 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Sampling-Based Control via Learned Linear Koopman Dynamics
Mar 05, 2026This paper presents an efficient model predictive path integral (MPPI) control framework for systems with complex nonlinear dynamics. To improve the computational efficiency of classic MPPI while preserving control performance, we replace the nonlinear dynamics used for trajectory propagation with a learned linear deep Koopman operator (DKO) model, enabling faster rollout and more efficient trajectory sampling. The DKO dynamics are learned directly from interaction data, eliminating the need for analytical system models. The resulting controller, termed MPPI-DK, is evaluated in simulation on pendulum balancing and surface vehicle navigation tasks, and validated on hardware through reference-tracking experiments on a quadruped robot. Experimental results demonstrate that MPPI-DK achieves control performance close to MPPI with true dynamics while substantially reducing computational cost, enabling efficient real-time control on robotic platforms.
Safe Online Control-Informed Learning
Dec 23, 2025This paper proposes a Safe Online Control-Informed Learning framework for safety-critical autonomous systems. The framework unifies optimal control, parameter estimation, and safety constraints into an online learning process. It employs an extended Kalman filter to incrementally update system parameters in real time, enabling robust and data-efficient adaptation under uncertainty. A softplus barrier function enforces constraint satisfaction during learning and control while eliminating the dependence on high-quality initial guesses. Theoretical analysis establishes convergence and safety guarantees, and the framework's effectiveness is demonstrated on cart-pole and robot-arm systems.
Reward-Based Collision-Free Algorithm for Trajectory Planning of Autonomous Robots
Feb 10, 2025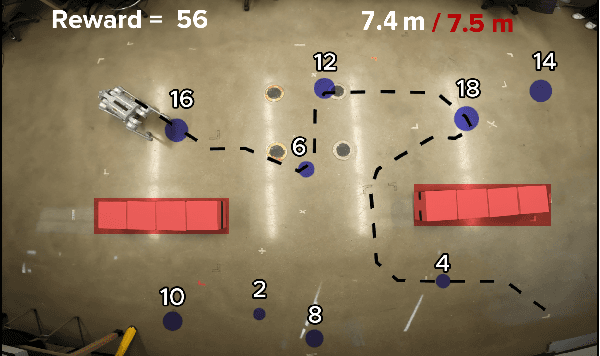
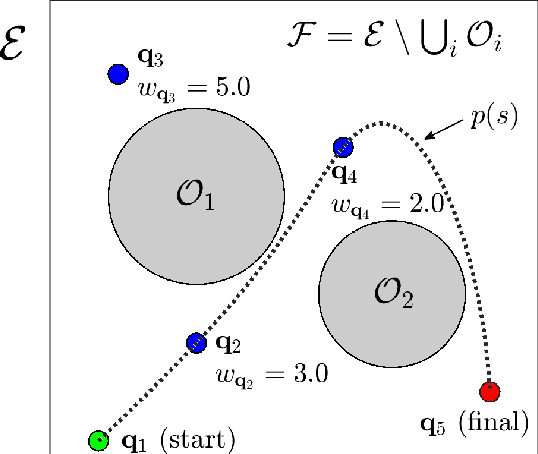
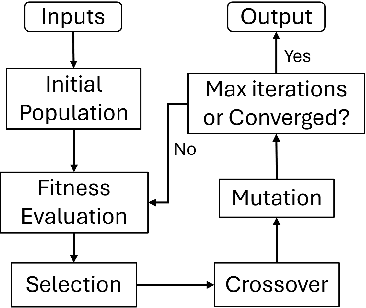
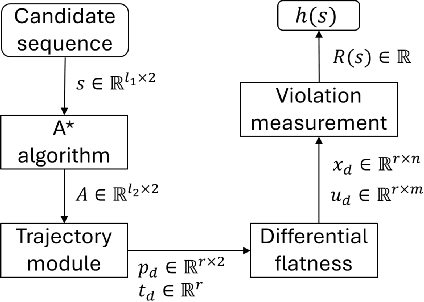
This paper introduces a new mission planning algorithm for autonomous robots that enables the reward-based selection of an optimal waypoint sequence from a predefined set. The algorithm computes a feasible trajectory and corresponding control inputs for a robot to navigate between waypoints while avoiding obstacles, maximizing the total reward, and adhering to constraints on state, input and its derivatives, mission time window, and maximum distance. This also solves a generalized prize-collecting traveling salesman problem. The proposed algorithm employs a new genetic algorithm that evolves solution candidates toward the optimal solution based on a fitness function and crossover. During fitness evaluation, a penalty method enforces constraints, and the differential flatness property with clothoid curves efficiently penalizes infeasible trajectories. The Euler spiral method showed promising results for trajectory parameterization compared to minimum snap and jerk polynomials. Due to the discrete exploration space, crossover is performed using a dynamic time-warping-based method and extended convex combination with projection. A mutation step enhances exploration. Results demonstrate the algorithm's ability to find the optimal waypoint sequence, fulfill constraints, avoid infeasible waypoints, and prioritize high-reward ones. Simulations and experiments with a ground vehicle, quadrotor, and quadruped are presented, complemented by benchmarking and a time-complexity analysis.
Online Control-Informed Learning
Oct 04, 2024This paper proposes an Online Control-Informed Learning (OCIL) framework, which synthesizes the well-established control theories to solve a broad class of learning and control tasks in real time. This novel integration effectively handles practical issues in machine learning such as noisy measurement data, online learning, and data efficiency. By considering any robot as a tunable optimal control system, we propose an online parameter estimator based on extended Kalman filter (EKF) to incrementally tune the system in real time, enabling it to complete designated learning or control tasks. The proposed method also improves robustness in learning by effectively managing noise in the data. Theoretical analysis is provided to demonstrate the convergence and regret of OCIL. Three learning modes of OCIL, i.e. Online Imitation Learning, Online System Identification, and Policy Tuning On-the-fly, are investigated via experiments, which validate their effectiveness.
A Differentiable Dynamic Modeling Approach to Integrated Motion Planning and Actuator Physical Design for Mobile Manipulators
May 01, 2024This paper investigates the differentiable dynamic modeling of mobile manipulators to facilitate efficient motion planning and physical design of actuators, where the actuator design is parameterized by physically meaningful motor geometry parameters. These parameters impact the manipulator's link mass, inertia, center-of-mass, torque constraints, and angular velocity constraints, influencing control authority in motion planning and trajectory tracking control. A motor's maximum torque/speed and how the design parameters affect the dynamics are modeled analytically, facilitating differentiable and analytical dynamic modeling. Additionally, an integrated locomotion and manipulation planning problem is formulated with direct collocation discretization, using the proposed differentiable dynamics and motor parameterization. Such dynamics are required to capture the dynamic coupling between the base and the manipulator. Numerical experiments demonstrate the effectiveness of differentiable dynamics in speeding up optimization and advantages in task completion time and energy consumption over established sequential motion planning approach. Finally, this paper introduces a simultaneous actuator design and motion planning framework, providing numerical results to validate the proposed differentiable modeling approach for co-design problems.
Adaptive Policy Learning to Additional Tasks
May 24, 2023
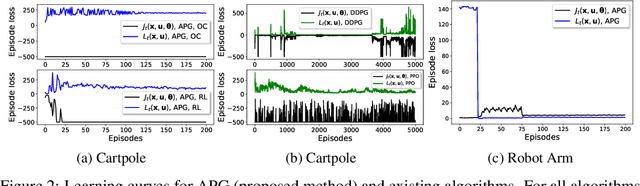
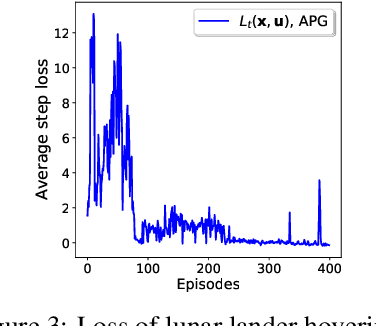
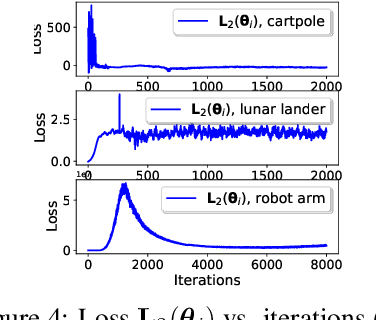
This paper develops a policy learning method for tuning a pre-trained policy to adapt to additional tasks without altering the original task. A method named Adaptive Policy Gradient (APG) is proposed in this paper, which combines Bellman's principle of optimality with the policy gradient approach to improve the convergence rate. This paper provides theoretical analysis which guarantees the convergence rate and sample complexity of $\mathcal{O}(1/T)$ and $\mathcal{O}(1/\epsilon)$, respectively, where $T$ denotes the number of iterations and $\epsilon$ denotes the accuracy of the resulting stationary policy. Furthermore, several challenging numerical simulations, including cartpole, lunar lander, and robot arm, are provided to show that APG obtains similar performance compared to existing deterministic policy gradient methods while utilizing much less data and converging at a faster rate.
Policy Learning based on Deep Koopman Representation
May 24, 2023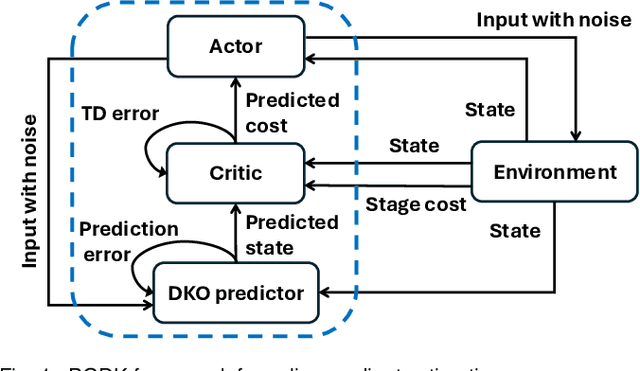
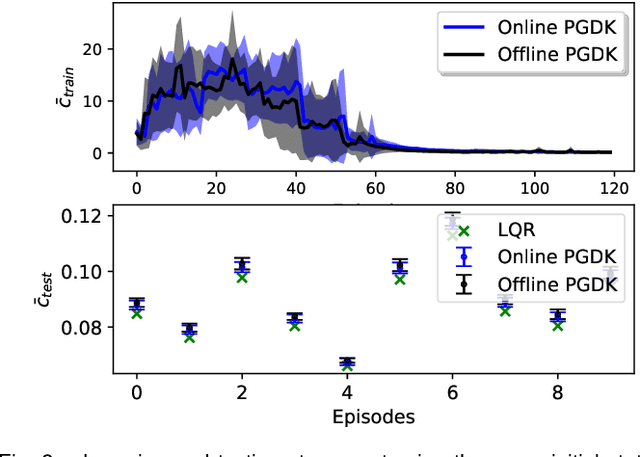
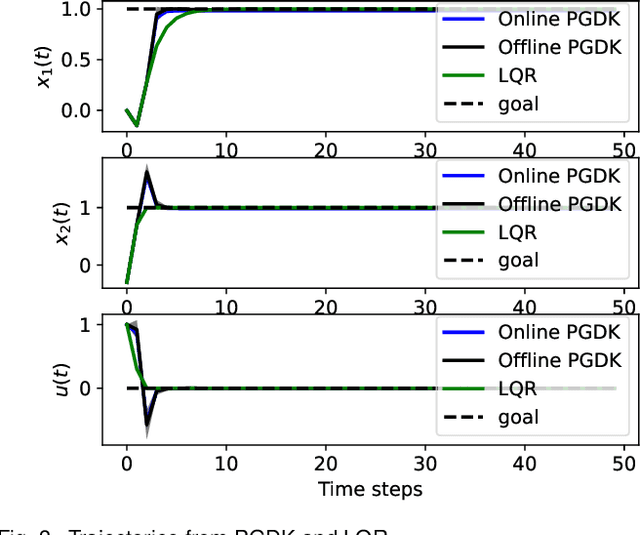
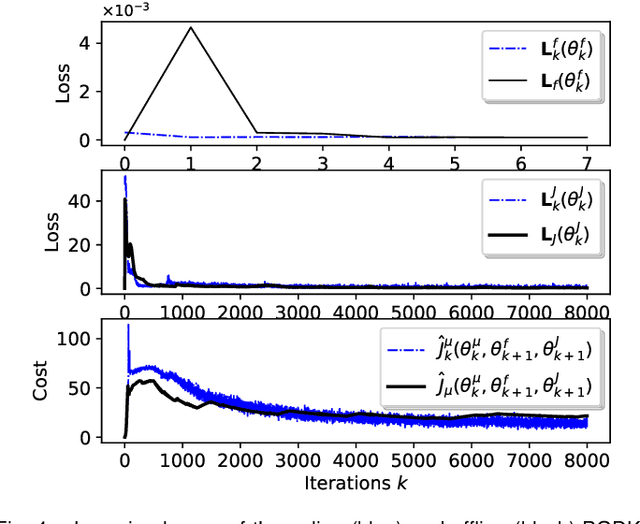
This paper proposes a policy learning algorithm based on the Koopman operator theory and policy gradient approach, which seeks to approximate an unknown dynamical system and search for optimal policy simultaneously, using the observations gathered through interaction with the environment. The proposed algorithm has two innovations: first, it introduces the so-called deep Koopman representation into the policy gradient to achieve a linear approximation of the unknown dynamical system, all with the purpose of improving data efficiency; second, the accumulated errors for long-term tasks induced by approximating system dynamics are avoided by applying Bellman's principle of optimality. Furthermore, a theoretical analysis is provided to prove the asymptotic convergence of the proposed algorithm and characterize the corresponding sampling complexity. These conclusions are also supported by simulations on several challenging benchmark environments.
DrMaMP: Distributed Real-time Multi-agent Mission Planning in Cluttered Environment
Feb 28, 2023Solving a collision-aware multi-agent mission planning (task allocation and path finding) problem is challenging due to the requirement of real-time computational performance, scalability, and capability of handling static/dynamic obstacles and tasks in a cluttered environment. This paper proposes a distributed real-time (on the order of millisecond) algorithm DrMaMP, which partitions the entire unassigned task set into subsets via approximation and decomposes the original problem into several single-agent mission planning problems. This paper presents experiments with dynamic obstacles and tasks and conducts optimality and scalability comparisons with an existing method, where DrMaMP outperforms the existing method in both indices. Finally, this paper analyzes the computational burden of DrMaMP which is consistent with the observations from comparisons, and presents the optimality gap in small-size problems.