 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3D: Cascade Control with Change Point Detection and Deep Koopman Learning for Autonomous Surface Vehicles
Mar 14, 2024In this paper, we discuss the development and deployment of a robust autonomous system capable of performing various tasks in the maritime domain under unknown dynamic conditions. We investigate a data-driven approach based on modular design for ease of transfer of autonomy across different maritime surface vessel platforms. The data-driven approach alleviates issues related to a priori identification of system models that may become deficient under evolving system behaviors or shifting, unanticipated, environmental influences. Our proposed learning-based platform comprises a deep Koopman system model and a change point detector that provides guidance on domain shifts prompting relearning under severe exogenous and endogenous perturbations. Motion control of the autonomous system is achieved via an optimal controller design. The Koopman linearized model naturally lends itself to a linear-quadratic regulator (LQR) control design. We propose the C3D control architecture Cascade Control with Change Point Detection and Deep Koopman Learning. The framework is verified in station keeping task on an ASV in both simulation and real experiments. The approach achieved at least 13.9 percent improvement in mean distance error in all test cases compared to the methods that do not consider system changes.
Adaptive Policy Learning to Additional Tasks
May 24, 2023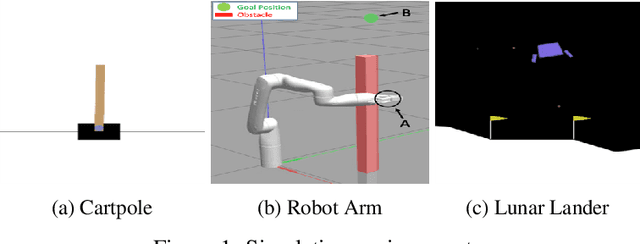
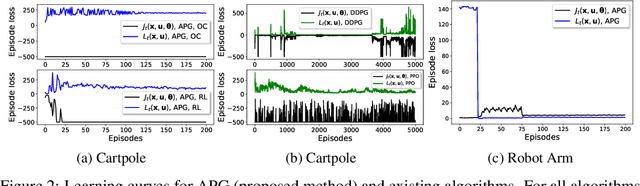
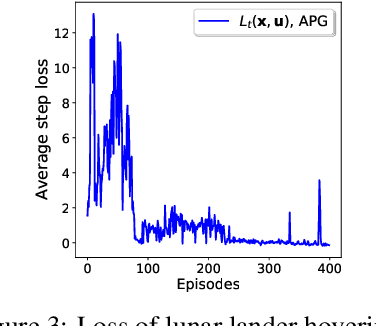
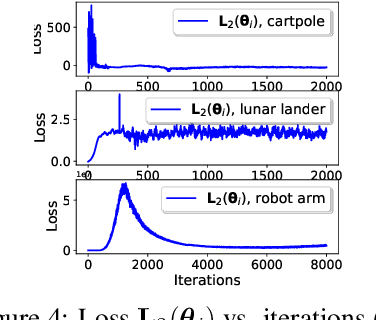
This paper develops a policy learning method for tuning a pre-trained policy to adapt to additional tasks without altering the original task. A method named Adaptive Policy Gradient (APG) is proposed in this paper, which combines Bellman's principle of optimality with the policy gradient approach to improve the convergence rate. This paper provides theoretical analysis which guarantees the convergence rate and sample complexity of $\mathcal{O}(1/T)$ and $\mathcal{O}(1/\epsilon)$, respectively, where $T$ denotes the number of iterations and $\epsilon$ denotes the accuracy of the resulting stationary policy. Furthermore, several challenging numerical simulations, including cartpole, lunar lander, and robot arm, are provided to show that APG obtains similar performance compared to existing deterministic policy gradient methods while utilizing much less data and converging at a faster rate.
Policy Learning based on Deep Koopman Representation
May 24, 2023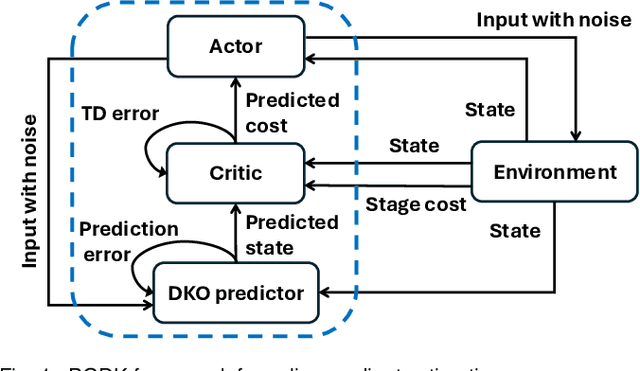
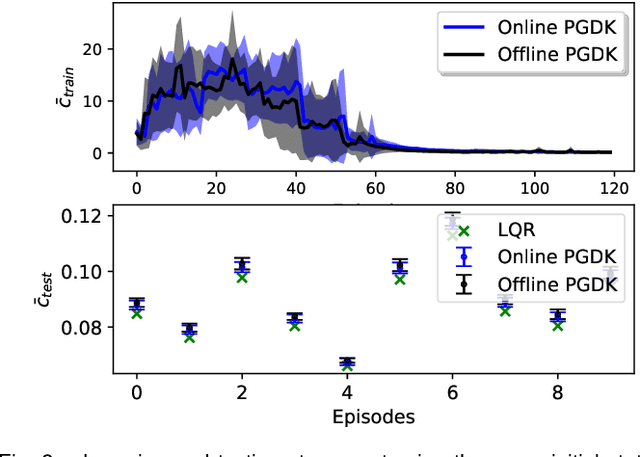
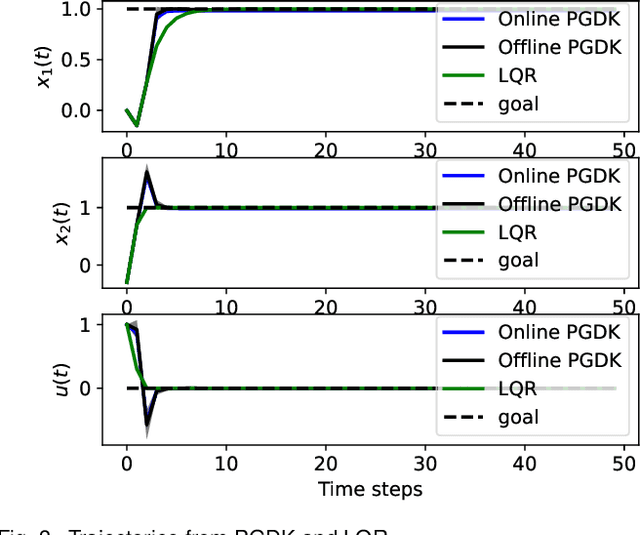
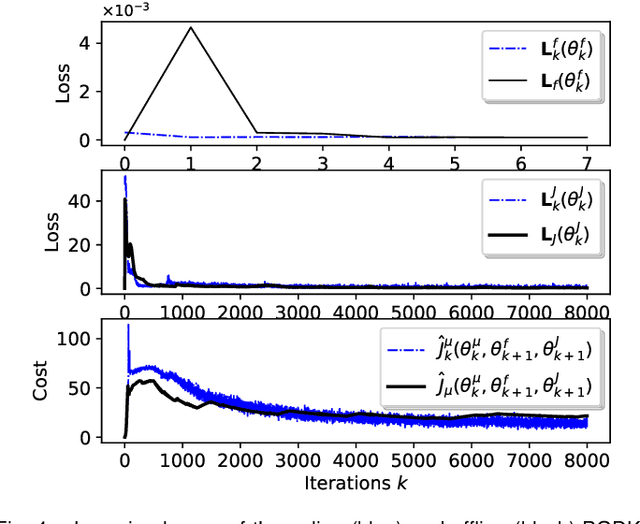
This paper proposes a policy learning algorithm based on the Koopman operator theory and policy gradient approach, which seeks to approximate an unknown dynamical system and search for optimal policy simultaneously, using the observations gathered through interaction with the environment. The proposed algorithm has two innovations: first, it introduces the so-called deep Koopman representation into the policy gradient to achieve a linear approximation of the unknown dynamical system, all with the purpose of improving data efficiency; second, the accumulated errors for long-term tasks induced by approximating system dynamics are avoided by applying Bellman's principle of optimality. Furthermore, a theoretical analysis is provided to prove the asymptotic convergence of the proposed algorithm and characterize the corresponding sampling complexity. These conclusions are also supported by simulations on several challenging benchmark environments.
Deep Learning of Koopman Representation for Control
Oct 15, 2020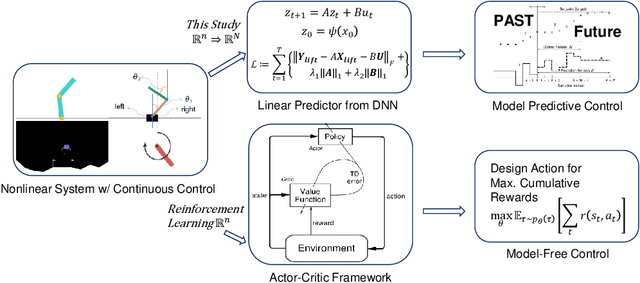
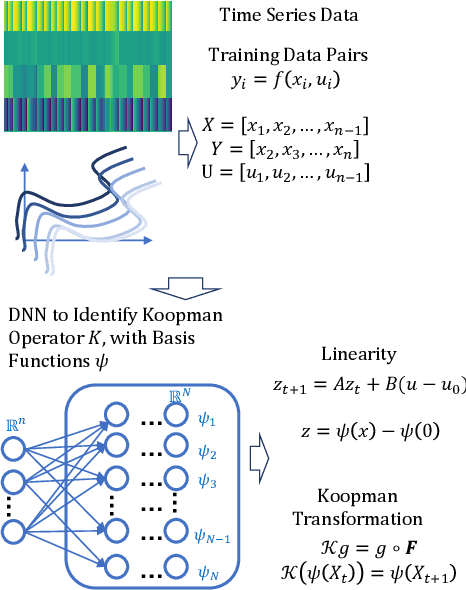

We develop a data-driven, model-free approach for the optimal control of the dynamical system. The proposed approach relies on the Deep Neural Network (DNN) based learning of Koopman operator for the purpose of control. In particular, DNN is employed for the data-driven identification of basis function used in the linear lifting of nonlinear control system dynamics. The controller synthesis is purely data-driven and does not rely on a priori domain knowledge. The OpenAI Gym environment, employed for Reinforcement Learning-based control design, is used for data generation and learning of Koopman operator in control setting. The method is applied to two classic dynamical systems on OpenAI Gym environment to demonstrate the capability.
Cell A* for Navigation of Unmanned Aerial Vehicles in Partially-known Environments
Sep 16, 2020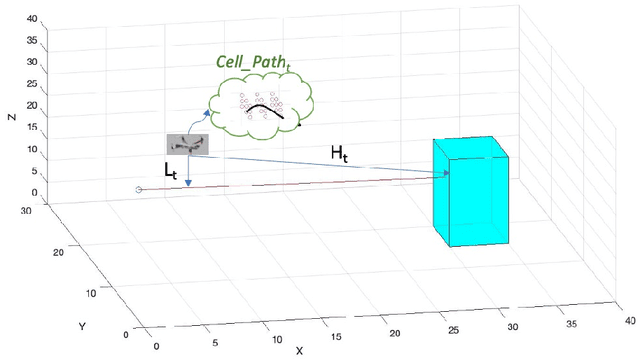


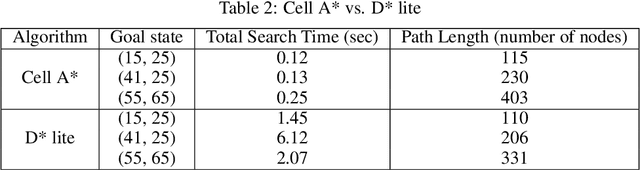
Proper path planning is the first step of robust and efficient autonomous navigation for mobile robots. Meanwhile, it is still challenging for robots to work in a complex environment without complete prior information. This paper presents an extension to the A* search algorithm and its variants to make the path planning stable with less computational burden while handling long-distance tasks. The implemented algorithm is capable of online searching for a collision-free and smooth path when heading to the defined goal position. This paper deploys the algorithm on the autonomous drone platform and implements it on a remote control car for algorithm efficiency validation.
Data Driven Control with Learned Dynamics: Model-Based versus Model-Free Approach
Jun 16, 2020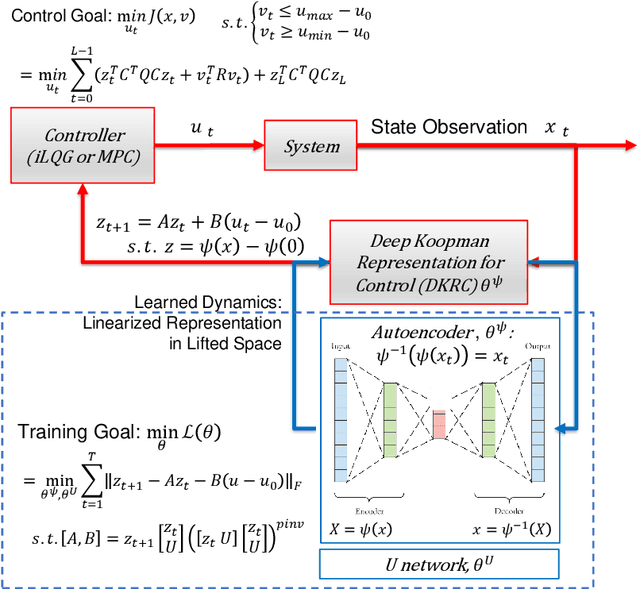
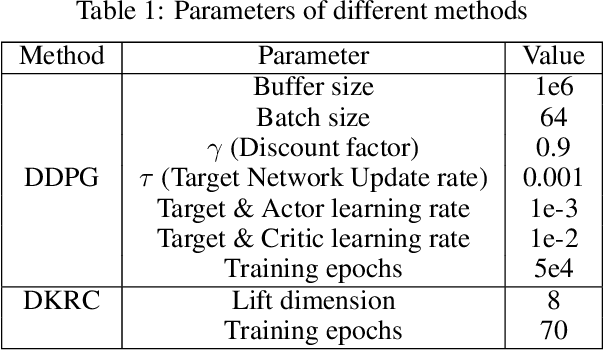
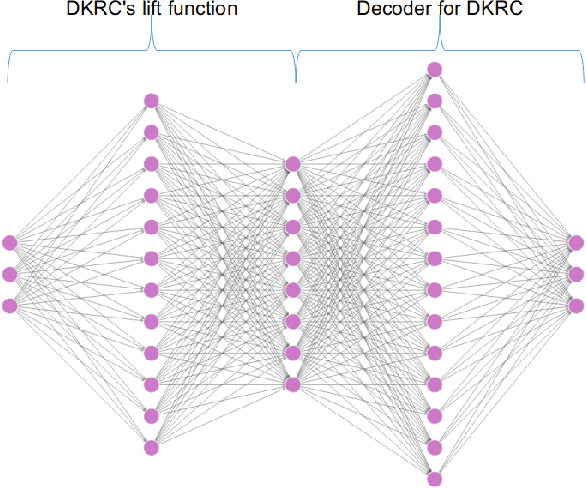
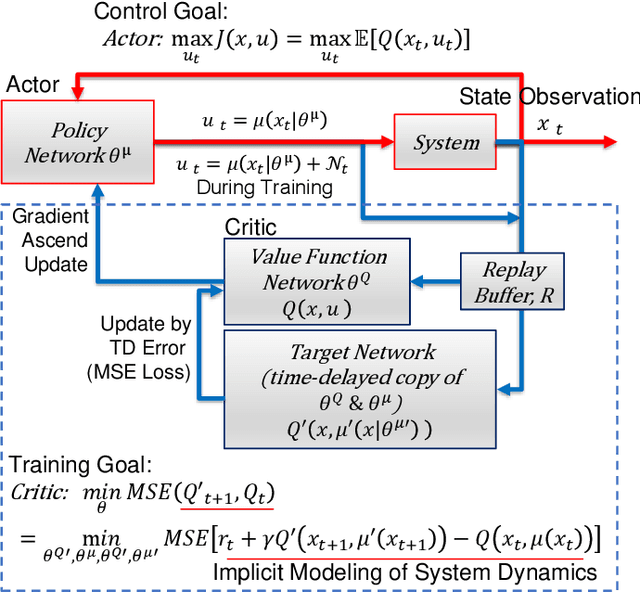
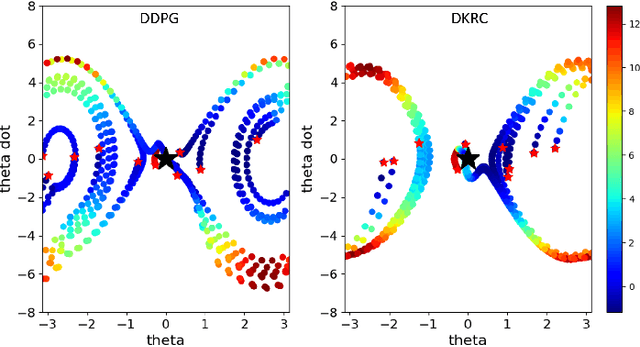
This paper compares two different types of data-driven control methods, representing model-based and model-free approaches. One is a recently proposed method - Deep Koopman Representation for Control (DKRC), which utilizes a deep neural network to map an unknown nonlinear dynamical system to a high-dimensional linear system, which allows for employing state-of-the-art control strategy. The other one is a classic model-free control method based on an actor-critic architecture - Deep Deterministic Policy Gradient (DDPG), which has been proved to be effective in various dynamical systems. The comparison is carried out in OpenAI Gym, which provides multiple control environments for benchmark purposes. Two examples are provided for comparison, i.e., classic Inverted Pendulum and Lunar Lander Continuous Control. From the results of the experiments, we compare these two methods in terms of control strategies and the effectiveness under various initialization conditions. We also examine the learned dynamic model from DKRC with the analytical model derived from the Euler-Lagrange Linearization method, which demonstrates the accuracy in the learned model for unknown dynamics from a data-driven sample-efficient approach.