 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Online Control-Informed Learning
Dec 23, 2025This paper proposes a Safe Online Control-Informed Learning framework for safety-critical autonomous systems. The framework unifies optimal control, parameter estimation, and safety constraints into an online learning process. It employs an extended Kalman filter to incrementally update system parameters in real time, enabling robust and data-efficient adaptation under uncertainty. A softplus barrier function enforces constraint satisfaction during learning and control while eliminating the dependence on high-quality initial guesses. Theoretical analysis establishes convergence and safety guarantees, and the framework's effectiveness is demonstrated on cart-pole and robot-arm systems.
LDP: Parameter-Efficient Fine-Tuning of Multimodal LLM for Medical Report Generation
Dec 11, 2025Colonoscopic polyp diagnosis is pivotal for early colorectal cancer detection, yet traditional automated reporting suffers from inconsistencies and hallucinations due to the scarcity of high-quality multimodal medical data. To bridge this gap, we propose LDP, a novel framework leveraging multimodal large language models (MLLMs) for professional polyp diagnosis report generation. Specifically, we curate MMEndo, a multimodal endoscopic dataset comprising expert-annotated colonoscopy image-text pairs. We fine-tune the Qwen2-VL-7B backbone using Parameter-Efficient Fine-Tuning (LoRA) and align it with clinical standards via Direct Preference Optimization (DPO). Extensive experiments show that our LDP outperforms existing baselines on both automated metrics and rigorous clinical expert evaluations (achieving a Physician Score of 7.2/10), significantly reducing training computational costs by 833x compared to full fine-tuning. The proposed solution offers a scalable, clinically viable path for primary healthcare, with additional validation on the IU-XRay dataset confirming its robustness.
DEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025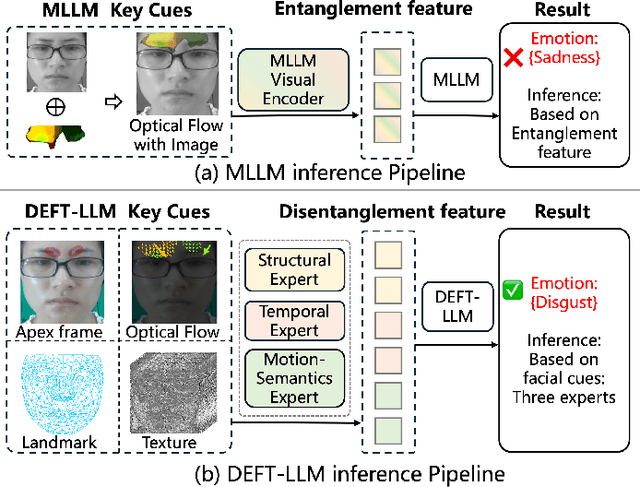
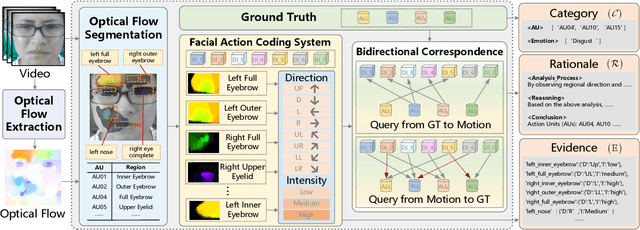
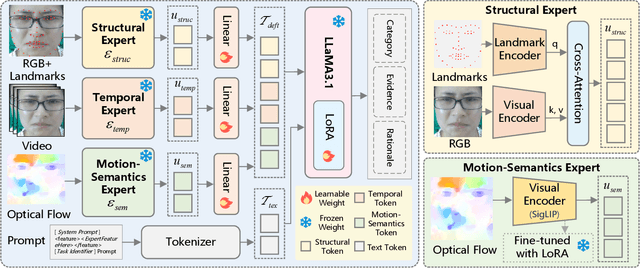
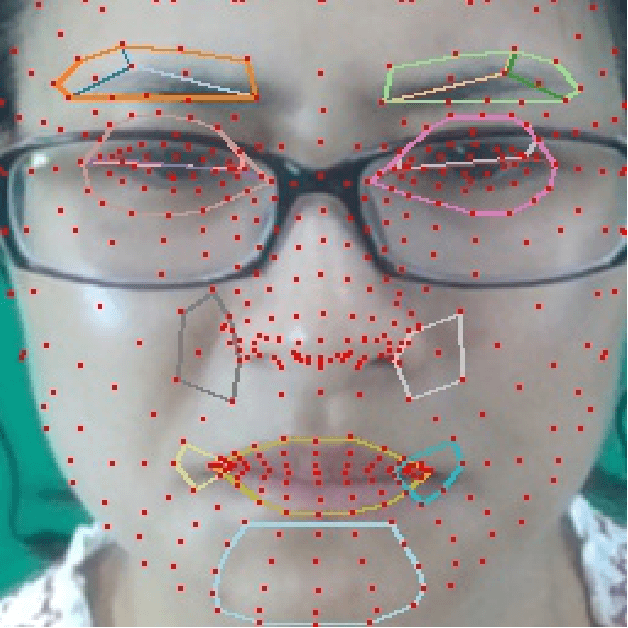
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Reward-Based Collision-Free Algorithm for Trajectory Planning of Autonomous Robots
Feb 10, 2025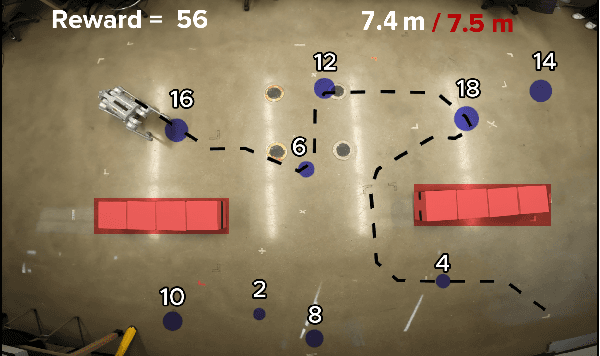
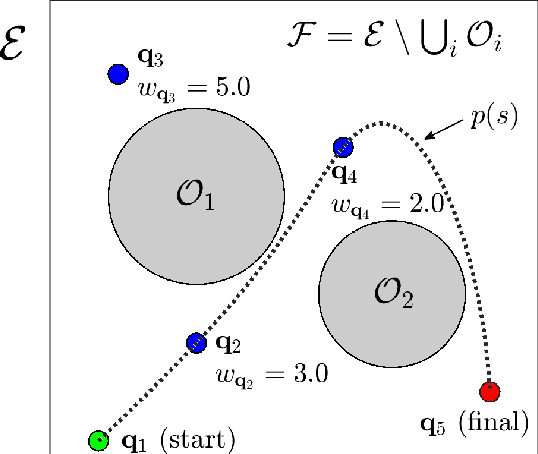
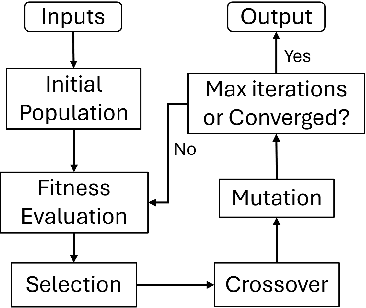
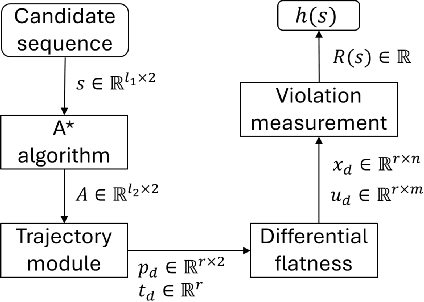
This paper introduces a new mission planning algorithm for autonomous robots that enables the reward-based selection of an optimal waypoint sequence from a predefined set. The algorithm computes a feasible trajectory and corresponding control inputs for a robot to navigate between waypoints while avoiding obstacles, maximizing the total reward, and adhering to constraints on state, input and its derivatives, mission time window, and maximum distance. This also solves a generalized prize-collecting traveling salesman problem. The proposed algorithm employs a new genetic algorithm that evolves solution candidates toward the optimal solution based on a fitness function and crossover. During fitness evaluation, a penalty method enforces constraints, and the differential flatness property with clothoid curves efficiently penalizes infeasible trajectories. The Euler spiral method showed promising results for trajectory parameterization compared to minimum snap and jerk polynomials. Due to the discrete exploration space, crossover is performed using a dynamic time-warping-based method and extended convex combination with projection. A mutation step enhances exploration. Results demonstrate the algorithm's ability to find the optimal waypoint sequence, fulfill constraints, avoid infeasible waypoints, and prioritize high-reward ones. Simulations and experiments with a ground vehicle, quadrotor, and quadruped are presented, complemented by benchmarking and a time-complexity analysis.
Force-Based Robotic Imitation Learning: A Two-Phase Approach for Construction Assembly Tasks
Jan 24, 2025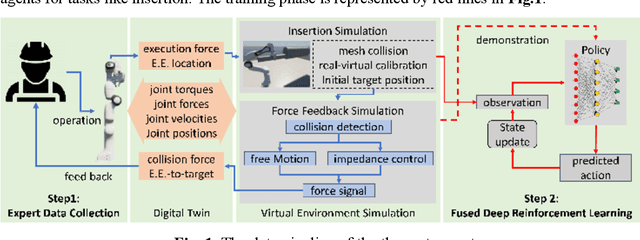
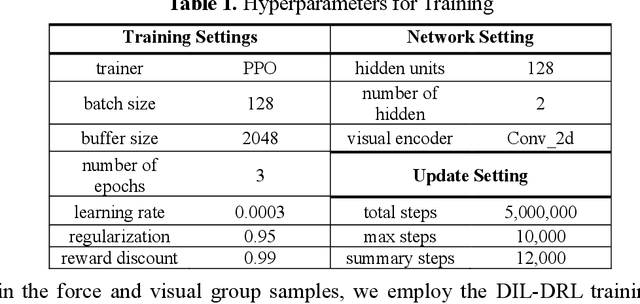
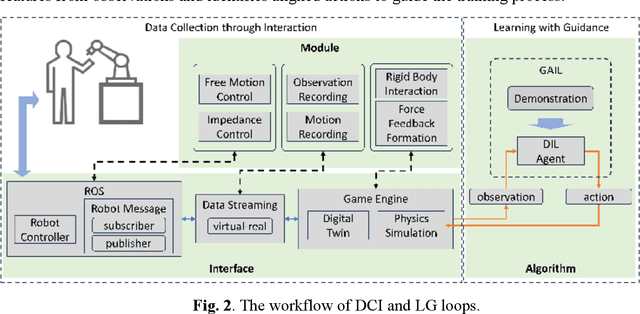

The drive for efficiency and safety in construction has boosted the role of robotics and automation. However, complex tasks like welding and pipe insertion pose challenges due to their need for precise adaptive force control, which complicates robotic training. This paper proposes a two-phase system to improve robot learning, integrating human-derived force feedback. The first phase captures real-time data from operators using a robot arm linked with a virtual simulator via ROS-Sharp. In the second phase, this feedback is converted into robotic motion instructions, using a generative approach to incorporate force feedback into the learning process. This method's effectiveness is demonstrated through improved task completion times and success rates. The framework simulates realistic force-based interactions, enhancing the training data's quality for precise robotic manipulation in construction tasks.
Temporal Binding Foundation Model for Material Property Recognition via Tactile Sequence Perception
Jan 24, 2025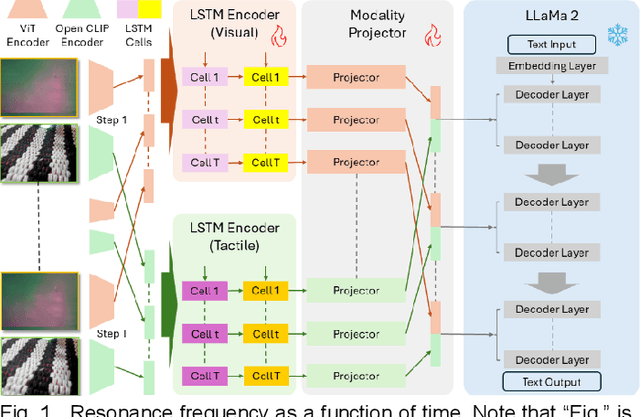

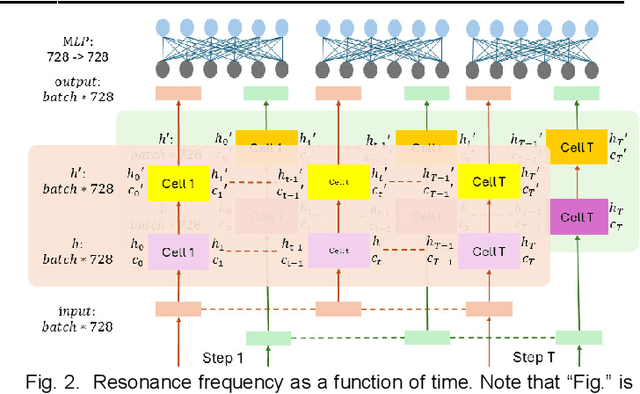
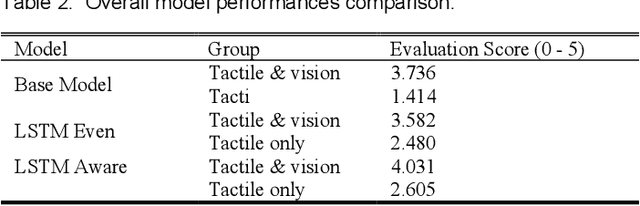
Robots engaged in complex manipulation tasks require robust material property recognition to ensure adaptability and precision. Traditionally, visual data has been the primary source for object perception; however, it often proves insufficient in scenarios where visibility is obstructed or detailed observation is needed. This gap highlights the necessity of tactile sensing as a complementary or primary input for material recognition. Tactile data becomes particularly essential in contact-rich, small-scale manipulations where subtle deformations and surface interactions cannot be accurately captured by vision alone. This letter presents a novel approach leveraging a temporal binding foundation model for tactile sequence understanding to enhance material property recognition. By processing tactile sensor data with a temporal focus, the proposed system captures the sequential nature of tactile interactions, similar to human fingertip perception. Additionally, this letter demonstrates that, through tailored and specific design, the foundation model can more effectively capture temporal information embedded in tactile sequences, advancing material property understanding. Experimental results validate the model's capability to capture these temporal patterns, confirming its utility for material property recognition in visually restricted scenarios. This work underscores the necessity of embedding advanced tactile data processing frameworks within robotic systems to achieve truly embodied and responsive manipulation capabilities.
FinRobot: AI Agent for Equity Research and Valuation with Large Language Models
Nov 13, 2024



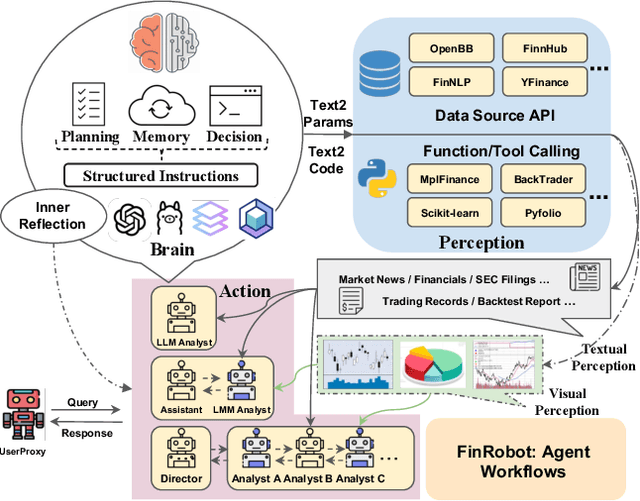
As financial markets grow increasingly complex, there is a rising need for automated tools that can effectively assist human analysts in equity research, particularly within sell-side research. While Generative AI (GenAI) has attracted significant attention in this field, existing AI solutions often fall short due to their narrow focus on technical factors and limited capacity for discretionary judgment. These limitations hinder their ability to adapt to new data in real-time and accurately assess risks, which diminishes their practical value for investors. This paper presents FinRobot, the first AI agent framework specifically designed for equity research. FinRobot employs a multi-agent Chain of Thought (CoT) system, integrating both quantitative and qualitative analyses to emulate the comprehensive reasoning of a human analyst. The system is structured around three specialized agents: the Data-CoT Agent, which aggregates diverse data sources for robust financial integration; the Concept-CoT Agent, which mimics an analysts reasoning to generate actionable insights; and the Thesis-CoT Agent, which synthesizes these insights into a coherent investment thesis and report. FinRobot provides thorough company analysis supported by precise numerical data, industry-appropriate valuation metrics, and realistic risk assessments. Its dynamically updatable data pipeline ensures that research remains timely and relevant, adapting seamlessly to new financial information. Unlike existing automated research tools, such as CapitalCube and Wright Reports, FinRobot delivers insights comparable to those produced by major brokerage firms and fundamental research vendors. We open-source FinRobot at \url{https://github. com/AI4Finance-Foundation/FinRobot}.
Online Control-Informed Learning
Oct 04, 2024This paper proposes an Online Control-Informed Learning (OCIL) framework, which synthesizes the well-established control theories to solve a broad class of learning and control tasks in real time. This novel integration effectively handles practical issues in machine learning such as noisy measurement data, online learning, and data efficiency. By considering any robot as a tunable optimal control system, we propose an online parameter estimator based on extended Kalman filter (EKF) to incrementally tune the system in real time, enabling it to complete designated learning or control tasks. The proposed method also improves robustness in learning by effectively managing noise in the data. Theoretical analysis is provided to demonstrate the convergence and regret of OCIL. Three learning modes of OCIL, i.e. Online Imitation Learning, Online System Identification, and Policy Tuning On-the-fly, are investigated via experiments, which validate their effectiveness.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024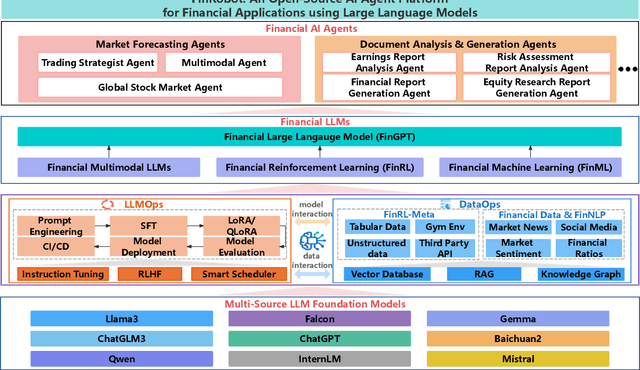
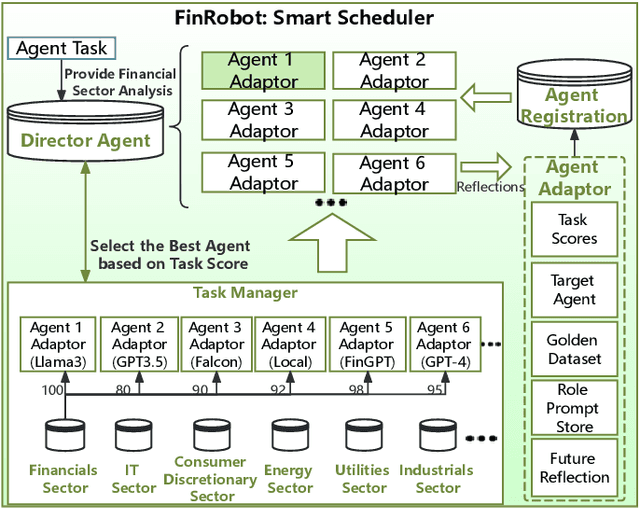

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.