised domain adaptation that aims at obtaining a prediction model for the target domain using labeled data from the source domain and unlabeled data from the target domain. There exists an array of recent research based on the idea of extracting features that are not only invariant for both domains but also provide high discriminative power for the target domain. In this paper, we propose an idea of empowering the discriminativeness: Adding a new, artificial class and training the model on the data together with the GAN-generated samples of the new class. The trained model based on the new class samples is capable of extracting the features that are more discriminative by repositioning data of current classes in the target domain and therefore drawing the decision boundaries more effectively. Our idea is highly generic so that it is compatible with many existing methods such as DANN, VADA, and DIRT-T. We conduct various experiments for the standard data commonly used for the evaluation of unsupervised domain adaptations and demonstrate that our algorithm achieves the SOTA performance for many scenarios.
Learning to Schedule Communication in Multi-agent Reinforcement Learning
Feb 05, 2019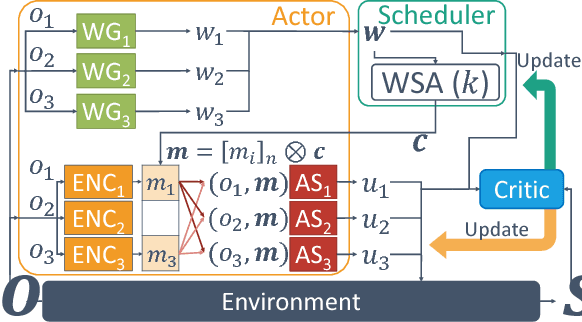

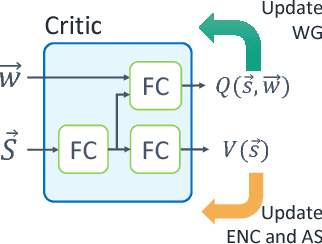

Many real-world reinforcement learning tasks require multiple agents to make sequential decisions under the agents' interaction, where well-coordinated actions among the agents are crucial to achieve the target goal better at these tasks. One way to accelerate the coordination effect is to enable multiple agents to communicate with each other in a distributed manner and behave as a group. In this paper, we study a practical scenario when (i) the communication bandwidth is limited and (ii) the agents share the communication medium so that only a restricted number of agents are able to simultaneously use the medium, as in the state-of-the-art wireless networking standards. This calls for a certain form of communication scheduling. In that regard, we propose a multi-agent deep reinforcement learning framework, called SchedNet, in which agents learn how to schedule themselves, how to encode the messages, and how to select actions based on received messages. SchedNet is capable of deciding which agents should be entitled to broadcasting their (encoded) messages, by learning the importance of each agent's partially observed information. We evaluate SchedNet against multiple baselines under two different applications, namely, cooperative communication and navigation, and predator-prey. Our experiments show a non-negligible performance gap between SchedNet and other mechanisms such as the ones without communication and with vanilla scheduling methods, e.g., round robin, ranging from 32% to 43%.