 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Optimization via Kernelized Multi-armed Bandits
Dec 07, 2023Multi-armed bandit algorithms provide solutions for sequential decision-making where learning takes place by interacting with the environment. In this work, we model a distributed optimization problem as a multi-agent kernelized multi-armed bandit problem with a heterogeneous reward setting. In this setup, the agents collaboratively aim to maximize a global objective function which is an average of local objective functions. The agents can access only bandit feedback (noisy reward) obtained from the associated unknown local function with a small norm in reproducing kernel Hilbert space (RKHS). We present a fully decentralized algorithm, Multi-agent IGP-UCB (MA-IGP-UCB), which achieves a sub-linear regret bound for popular classes for kernels while preserving privacy. It does not necessitate the agents to share their actions, rewards, or estimates of their local function. In the proposed approach, the agents sample their individual local functions in a way that benefits the whole network by utilizing a running consensus to estimate the upper confidence bound on the global function. Furthermore, we propose an extension, Multi-agent Delayed IGP-UCB (MAD-IGP-UCB) algorithm, which reduces the dependence of the regret bound on the number of agents in the network. It provides improved performance by utilizing a delay in the estimation update step at the cost of more communication.
Neighboring Extremal Optimal Control Theory for Parameter-Dependent Closed-loop Laws
Dec 07, 2023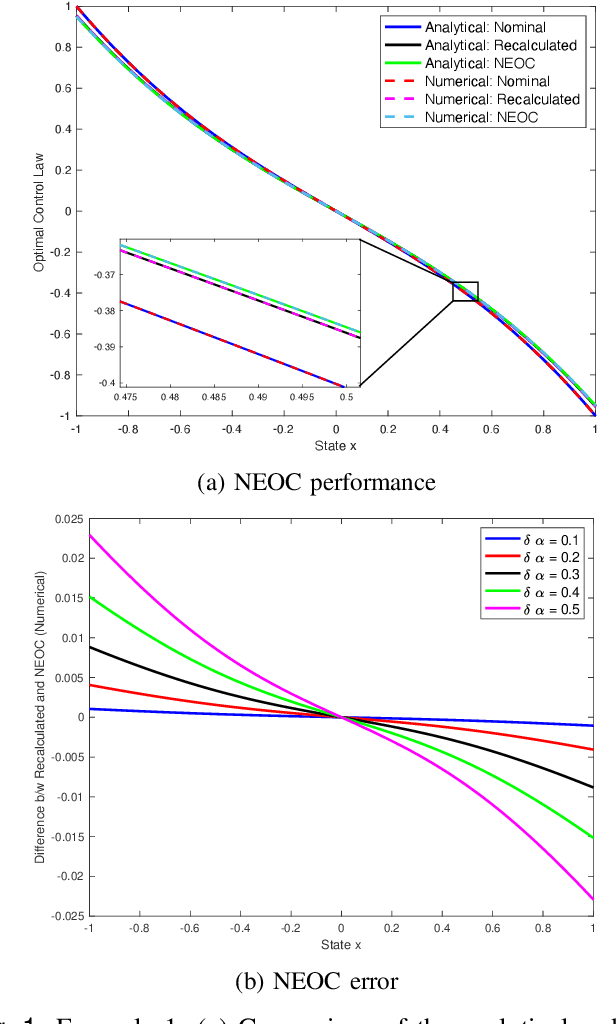
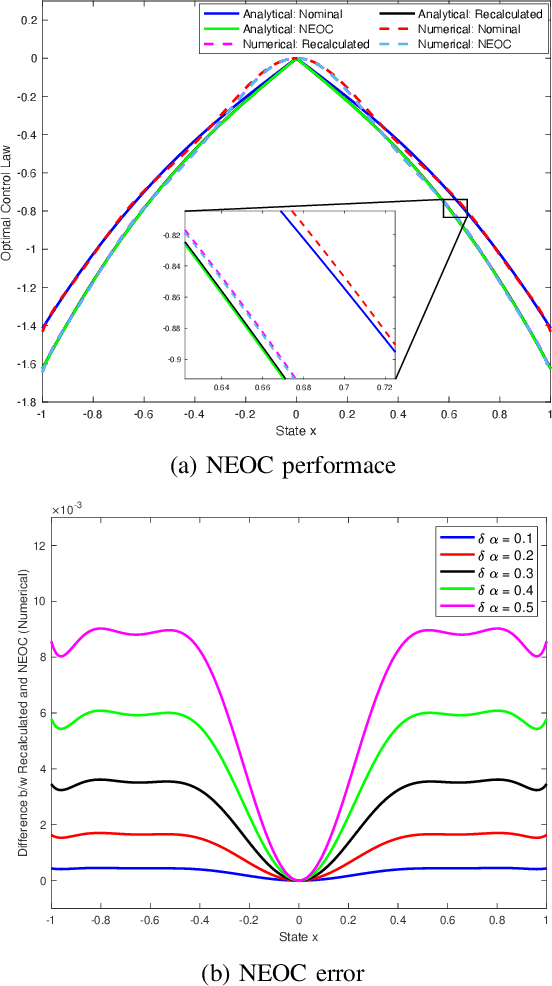
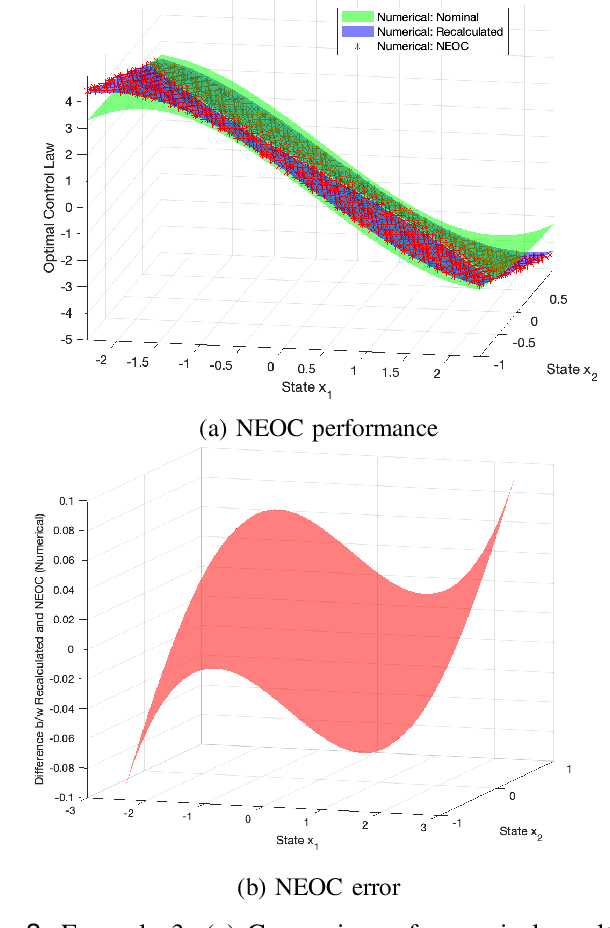
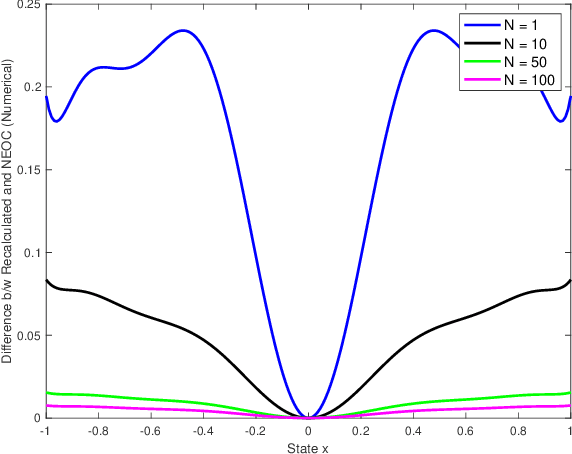
This study introduces an approach to obtain a neighboring extremal optimal control (NEOC) solution for a closed-loop optimal control problem, applicable to a wide array of nonlinear systems and not necessarily quadratic performance indices. The approach involves investigating the variation incurred in the functional form of a known closed-loop optimal control law due to small, known parameter variations in the system equations or the performance index. The NEOC solution can formally be obtained by solving a linear partial differential equation, akin to those encountered in the iterative solution of a nonlinear Hamilton-Jacobi equation. Motivated by numerical procedures for solving these latter equations, we also propose a numerical algorithm based on the Galerkin algorithm, leveraging the use of basis functions to solve the underlying Hamilton-Jacobi equation of the original optimal control problem. The proposed approach simplifies the NEOC problem by reducing it to the solution of a simple set of linear equations, thereby eliminating the need for a full re-solution of the adjusted optimal control problem. Furthermore, the variation to the optimal performance index can be obtained as a function of both the system state and small changes in parameters, allowing the determination of the adjustment to an optimal control law given a small adjustment of parameters in the system or the performance index. Moreover, in order to handle large known parameter perturbations, we propose a homotopic approach that breaks down the single calculation of NEOC into a finite set of multiple steps. Finally, the validity of the claims and theory is supported by theoretical analysis and numerical simulations.