 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Learning based on Deep Koopman Representation
Paper and Code
May 24, 2023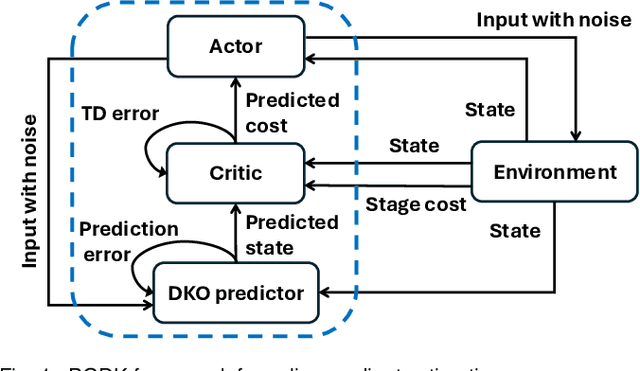
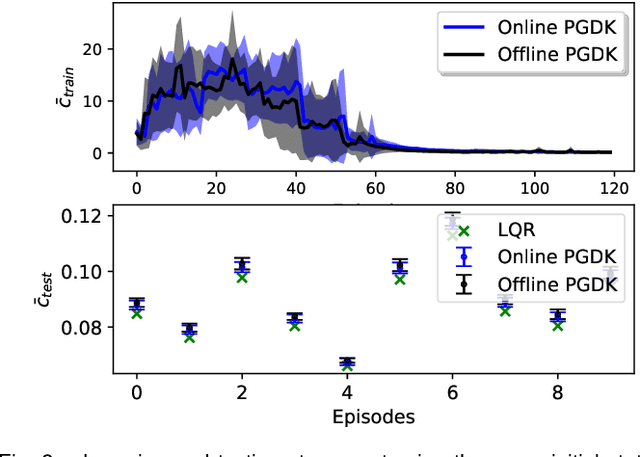
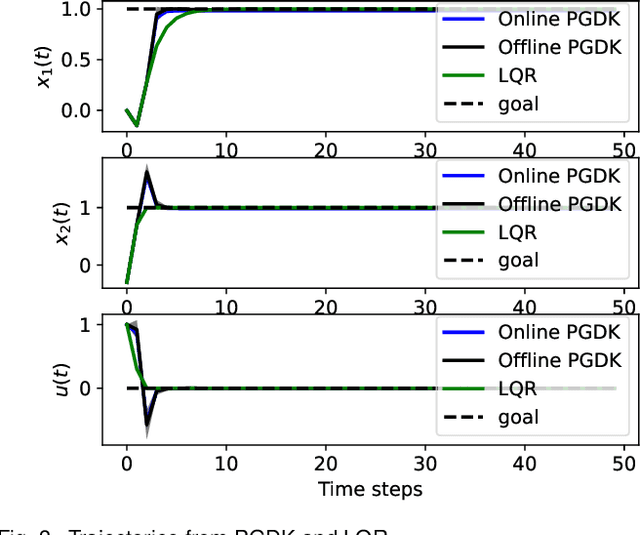
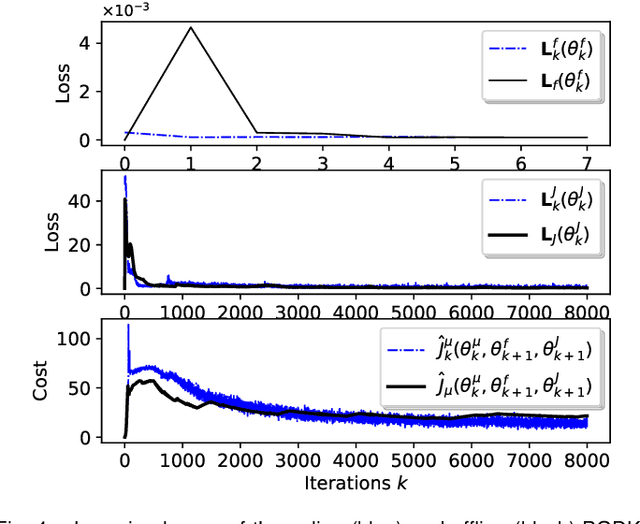
This paper proposes a policy learning algorithm based on the Koopman operator theory and policy gradient approach, which seeks to approximate an unknown dynamical system and search for optimal policy simultaneously, using the observations gathered through interaction with the environment. The proposed algorithm has two innovations: first, it introduces the so-called deep Koopman representation into the policy gradient to achieve a linear approximation of the unknown dynamical system, all with the purpose of improving data efficiency; second, the accumulated errors for long-term tasks induced by approximating system dynamics are avoided by applying Bellman's principle of optimality. Furthermore, a theoretical analysis is provided to prove the asymptotic convergence of the proposed algorithm and characterize the corresponding sampling complexity. These conclusions are also supported by simulations on several challenging benchmark environments.