 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Depth Enhanced Learning with Obstacle Map For Object Navigation
Jun 20, 2024The task that requires an agent to navigate to a given object through only visual observation is called visual object navigation (VON). The main bottlenecks of VON are strategies exploration and prior knowledge exploitation. Traditional strategies exploration ignores the differences of searching and navigating stages, using the same reward in two stages, which reduces navigation performance and training efficiency. Our study enables the agent to explore larger area in searching stage and seek the optimal path in navigating stage, improving the success rate of navigation. Traditional prior knowledge exploitation focused on learning and utilizing object association, which ignored the depth and obstacle information in the environment. This paper uses the RGB and depth information of the training scene to pretrain the feature extractor, which improves navigation efficiency. The obstacle information is memorized by the agent during the navigation, reducing the probability of collision and deadlock. Depth, obstacle and other prior knowledge are concatenated and input into the policy network, and navigation actions are output under the training of two-stage rewards. We evaluated our method on AI2-Thor and RoboTHOR and demonstrated that it significantly outperforms state-of-the-art (SOTA) methods on success rate and navigation efficiency.
A Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.
Temporal-Spatial Object Relations Modeling for Vision-and-Language Navigation
Mar 23, 2024Vision-and-Language Navigation (VLN) is a challenging task where an agent is required to navigate to a natural language described location via vision observations. The navigation abilities of the agent can be enhanced by the relations between objects, which are usually learned using internal objects or external datasets. The relationships between internal objects are modeled employing graph convolutional network (GCN) in traditional studies. However, GCN tends to be shallow, limiting its modeling ability. To address this issue, we utilize a cross attention mechanism to learn the connections between objects over a trajectory, which takes temporal continuity into account, termed as Temporal Object Relations (TOR). The external datasets have a gap with the navigation environment, leading to inaccurate modeling of relations. To avoid this problem, we construct object connections based on observations from all viewpoints in the navigational environment, which ensures complete spatial coverage and eliminates the gap, called Spatial Object Relations (SOR). Additionally, we observe that agents may repeatedly visit the same location during navigation, significantly hindering their performance. For resolving this matter, we introduce the Turning Back Penalty (TBP) loss function, which penalizes the agent's repetitive visiting behavior, substantially reducing the navigational distance. Experimental results on the REVERIE, SOON, and R2R datasets demonstrate the effectiveness of the proposed method.
CPCL: Cross-Modal Prototypical Contrastive Learning for Weakly Supervised Text-based Person Re-Identification
Jan 18, 2024Weakly supervised text-based person re-identification (TPRe-ID) seeks to retrieve images of a target person using textual descriptions, without relying on identity annotations and is more challenging and practical. The primary challenge is the intra-class differences, encompassing intra-modal feature variations and cross-modal semantic gaps. Prior works have focused on instance-level samples and ignored prototypical features of each person which are intrinsic and invariant. Toward this, we propose a Cross-Modal Prototypical Contrastive Learning (CPCL) method. In practice, the CPCL introduces the CLIP model to weakly supervised TPRe-ID for the first time, mapping visual and textual instances into a shared latent space. Subsequently, the proposed Prototypical Multi-modal Memory (PMM) module captures associations between heterogeneous modalities of image-text pairs belonging to the same person through the Hybrid Cross-modal Matching (HCM) module in a many-to-many mapping fashion. Moreover, the Outlier Pseudo Label Mining (OPLM) module further distinguishes valuable outlier samples from each modality, enhancing the creation of more reliable clusters by mining implicit relationships between image-text pairs. Experimental results demonstrate that our proposed CPCL attains state-of-the-art performance on all three public datasets, with a significant improvement of 11.58%, 8.77% and 5.25% in Rank@1 accuracy on CUHK-PEDES, ICFG-PEDES and RSTPReid datasets, respectively. The code is available at https://github.com/codeGallery24/CPCL.
Policy Learning based on Deep Koopman Representation
May 24, 2023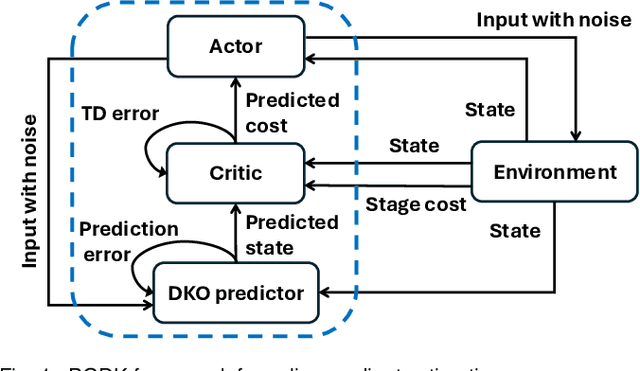
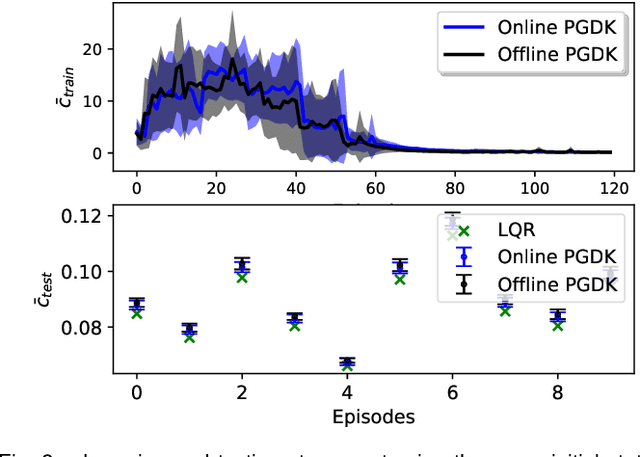
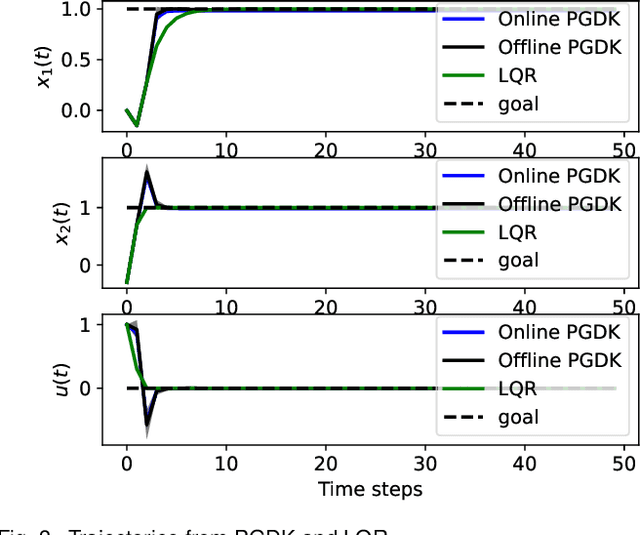
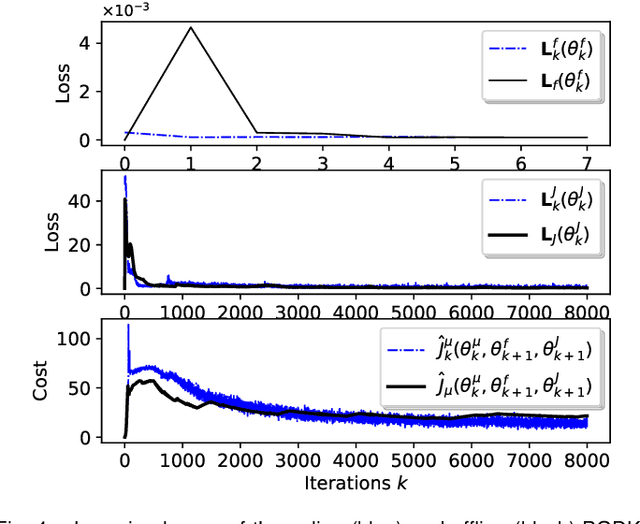
This paper proposes a policy learning algorithm based on the Koopman operator theory and policy gradient approach, which seeks to approximate an unknown dynamical system and search for optimal policy simultaneously, using the observations gathered through interaction with the environment. The proposed algorithm has two innovations: first, it introduces the so-called deep Koopman representation into the policy gradient to achieve a linear approximation of the unknown dynamical system, all with the purpose of improving data efficiency; second, the accumulated errors for long-term tasks induced by approximating system dynamics are avoided by applying Bellman's principle of optimality. Furthermore, a theoretical analysis is provided to prove the asymptotic convergence of the proposed algorithm and characterize the corresponding sampling complexity. These conclusions are also supported by simulations on several challenging benchmark environments.
CSMCNet: Scalable Video Compressive Sensing Reconstruction with Interpretable Motion Estimation
Aug 03, 2021


Most deep network methods for compressive sensing reconstruction suffer from the black-box characteristic of DNN. In this paper, a deep neural network with interpretable motion estimation named CSMCNet is proposed. The network is able to realize high-quality reconstruction of video compressive sensing by unfolding the iterative steps of optimization based algorithms. A DNN based, multi-hypothesis motion estimation module is designed to improve the reconstruction quality, and a residual module is employed to further narrow down the gap between re-construction results and original signal in our proposed method. Besides, we propose an interpolation module with corresponding training strategy to realize scalable CS reconstruction, which is capable of using the same model to decode various compression ratios. Experiments show that a PSNR of 29.34dB can be achieved at 2% CS ratio (compressed by 98%), which is superior than other state-of-the-art methods. Moreover, the interpolation module is proved to be effective, with significant cost saving and acceptable performance losses.