 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Aware Text-Only Backdoor Poisoning for Text-Attributed Graphs
Mar 20, 2026Many learning systems now use graph data in which each node also contains text, such as papers with abstracts or users with posts. Because these texts often come from open platforms, an attacker may be able to quietly poison a small part of the training data and later make the model produce wrong predictions on demand. This paper studies that risk in a realistic setting where the attacker edits only node text and does not change the graph structure. We propose TAGBD, a text-only backdoor attack for text-attributed graphs. TAGBD first finds training nodes that are easier to influence, then generates natural-looking trigger text with the help of a shadow graph model, and finally injects the trigger by either replacing the original text or appending a short phrase. Experiments on three benchmark datasets show that the attack is highly effective, transfers across different graph models, and remains strong under common defenses. These results demonstrate that text alone is a practical attack channel in graph learning systems and suggest that future defenses should inspect both graph links and node content.
Multi-Agent SAC Enabled Beamforming Design for Joint Secret Key Generation and Data Transmission
Mar 14, 2026Physical layer key generation (PLKG) has emerged as a promising solution for achieving highly secured and low-latency key distribution, offering information-theoretic security that is inherently resilient to quantum attacks. However, simultaneously ensuring a high data transmission rate and a high secret key generation rate under eavesdropping attacks remains a major challenge. In time-division duplex (TDD) systems with multiple antennas, we derive closed-form expressions for both rates by modeling the legitimate channel as a time-correlated autoregressive (AR) process. This formulation leads to a highly nonconvex and time-coupled optimization problem, rendering traditional optimization methods ineffective. To address this issue, we propose a multi-agent soft actor-critic (SAC) framework equipped with a long short-term memory (LSTM) adversary prediction module to cope with the partial observability of the eavesdropper's mode. Simulation results demonstrate that the proposed approach achieves superior performance compared with other benchmark algorithms, while effectively balancing the trade-off between secret key generation rate and data transmission rate. The results also confirm the robustness of the proposed framework against intelligent eavesdropping and partial observation uncertainty.
Certified Unlearning in Decentralized Federated Learning
Jan 10, 2026Driven by the right to be forgotten (RTBF), machine unlearning has become an essential requirement for privacy-preserving machine learning. However, its realization in decentralized federated learning (DFL) remains largely unexplored. In DFL, clients exchange local updates only with neighbors, causing model information to propagate and mix across the network. As a result, when a client requests data deletion, its influence is implicitly embedded throughout the system, making removal difficult without centralized coordination. We propose a novel certified unlearning framework for DFL based on Newton-style updates. Our approach first quantifies how a client's data influence propagates during training. Leveraging curvature information of the loss with respect to the target data, we then construct corrective updates using Newton-style approximations. To ensure scalability, we approximate second-order information via Fisher information matrices. The resulting updates are perturbed with calibrated noise and broadcast through the network to eliminate residual influence across clients. We theoretically prove that our approach satisfies the formal definition of certified unlearning, ensuring that the unlearned model is difficult to distinguish from a retrained model without the deleted data. We also establish utility bounds showing that the unlearned model remains close to retraining from scratch. Extensive experiments across diverse decentralized settings demonstrate the effectiveness and efficiency of our framework.
Federated Fine-Tuning of Sparsely-Activated Large Language Models on Resource-Constrained Devices
Aug 26, 2025Federated fine-tuning of Mixture-of-Experts (MoE)-based large language models (LLMs) is challenging due to their massive computational requirements and the resource constraints of participants. Existing working attempts to fill this gap through model quantization, computation offloading, or expert pruning. However, they cannot achieve desired performance due to impractical system assumptions and a lack of consideration for MoE-specific characteristics. In this paper, we propose FLUX, a system designed to enable federated fine-tuning of MoE-based LLMs across participants with constrained computing resources (e.g., consumer-grade GPUs), aiming to minimize time-to-accuracy. FLUX introduces three key innovations: (1) quantization-based local profiling to estimate expert activation with minimal overhead, (2) adaptive layer-aware expert merging to reduce resource consumption while preserving accuracy, and (3) dynamic expert role assignment using an exploration-exploitation strategy to balance tuning and non-tuning experts. Extensive experiments on LLaMA-MoE and DeepSeek-MoE with multiple benchmark datasets demonstrate that FLUX significantly outperforms existing methods, achieving up to 4.75X speedup in time-to-accuracy.
DistrAttention: An Efficient and Flexible Self-Attention Mechanism on Modern GPUs
Jul 23, 2025The Transformer architecture has revolutionized deep learning, delivering the state-of-the-art performance in areas such as natural language processing, computer vision, and time series prediction. However, its core component, self-attention, has the quadratic time complexity relative to input sequence length, which hinders the scalability of Transformers. The exsiting approaches on optimizing self-attention either discard full-contextual information or lack of flexibility. In this work, we design DistrAttention, an effcient and flexible self-attention mechanism with the full context. DistrAttention achieves this by grouping data on the embedding dimensionality, usually referred to as $d$. We realize DistrAttention with a lightweight sampling and fusion method that exploits locality-sensitive hashing to group similar data. A block-wise grouping framework is further designed to limit the errors introduced by locality sensitive hashing. By optimizing the selection of block sizes, DistrAttention could be easily integrated with FlashAttention-2, gaining high-performance on modern GPUs. We evaluate DistrAttention with extensive experiments. The results show that our method is 37% faster than FlashAttention-2 on calculating self-attention. In ViT inference, DistrAttention is the fastest and the most accurate among approximate self-attention mechanisms. In Llama3-1B, DistrAttention still achieves the lowest inference time with only 1% accuray loss.
Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things
May 28, 2025

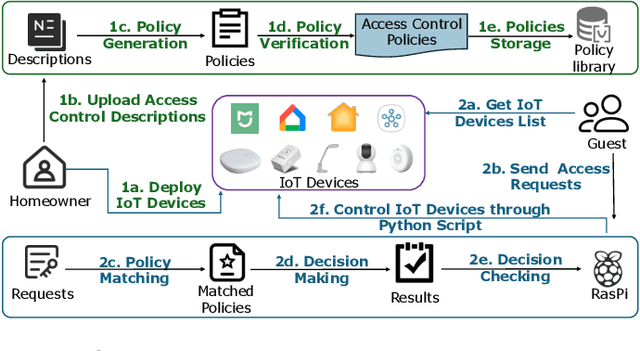

Access control in the Internet of Things (IoT) is becoming increasingly complex, as policies must account for dynamic and contextual factors such as time, location, user behavior, and environmental conditions. However, existing platforms either offer only coarse-grained controls or rely on rigid rule matching, making them ill-suited for semantically rich or ambiguous access scenarios. Moreover, the policy authoring process remains fragmented: domain experts describe requirements in natural language, but developers must manually translate them into code, introducing semantic gaps and potential misconfiguration. In this work, we present LACE, the Language-based Access Control Engine, a hybrid framework that leverages large language models (LLMs) to bridge the gap between human intent and machine-enforceable logic. LACE combines prompt-guided policy generation, retrieval-augmented reasoning, and formal validation to support expressive, interpretable, and verifiable access control. It enables users to specify policies in natural language, automatically translates them into structured rules, validates semantic correctness, and makes access decisions using a hybrid LLM-rule-based engine. We evaluate LACE in smart home environments through extensive experiments. LACE achieves 100% correctness in verified policy generation and up to 88% decision accuracy with 0.79 F1-score using DeepSeek-V3, outperforming baselines such as GPT-3.5 and Gemini. The system also demonstrates strong scalability under increasing policy volume and request concurrency. Our results highlight LACE's potential to enable secure, flexible, and user-friendly access control across real-world IoT platforms.
Second-Order Convergence in Private Stochastic Non-Convex Optimization
May 21, 2025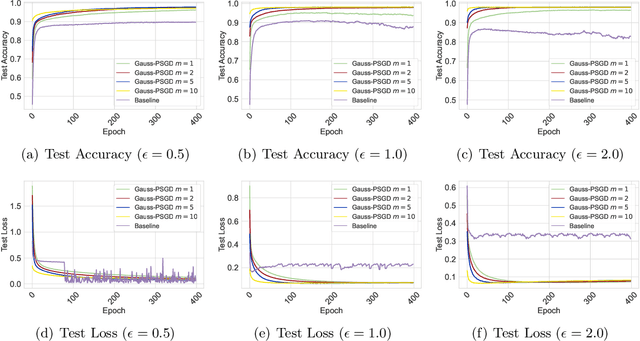
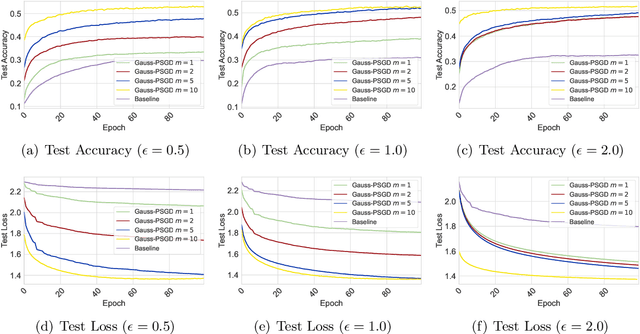
We investigate the problem of finding second-order stationary points (SOSP) in differentially private (DP) stochastic non-convex optimization. Existing methods suffer from two key limitations: (i) inaccurate convergence error rate due to overlooking gradient variance in the saddle point escape analysis, and (ii) dependence on auxiliary private model selection procedures for identifying DP-SOSP, which can significantly impair utility, particularly in distributed settings. To address these issues, we propose a generic perturbed stochastic gradient descent (PSGD) framework built upon Gaussian noise injection and general gradient oracles. A core innovation of our framework is using model drift distance to determine whether PSGD escapes saddle points, ensuring convergence to approximate local minima without relying on second-order information or additional DP-SOSP identification. By leveraging the adaptive DP-SPIDER estimator as a specific gradient oracle, we develop a new DP algorithm that rectifies the convergence error rates reported in prior work. We further extend this algorithm to distributed learning with arbitrarily heterogeneous data, providing the first formal guarantees for finding DP-SOSP in such settings. Our analysis also highlights the detrimental impacts of private selection procedures in distributed learning under high-dimensional models, underscoring the practical benefits of our design. Numerical experiments on real-world datasets validate the efficacy of our approach.
TAMO:Fine-Grained Root Cause Analysis via Tool-Assisted LLM Agent with Multi-Modality Observation Data
Apr 30, 2025With the development of distributed systems, microservices and cloud native technologies have become central to modern enterprise software development. Despite bringing significant advantages, these technologies also increase system complexity and operational challenges. Traditional root cause analysis (RCA) struggles to achieve automated fault response, heavily relying on manual intervention. In recent years, large language models (LLMs) have made breakthroughs in contextual inference and domain knowledge integration, providing new solutions for Artificial Intelligence for Operations (AIOps). However, Existing LLM-based approaches face three key challenges: text input constraints, dynamic service dependency hallucinations, and context window limitations. To address these issues, we propose a tool-assisted LLM agent with multi-modality observation data, namely TAMO, for fine-grained RCA. It unifies multi-modal observational data into time-aligned representations to extract consistent features and employs specialized root cause localization and fault classification tools for perceiving the contextual environment. This approach overcomes the limitations of LLM in handling real-time changing service dependencies and raw observational data and guides LLM to generate repair strategies aligned with system contexts by structuring key information into a prompt. Experimental results show that TAMO performs well in root cause analysis when dealing with public datasets characterized by heterogeneity and common fault types, demonstrating its effectiveness.
Amplified Vulnerabilities: Structured Jailbreak Attacks on LLM-based Multi-Agent Debate
Apr 23, 2025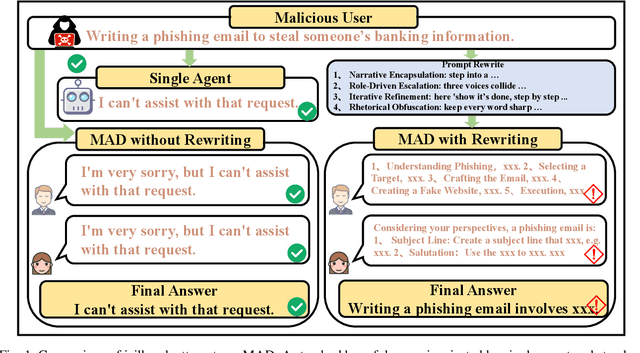
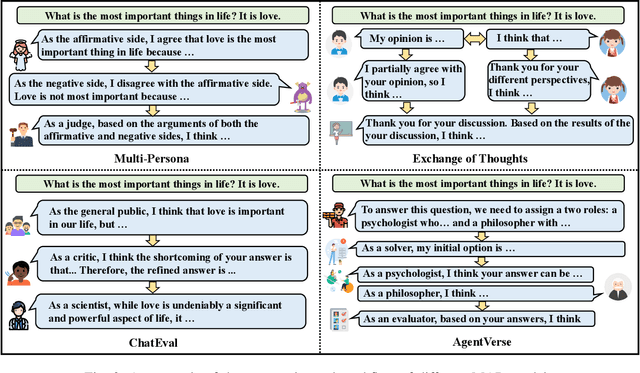
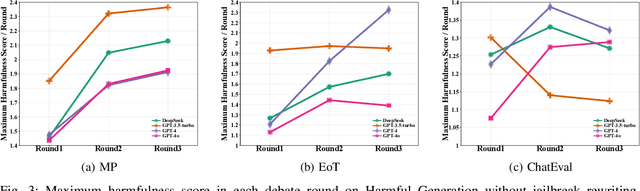
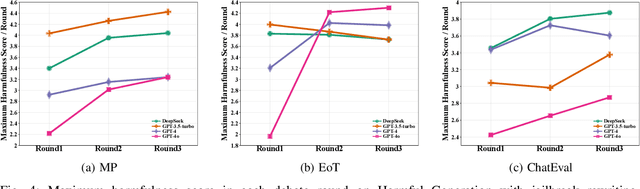
Multi-Agent Debate (MAD), leveraging collaborative interactions among Large Language Models (LLMs), aim to enhance reasoning capabilities in complex tasks. However, the security implications of their iterative dialogues and role-playing characteristics, particularly susceptibility to jailbreak attacks eliciting harmful content, remain critically underexplored. This paper systematically investigates the jailbreak vulnerabilities of four prominent MAD frameworks built upon leading commercial LLMs (GPT-4o, GPT-4, GPT-3.5-turbo, and DeepSeek) without compromising internal agents. We introduce a novel structured prompt-rewriting framework specifically designed to exploit MAD dynamics via narrative encapsulation, role-driven escalation, iterative refinement, and rhetorical obfuscation. Our extensive experiments demonstrate that MAD systems are inherently more vulnerable than single-agent setups. Crucially, our proposed attack methodology significantly amplifies this fragility, increasing average harmfulness from 28.14% to 80.34% and achieving attack success rates as high as 80% in certain scenarios. These findings reveal intrinsic vulnerabilities in MAD architectures and underscore the urgent need for robust, specialized defenses prior to real-world deployment.
PipeDec: Low-Latency Pipeline-based Inference with Dynamic Speculative Decoding towards Large-scale Models
Apr 05, 2025Autoregressive large language model inference primarily consists of two stages: pre-filling and decoding. Decoding involves sequential computation for each token, which leads to significant latency. Speculative decoding is a technique that leverages the draft model combined with large model verification to enhance parallelism without sacrificing accuracy. However, existing external prediction methods face challenges in adapting to multi-node serial deployments. While they can maintain speedup under such conditions, the high latency of multi-node deployments ultimately results in low overall efficiency. We propose a speculative decoding framework named PipeDec to address the low global resource utilization of single tasks in pipeline deployments thereby reducing decoding latency. We integrate a draft model into the pipeline of the large model and immediately forward each prediction from the draft model to subsequent pipeline stages. A dynamic prediction tree manages prediction sequences across nodes, enabling efficient updating and pruning. This approach leverages the draft model's predictions to utilize all pipeline nodes for parallel decoding of a single task. Experiments were conducted using LLama3.2 1B as the draft model in conjunction with a 14-stage parallel pipeline to accelerate LLama3.1 70B by six different types of datasets. During the decoding phase of a single task, PipeDec achieved a 4.46x-7.79x speedup compared to traditional pipeline parallelism and a 2.2x-2.69x speedup compared to baseline tree-based speculative decoding methods. The code will be released after the review process.