 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Online Control-Informed Learning
Dec 23, 2025This paper proposes a Safe Online Control-Informed Learning framework for safety-critical autonomous systems. The framework unifies optimal control, parameter estimation, and safety constraints into an online learning process. It employs an extended Kalman filter to incrementally update system parameters in real time, enabling robust and data-efficient adaptation under uncertainty. A softplus barrier function enforces constraint satisfaction during learning and control while eliminating the dependence on high-quality initial guesses. Theoretical analysis establishes convergence and safety guarantees, and the framework's effectiveness is demonstrated on cart-pole and robot-arm systems.
Online Control-Informed Learning
Oct 04, 2024This paper proposes an Online Control-Informed Learning (OCIL) framework, which synthesizes the well-established control theories to solve a broad class of learning and control tasks in real time. This novel integration effectively handles practical issues in machine learning such as noisy measurement data, online learning, and data efficiency. By considering any robot as a tunable optimal control system, we propose an online parameter estimator based on extended Kalman filter (EKF) to incrementally tune the system in real time, enabling it to complete designated learning or control tasks. The proposed method also improves robustness in learning by effectively managing noise in the data. Theoretical analysis is provided to demonstrate the convergence and regret of OCIL. Three learning modes of OCIL, i.e. Online Imitation Learning, Online System Identification, and Policy Tuning On-the-fly, are investigated via experiments, which validate their effectiveness.
Adaptive Policy Learning to Additional Tasks
May 24, 2023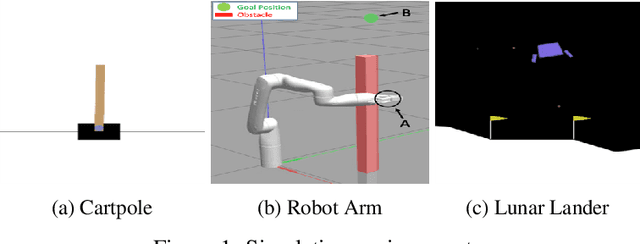
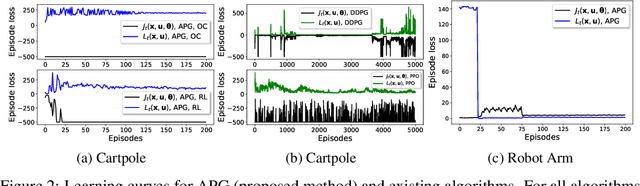
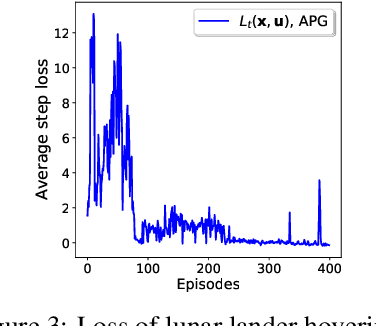
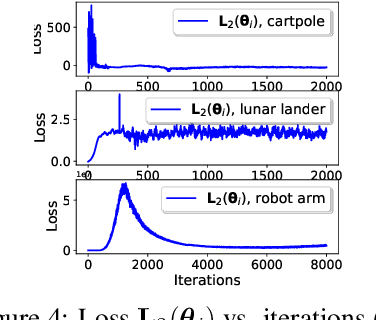
This paper develops a policy learning method for tuning a pre-trained policy to adapt to additional tasks without altering the original task. A method named Adaptive Policy Gradient (APG) is proposed in this paper, which combines Bellman's principle of optimality with the policy gradient approach to improve the convergence rate. This paper provides theoretical analysis which guarantees the convergence rate and sample complexity of $\mathcal{O}(1/T)$ and $\mathcal{O}(1/\epsilon)$, respectively, where $T$ denotes the number of iterations and $\epsilon$ denotes the accuracy of the resulting stationary policy. Furthermore, several challenging numerical simulations, including cartpole, lunar lander, and robot arm, are provided to show that APG obtains similar performance compared to existing deterministic policy gradient methods while utilizing much less data and converging at a faster rate.
Policy Learning based on Deep Koopman Representation
May 24, 2023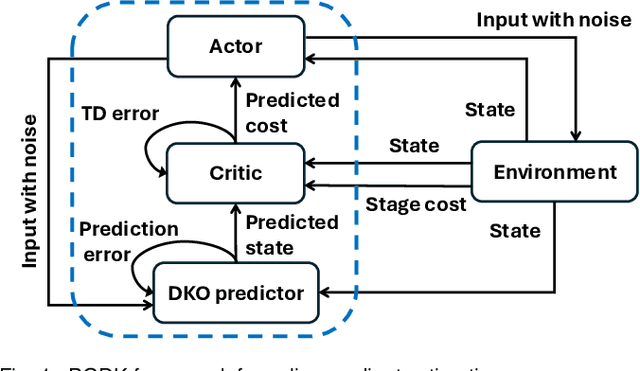
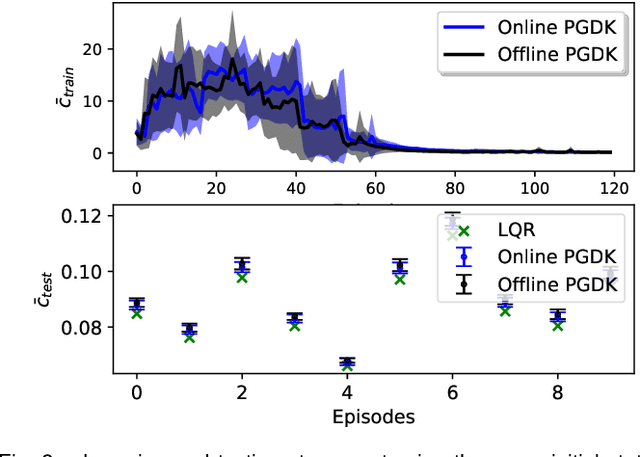
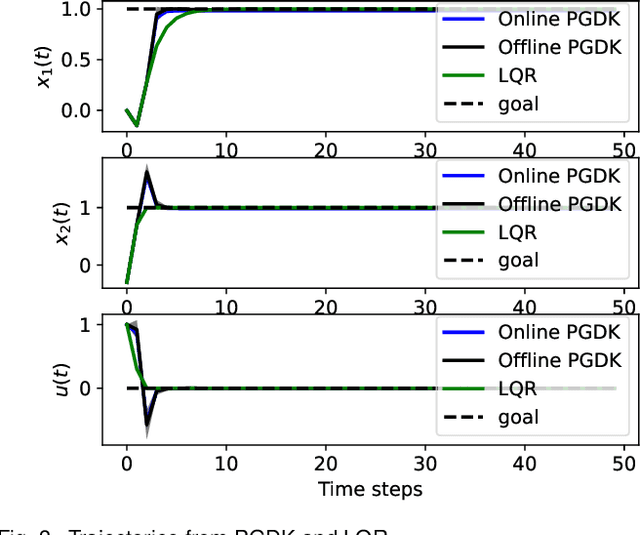
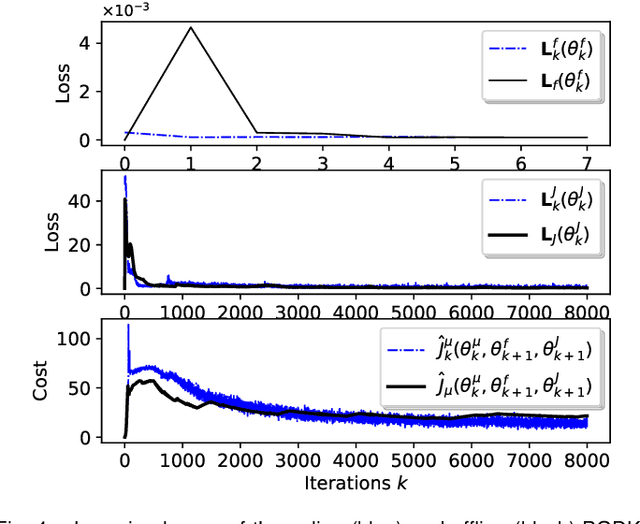
This paper proposes a policy learning algorithm based on the Koopman operator theory and policy gradient approach, which seeks to approximate an unknown dynamical system and search for optimal policy simultaneously, using the observations gathered through interaction with the environment. The proposed algorithm has two innovations: first, it introduces the so-called deep Koopman representation into the policy gradient to achieve a linear approximation of the unknown dynamical system, all with the purpose of improving data efficiency; second, the accumulated errors for long-term tasks induced by approximating system dynamics are avoided by applying Bellman's principle of optimality. Furthermore, a theoretical analysis is provided to prove the asymptotic convergence of the proposed algorithm and characterize the corresponding sampling complexity. These conclusions are also supported by simulations on several challenging benchmark environments.
GPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Aug 04, 2022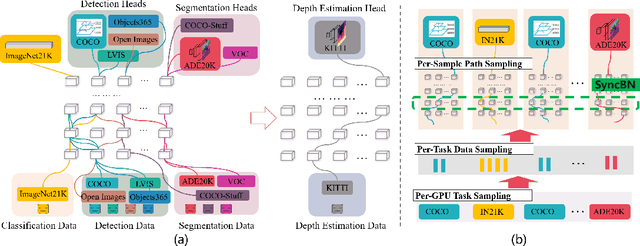
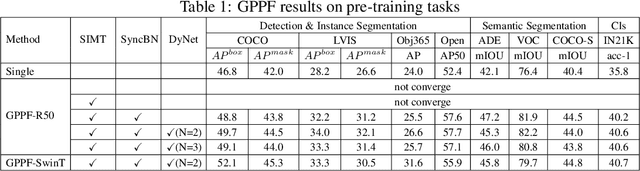
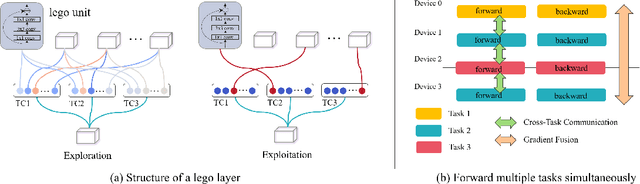
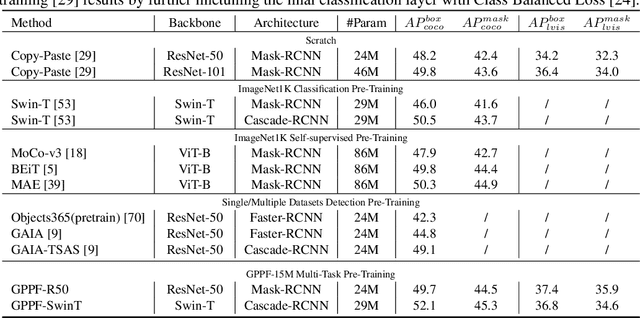
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.
Inverse Optimal Control from Demonstration Segments
Oct 28, 2020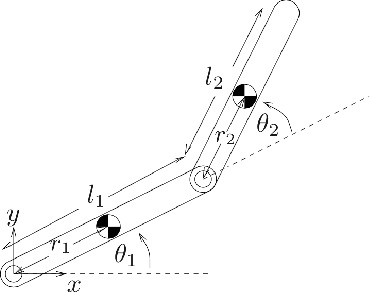
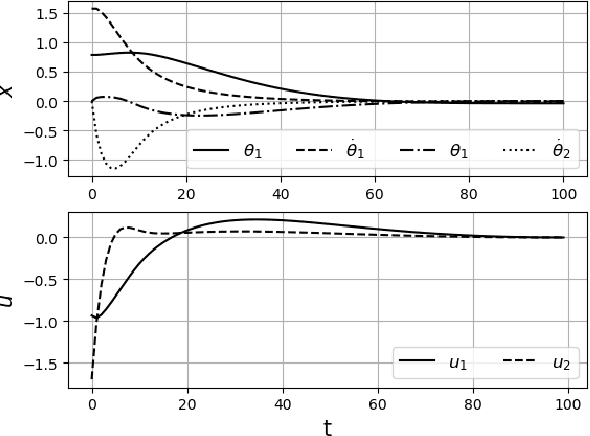
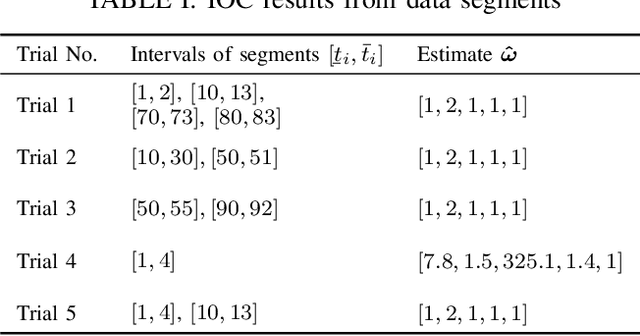
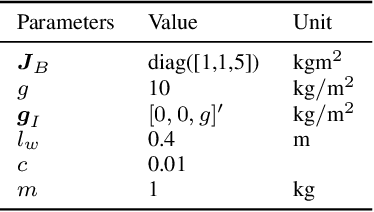
This paper develops an inverse optimal control method to learn an objective function from segments of demonstrations. Here, each segment is part of an optimal trajectory within any time interval of the horizon. The unknown objective function is parameterized as a weighted sum of given features with unknown weights. The proposed method shows that each trajectory segment can be transformed into a linear constraint to the unknown weights, and then all available segments are incrementally incorporated to solve for the unknown weights. Effectiveness of the proposed method is shown on a simulated 2-link robot arm and a 6-DoF maneuvering quadrotor system, in each of which only segment data of the systems' trajectories are available.