 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM-Chunk: Reactive Action Chunking with Latent World Model
Jun 17, 2026Action chunking has become a common interface for vision-language-action (VLA) models, enabling low-frequency policy inference to drive high-frequency robot execution. However, once an action chunk is committed, its open-loop execution can be brittle under stochastic dynamics, hardware execution errors, and partial observability. We propose DREAM-Chunk, a test-time scaling method that augments chunking-based policies with a lightweight latent world model, without requiring additional policy fine-tuning. At test time, DREAM-Chunk samples multiple candidate action chunks, rolls out their predicted latent futures, and selects actions from the chunk whose predicted state best matches the observed rollout. In this way, DREAM-Chunk uses additional test-time computation to cover multiple plausible stochastic futures and improve reactivity during long-horizon chunk execution. On the Kinetix benchmark, DREAM-Chunk improves robustness under increasing action noise and benefits from larger candidate sample sizes, especially when demonstrations contain corrective behaviors. We further validate DREAM-Chunk on four manipulation tasks across two robot platforms and two VLA policies under various sources of stochasticity. Across simulation and hardware experiments, DREAM-Chunk improves the robustness of action-chunking policies in stochastic dynamics.
Efficient Reinforcement Learning using Linear Koopman Dynamics for Nonlinear Robotic Systems
Apr 21, 2026This paper presents a model-based reinforcement learning (RL) framework for optimal closed-loop control of nonlinear robotic systems. The proposed approach learns linear lifted dynamics through Koopman operator theory and integrates the resulting model into an actor-critic architecture for policy optimization, where the policy represents a parameterized closed-loop controller. To reduce computational cost and mitigate model rollout errors, policy gradients are estimated using one-step predictions of the learned dynamics rather than multi-step propagation. This leads to an online mini-batch policy gradient framework that enables policy improvement from streamed interaction data. The proposed framework is evaluated on several simulated nonlinear control benchmarks and two real-world hardware platforms, including a Kinova Gen3 robotic arm and a Unitree Go1 quadruped. Experimental results demonstrate improved sample efficiency over model-free RL baselines, superior control performance relative to model-based RL baselines, and control performance comparable to classical model-based methods that rely on exact system dynamics.
Online Intention Prediction via Control-Informed Learning
Apr 10, 2026This paper presents an online intention prediction framework for estimating the goal state of autonomous systems in real time, even when intention is time-varying, and system dynamics or objectives include unknown parameters. The problem is formulated as an inverse optimal control / inverse reinforcement learning task, with the intention treated as a parameter in the objective. A shifting horizon strategy discounts outdated information, while online control-informed learning enables efficient gradient computation and online parameter updates. Simulations under varying noise levels and hardware experiments on a quadrotor drone demonstrate that the proposed approach achieves accurate, adaptive intention prediction in complex environments.
Accelerating Sampling-Based Control via Learned Linear Koopman Dynamics
Mar 05, 2026This paper presents an efficient model predictive path integral (MPPI) control framework for systems with complex nonlinear dynamics. To improve the computational efficiency of classic MPPI while preserving control performance, we replace the nonlinear dynamics used for trajectory propagation with a learned linear deep Koopman operator (DKO) model, enabling faster rollout and more efficient trajectory sampling. The DKO dynamics are learned directly from interaction data, eliminating the need for analytical system models. The resulting controller, termed MPPI-DK, is evaluated in simulation on pendulum balancing and surface vehicle navigation tasks, and validated on hardware through reference-tracking experiments on a quadruped robot. Experimental results demonstrate that MPPI-DK achieves control performance close to MPPI with true dynamics while substantially reducing computational cost, enabling efficient real-time control on robotic platforms.
Safe Online Control-Informed Learning
Dec 23, 2025This paper proposes a Safe Online Control-Informed Learning framework for safety-critical autonomous systems. The framework unifies optimal control, parameter estimation, and safety constraints into an online learning process. It employs an extended Kalman filter to incrementally update system parameters in real time, enabling robust and data-efficient adaptation under uncertainty. A softplus barrier function enforces constraint satisfaction during learning and control while eliminating the dependence on high-quality initial guesses. Theoretical analysis establishes convergence and safety guarantees, and the framework's effectiveness is demonstrated on cart-pole and robot-arm systems.
Leveraging Perturbation Robustness to Enhance Out-of-Distribution Detection
Mar 24, 2025Out-of-distribution (OOD) detection is the task of identifying inputs that deviate from the training data distribution. This capability is essential for safely deploying deep computer vision models in open-world environments. In this work, we propose a post-hoc method, Perturbation-Rectified OOD detection (PRO), based on the insight that prediction confidence for OOD inputs is more susceptible to reduction under perturbation than in-distribution (IND) inputs. Based on the observation, we propose an adversarial score function that searches for the local minimum scores near the original inputs by applying gradient descent. This procedure enhances the separability between IND and OOD samples. Importantly, the approach improves OOD detection performance without complex modifications to the underlying model architectures. We conduct extensive experiments using the OpenOOD benchmark~\cite{yang2022openood}. Our approach further pushes the limit of softmax-based OOD detection and is the leading post-hoc method for small-scale models. On a CIFAR-10 model with adversarial training, PRO effectively detects near-OOD inputs, achieving a reduction of more than 10\% on FPR@95 compared to state-of-the-art methods.
Reward-Based Collision-Free Algorithm for Trajectory Planning of Autonomous Robots
Feb 10, 2025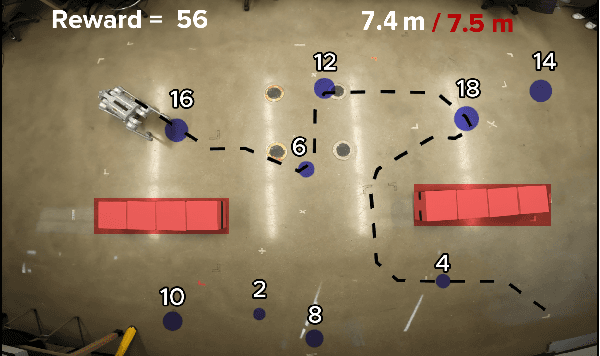
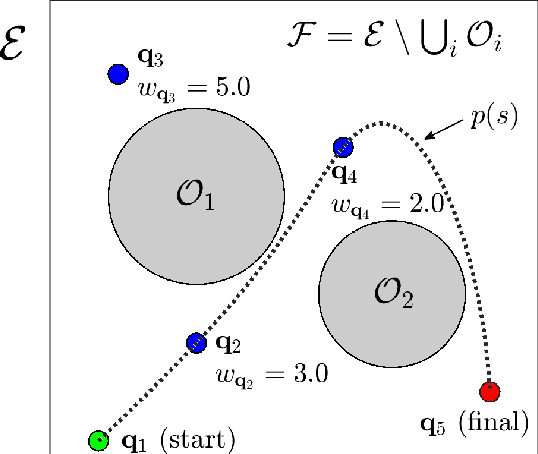
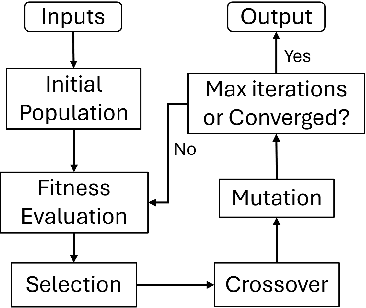
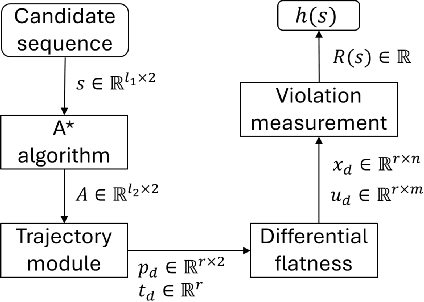
This paper introduces a new mission planning algorithm for autonomous robots that enables the reward-based selection of an optimal waypoint sequence from a predefined set. The algorithm computes a feasible trajectory and corresponding control inputs for a robot to navigate between waypoints while avoiding obstacles, maximizing the total reward, and adhering to constraints on state, input and its derivatives, mission time window, and maximum distance. This also solves a generalized prize-collecting traveling salesman problem. The proposed algorithm employs a new genetic algorithm that evolves solution candidates toward the optimal solution based on a fitness function and crossover. During fitness evaluation, a penalty method enforces constraints, and the differential flatness property with clothoid curves efficiently penalizes infeasible trajectories. The Euler spiral method showed promising results for trajectory parameterization compared to minimum snap and jerk polynomials. Due to the discrete exploration space, crossover is performed using a dynamic time-warping-based method and extended convex combination with projection. A mutation step enhances exploration. Results demonstrate the algorithm's ability to find the optimal waypoint sequence, fulfill constraints, avoid infeasible waypoints, and prioritize high-reward ones. Simulations and experiments with a ground vehicle, quadrotor, and quadruped are presented, complemented by benchmarking and a time-complexity analysis.
Online Control-Informed Learning
Oct 04, 2024This paper proposes an Online Control-Informed Learning (OCIL) framework, which synthesizes the well-established control theories to solve a broad class of learning and control tasks in real time. This novel integration effectively handles practical issues in machine learning such as noisy measurement data, online learning, and data efficiency. By considering any robot as a tunable optimal control system, we propose an online parameter estimator based on extended Kalman filter (EKF) to incrementally tune the system in real time, enabling it to complete designated learning or control tasks. The proposed method also improves robustness in learning by effectively managing noise in the data. Theoretical analysis is provided to demonstrate the convergence and regret of OCIL. Three learning modes of OCIL, i.e. Online Imitation Learning, Online System Identification, and Policy Tuning On-the-fly, are investigated via experiments, which validate their effectiveness.
HOLA-Drone: Hypergraphic Open-ended Learning for Zero-Shot Multi-Drone Cooperative Pursuit
Sep 13, 2024Zero-shot coordination (ZSC) is a significant challenge in multi-agent collaboration, aiming to develop agents that can coordinate with unseen partners they have not encountered before. Recent cutting-edge ZSC methods have primarily focused on two-player video games such as OverCooked!2 and Hanabi. In this paper, we extend the scope of ZSC research to the multi-drone cooperative pursuit scenario, exploring how to construct a drone agent capable of coordinating with multiple unseen partners to capture multiple evaders. We propose a novel Hypergraphic Open-ended Learning Algorithm (HOLA-Drone) that continuously adapts the learning objective based on our hypergraphic-form game modeling, aiming to improve cooperative abilities with multiple unknown drone teammates. To empirically verify the effectiveness of HOLA-Drone, we build two different unseen drone teammate pools to evaluate their performance in coordination with various unseen partners. The experimental results demonstrate that HOLA-Drone outperforms the baseline methods in coordination with unseen drone teammates. Furthermore, real-world experiments validate the feasibility of HOLA-Drone in physical systems. Videos can be found on the project homepage~\url{https://sites.google.com/view/hola-drone}.
C3D: Cascade Control with Change Point Detection and Deep Koopman Learning for Autonomous Surface Vehicles
Mar 14, 2024In this paper, we discuss the development and deployment of a robust autonomous system capable of performing various tasks in the maritime domain under unknown dynamic conditions. We investigate a data-driven approach based on modular design for ease of transfer of autonomy across different maritime surface vessel platforms. The data-driven approach alleviates issues related to a priori identification of system models that may become deficient under evolving system behaviors or shifting, unanticipated, environmental influences. Our proposed learning-based platform comprises a deep Koopman system model and a change point detector that provides guidance on domain shifts prompting relearning under severe exogenous and endogenous perturbations. Motion control of the autonomous system is achieved via an optimal controller design. The Koopman linearized model naturally lends itself to a linear-quadratic regulator (LQR) control design. We propose the C3D control architecture Cascade Control with Change Point Detection and Deep Koopman Learning. The framework is verified in station keeping task on an ASV in both simulation and real experiments. The approach achieved at least 13.9 percent improvement in mean distance error in all test cases compared to the methods that do not consider system changes.