 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contractive Feedback Semantics for Reinforcement Learning
May 23, 2026Discounted reinforcement learning is usually presented through Bellman equations on closed Markov decision processes. This paper develops a compositional view: a one-step decision process is treated as an open stochastic component, and infinite-horizon policy evaluation is obtained by closing a contractive feedback loop. The resulting semantics assigns typed Bellman transformers to open components, interprets series and parallel wiring as composition and tensoring of transformers, and interprets feedback as an admissible guarded Banach trace realized by a unique fixed point. This perspective yields three theoretical consequences. First, approximate component equivalence is a contextual congruence for admitted well-typed guarded one-hole contexts: local operator error remains controlled after plugging the component into a surrounding circuit that uses the hole once and whose feedback nodes have certified uniform guardedness. Second, exact and approximate state abstractions become commuting or near-commuting coalgebraic diagrams, giving value-preservation and explicit sup-norm distortion bounds. Third, under monotone $ω$-continuous contract-transformer semantics, safety, risk, and resource specifications can be represented as quantale-valued contracts, where local inductive bounds lift through wiring and feedback by least-fixed-point reasoning. Its central claim is not that all RL morphisms form a global traced monoidal category, but that discounted Bellman evaluation admits a contractive feedback semantics on the admissible class of guarded circuits.
Matrix-Space Reinforcement Learning for Reusing Local Transition Geometry
May 14, 2026Compositional generalization in sequential decision-making requires identifying which parts of prior rollouts remain useful for new tasks. Existing methods reuse skills or predictive models, but often overlook rich local transition geometry and dynamics. We propose Matrix-Space Reinforcement Learning (MSRL), a geometric abstraction that represents trajectory segments through positive semidefinite matrix descriptors aggregating first- and second-order statistics of lifted one-step transitions. These descriptors expose shared hidden structure, support algebraic composition in an abstract matrix space, and reveal opportunities for transfer. We prove that the descriptor is well defined up to coordinate gauge, complete for the induced low-order additive signal class, additive under valid segment composition, and minimally sufficient among admissible additive descriptors. We further show that conditioning value functions on the trajectory-segment matrix yields a first-order smooth approximation of action values, enabling source-learned matrix-to-value mappings to bootstrap learning in new tasks. MSRL is plug-in compatible with standard model-free and model-based methods, while obstruction filtering rejects implausible compositions. Empirically, MSRL achieves the best average finite-budget target AUC of 0.73, outperforming MSRL from scratch (0.65), TD-MPC-PT+FT (0.63), and TD-MPC (0.57).
Operator-Guided Invariance Learning for Continuous Reinforcement Learning
May 07, 2026Reinforcement learning (RL) with continuous time and state/action spaces is often data-intensive and brittle under nuisance variability and shift, motivating methods that exploit value-preserving structures to stabilize and improve learning. Most existing approaches focus on special cases, such as prescribed symmetries and exact equivariance, without addressing how to discover more general structures that require nonlinear operators to transform and map between continuous state/action systems with isomorphic value functions. We propose \textbf{VPSD-RL} (Value-Preserving Structure Discovery for Reinforcement Learning). It models continuous RL as a controlled diffusion with value-preserving mappings defined through Lie-group actions and associated pullback operators. We show that a value-preserving structure exists exactly when pulling back the value function and pushing forward actions commute with the controlled generator and reward functional. Further, approximate value-preserving structures with rigorous guarantees can be found when the Hamilton--Jacobi--Bellman mismatch is small. This framework discovers exact and approximate value-preserving structures by searching for the associated Lie group operators. VPSD-RL fits differentiable drift, diffusion, and reward models; learns infinitesimal generators via determining-equation residual minimization; exponentiates them with ODE flows to obtain finite transformations; and integrates them into continuous RL through transition augmentation and transformation-consistency regularization. We show that bounded generator/reward mismatch implies quantitative stability of the optimal value function along approximate orbits, with sensitivity governed by the effective horizon, and observe improved data efficiency and robustness on continuous-control benchmarks.
Cochain Perspectives on Temporal-Difference Signals for Learning Beyond Markov Dynamics
Feb 06, 2026Non-Markovian dynamics are commonly found in real-world environments due to long-range dependencies, partial observability, and memory effects. The Bellman equation that is the central pillar of Reinforcement learning (RL) becomes only approximately valid under Non-Markovian. Existing work often focus on practical algorithm designs and offer limited theoretical treatment to address key questions, such as what dynamics are indeed capturable by the Bellman framework and how to inspire new algorithm classes with optimal approximations. In this paper, we present a novel topological viewpoint on temporal-difference (TD) based RL. We show that TD errors can be viewed as 1-cochain in the topological space of state transitions, while Markov dynamics are then interpreted as topological integrability. This novel view enables us to obtain a Hodge-type decomposition of TD errors into an integrable component and a topological residual, through a Bellman-de Rham projection. We further propose HodgeFlow Policy Search (HFPS) by fitting a potential network to minimize the non-integrable projection residual in RL, achieving stability/sensitivity guarantees. In numerical evaluations, HFPS is shown to significantly improve RL performance under non-Markovian.
Structuring Value Representations via Geometric Coherence in Markov Decision Processes
Feb 03, 2026Geometric properties can be leveraged to stabilize and speed reinforcement learning. Existing examples include encoding symmetry structure, geometry-aware data augmentation, and enforcing structural restrictions. In this paper, we take a novel view of RL through the lens of order theory and recast value function estimates into learning a desired poset (partially ordered set). We propose \emph{GCR-RL} (Geometric Coherence Regularized Reinforcement Learning) that computes a sequence of super-poset refinements -- by refining posets in previous steps and learning additional order relationships from temporal difference signals -- thus ensuring geometric coherence across the sequence of posets underpinning the learned value functions. Two novel algorithms by Q-learning and by actor--critic are developed to efficiently realize these super-poset refinements. Their theoretical properties and convergence rates are analyzed. We empirically evaluate GCR-RL in a range of tasks and demonstrate significant improvements in sample efficiency and stable performance over strong baselines.
Manifold-Constrained Energy-Based Transition Models for Offline Reinforcement Learning
Feb 02, 2026Model-based offline reinforcement learning is brittle under distribution shift: policy improvement drives rollouts into state--action regions weakly supported by the dataset, where compounding model error yields severe value overestimation. We propose Manifold-Constrained Energy-based Transition Models (MC-ETM), which train conditional energy-based transition models using a manifold projection--diffusion negative sampler. MC-ETM learns a latent manifold of next states and generates near-manifold hard negatives by perturbing latent codes and running Langevin dynamics in latent space with the learned conditional energy, sharpening the energy landscape around the dataset support and improving sensitivity to subtle out-of-distribution deviations. For policy optimization, the learned energy provides a single reliability signal: rollouts are truncated when the minimum energy over sampled next states exceeds a threshold, and Bellman backups are stabilized via pessimistic penalties based on Q-value-level dispersion across energy-guided samples. We formalize MC-ETM through a hybrid pessimistic MDP formulation and derive a conservative performance bound separating in-support evaluation error from truncation risk. Empirically, MC-ETM improves multi-step dynamics fidelity and yields higher normalized returns on standard offline control benchmarks, particularly under irregular dynamics and sparse data coverage.
Geometry of Drifting MDPs with Path-Integral Stability Certificates
Jan 29, 2026Real-world reinforcement learning is often \emph{nonstationary}: rewards and dynamics drift, accelerate, oscillate, and trigger abrupt switches in the optimal action. Existing theory often represents nonstationarity with coarse-scale models that measure \emph{how much} the environment changes, not \emph{how} it changes locally -- even though acceleration and near-ties drive tracking error and policy chattering. We take a geometric view of nonstationary discounted Markov Decision Processes (MDPs) by modeling the environment as a differentiable homotopy path and tracking the induced motion of the optimal Bellman fixed point. This yields a length-curvature-kink signature of intrinsic complexity: cumulative drift, acceleration/oscillation, and action-gap-induced nonsmoothness. We prove a solver-agnostic path-integral stability bound and derive gap-safe feasible regions that certify local stability away from switch regimes. Building on these results, we introduce \textit{Homotopy-Tracking RL (HT-RL)} and \textit{HT-MCTS}, lightweight wrappers that estimate replay-based proxies of length, curvature, and near-tie proximity online and adapt learning or planning intensity accordingly. Experiments show improved tracking and dynamic regret over matched static baselines, with the largest gains in oscillatory and switch-prone regimes.
Tail-Risk-Safe Monte Carlo Tree Search under PAC-Level Guarantees
Aug 07, 2025Making decisions with respect to just the expected returns in Monte Carlo Tree Search (MCTS) cannot account for the potential range of high-risk, adverse outcomes associated with a decision. To this end, safety-aware MCTS often consider some constrained variants -- by introducing some form of mean risk measures or hard cost thresholds. These approaches fail to provide rigorous tail-safety guarantees with respect to extreme or high-risk outcomes (denoted as tail-risk), potentially resulting in serious consequence in high-stake scenarios. This paper addresses the problem by developing two novel solutions. We first propose CVaR-MCTS, which embeds a coherent tail risk measure, Conditional Value-at-Risk (CVaR), into MCTS. Our CVaR-MCTS with parameter $\alpha$ achieves explicit tail-risk control over the expected loss in the "worst $(1-\alpha)\%$ scenarios." Second, we further address the estimation bias of tail-risk due to limited samples. We propose Wasserstein-MCTS (or W-MCTS) by introducing a first-order Wasserstein ambiguity set $\mathcal{P}_{\varepsilon_{s}}(s,a)$ with radius $\varepsilon_{s}$ to characterize the uncertainty in tail-risk estimates. We prove PAC tail-safety guarantees for both CVaR-MCTS and W-MCTS and establish their regret. Evaluations on diverse simulated environments demonstrate that our proposed methods outperform existing baselines, effectively achieving robust tail-risk guarantees with improved rewards and stability.
Second-Order Convergence in Private Stochastic Non-Convex Optimization
May 21, 2025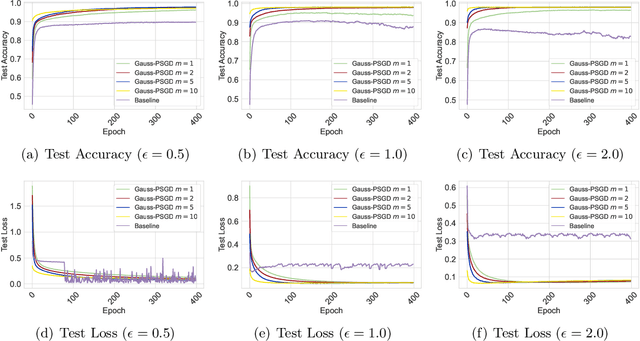
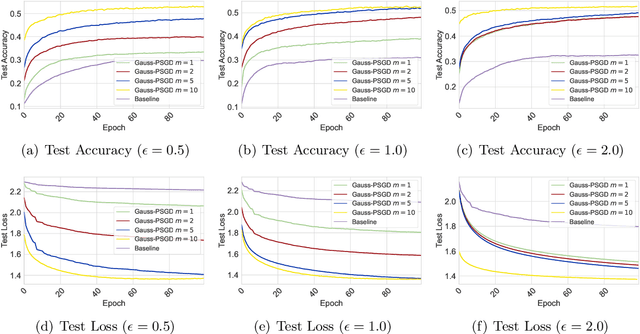
We investigate the problem of finding second-order stationary points (SOSP) in differentially private (DP) stochastic non-convex optimization. Existing methods suffer from two key limitations: (i) inaccurate convergence error rate due to overlooking gradient variance in the saddle point escape analysis, and (ii) dependence on auxiliary private model selection procedures for identifying DP-SOSP, which can significantly impair utility, particularly in distributed settings. To address these issues, we propose a generic perturbed stochastic gradient descent (PSGD) framework built upon Gaussian noise injection and general gradient oracles. A core innovation of our framework is using model drift distance to determine whether PSGD escapes saddle points, ensuring convergence to approximate local minima without relying on second-order information or additional DP-SOSP identification. By leveraging the adaptive DP-SPIDER estimator as a specific gradient oracle, we develop a new DP algorithm that rectifies the convergence error rates reported in prior work. We further extend this algorithm to distributed learning with arbitrarily heterogeneous data, providing the first formal guarantees for finding DP-SOSP in such settings. Our analysis also highlights the detrimental impacts of private selection procedures in distributed learning under high-dimensional models, underscoring the practical benefits of our design. Numerical experiments on real-world datasets validate the efficacy of our approach.
Network Diffuser for Placing-Scheduling Service Function Chains with Inverse Demonstration
Jan 10, 2025Network services are increasingly managed by considering chained-up virtual network functions and relevant traffic flows, known as the Service Function Chains (SFCs). To deal with sequential arrivals of SFCs in an online fashion, we must consider two closely-coupled problems - an SFC placement problem that maps SFCs to servers/links in the network and an SFC scheduling problem that determines when each SFC is executed. Solving the whole SFC problem targeting these two optimizations jointly is extremely challenging. In this paper, we propose a novel network diffuser using conditional generative modeling for this SFC placing-scheduling optimization. Recent advances in generative AI and diffusion models have made it possible to generate high-quality images/videos and decision trajectories from language description. We formulate the SFC optimization as a problem of generating a state sequence for planning and perform graph diffusion on the state trajectories to enable extraction of SFC decisions, with SFC optimization constraints and objectives as conditions. To address the lack of demonstration data due to NP-hardness and exponential problem space of the SFC optimization, we also propose a novel and somewhat maverick approach -- Rather than solving instances of this difficult optimization, we start with randomly-generated solutions as input, and then determine appropriate SFC optimization problems that render these solutions feasible. This inverse demonstration enables us to obtain sufficient expert demonstrations, i.e., problem-solution pairs, through further optimization. In our numerical evaluations, the proposed network diffuser outperforms learning and heuristic baselines, by $\sim$20\% improvement in SFC reward and $\sim$50\% reduction in SFC waiting time and blocking rate.