 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy
Nov 15, 2025


Stock trading strategies play a critical role in investment. However, it is challenging to design a profitable strategy in a complex and dynamic stock market. In this paper, we propose an ensemble strategy that employs deep reinforcement schemes to learn a stock trading strategy by maximizing investment return. We train a deep reinforcement learning agent and obtain an ensemble trading strategy using three actor-critic based algorithms: Proximal Policy Optimization (PPO), Advantage Actor Critic (A2C), and Deep Deterministic Policy Gradient (DDPG). The ensemble strategy inherits and integrates the best features of the three algorithms, thereby robustly adjusting to different market situations. In order to avoid the large memory consumption in training networks with continuous action space, we employ a load-on-demand technique for processing very large data. We test our algorithms on the 30 Dow Jones stocks that have adequate liquidity. The performance of the trading agent with different reinforcement learning algorithms is evaluated and compared with both the Dow Jones Industrial Average index and the traditional min-variance portfolio allocation strategy. The proposed deep ensemble strategy is shown to outperform the three individual algorithms and two baselines in terms of the risk-adjusted return measured by the Sharpe ratio. This work is fully open-sourced at \href{https://github.com/AI4Finance-Foundation/Deep-Reinforcement-Learning-for-Automated-Stock-Trading-Ensemble-Strategy-ICAIF-2020}{GitHub}.
FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
Dec 14, 2024



Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs' ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8\% compared to existing methods.
FinRobot: AI Agent for Equity Research and Valuation with Large Language Models
Nov 13, 2024



As financial markets grow increasingly complex, there is a rising need for automated tools that can effectively assist human analysts in equity research, particularly within sell-side research. While Generative AI (GenAI) has attracted significant attention in this field, existing AI solutions often fall short due to their narrow focus on technical factors and limited capacity for discretionary judgment. These limitations hinder their ability to adapt to new data in real-time and accurately assess risks, which diminishes their practical value for investors. This paper presents FinRobot, the first AI agent framework specifically designed for equity research. FinRobot employs a multi-agent Chain of Thought (CoT) system, integrating both quantitative and qualitative analyses to emulate the comprehensive reasoning of a human analyst. The system is structured around three specialized agents: the Data-CoT Agent, which aggregates diverse data sources for robust financial integration; the Concept-CoT Agent, which mimics an analysts reasoning to generate actionable insights; and the Thesis-CoT Agent, which synthesizes these insights into a coherent investment thesis and report. FinRobot provides thorough company analysis supported by precise numerical data, industry-appropriate valuation metrics, and realistic risk assessments. Its dynamically updatable data pipeline ensures that research remains timely and relevant, adapting seamlessly to new financial information. Unlike existing automated research tools, such as CapitalCube and Wright Reports, FinRobot delivers insights comparable to those produced by major brokerage firms and fundamental research vendors. We open-source FinRobot at \url{https://github. com/AI4Finance-Foundation/FinRobot}.
Enhancing Investment Analysis: Optimizing AI-Agent Collaboration in Financial Research
Nov 07, 2024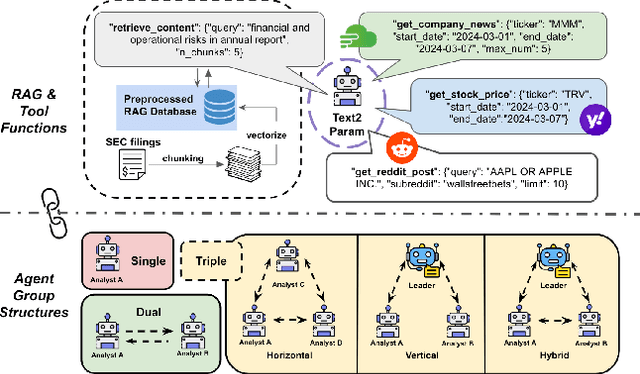
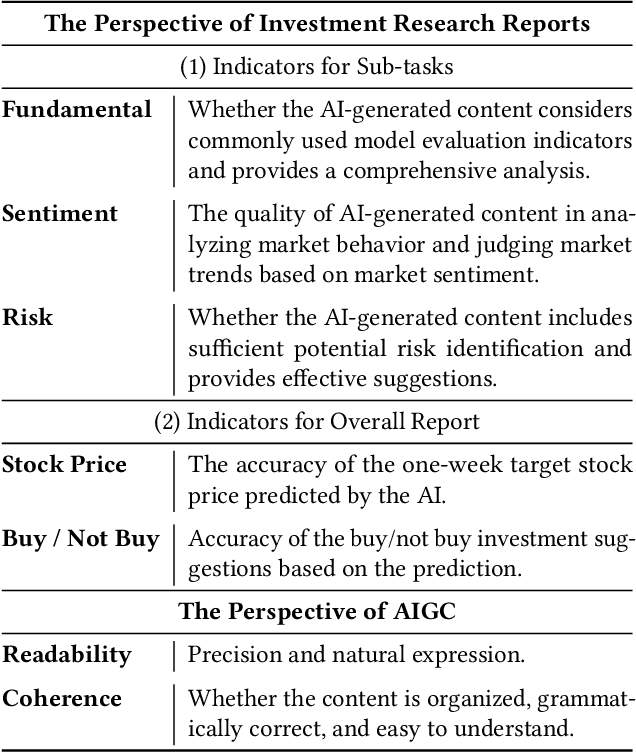
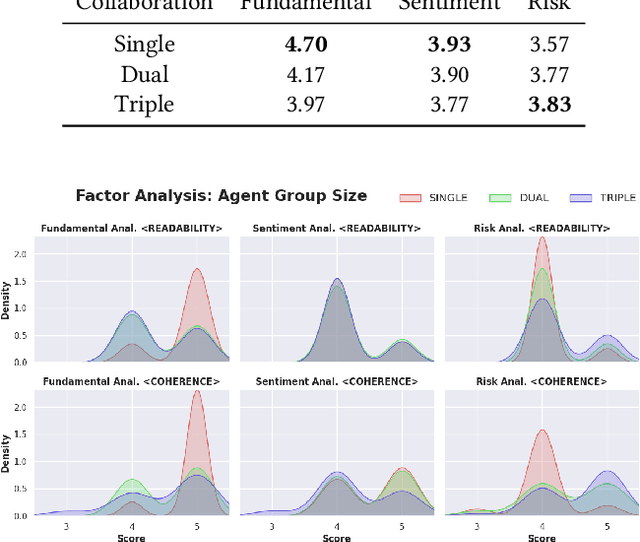
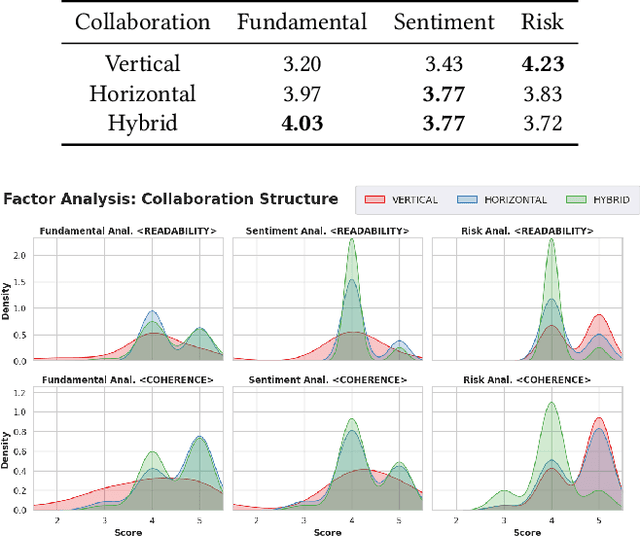
In recent years, the application of generative artificial intelligence (GenAI) in financial analysis and investment decision-making has gained significant attention. However, most existing approaches rely on single-agent systems, which fail to fully utilize the collaborative potential of multiple AI agents. In this paper, we propose a novel multi-agent collaboration system designed to enhance decision-making in financial investment research. The system incorporates agent groups with both configurable group sizes and collaboration structures to leverage the strengths of each agent group type. By utilizing a sub-optimal combination strategy, the system dynamically adapts to varying market conditions and investment scenarios, optimizing performance across different tasks. We focus on three sub-tasks: fundamentals, market sentiment, and risk analysis, by analyzing the 2023 SEC 10-K forms of 30 companies listed on the Dow Jones Index. Our findings reveal significant performance variations based on the configurations of AI agents for different tasks. The results demonstrate that our multi-agent collaboration system outperforms traditional single-agent models, offering improved accuracy, efficiency, and adaptability in complex financial environments. This study highlights the potential of multi-agent systems in transforming financial analysis and investment decision-making by integrating diverse analytical perspectives.
FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models
May 23, 2024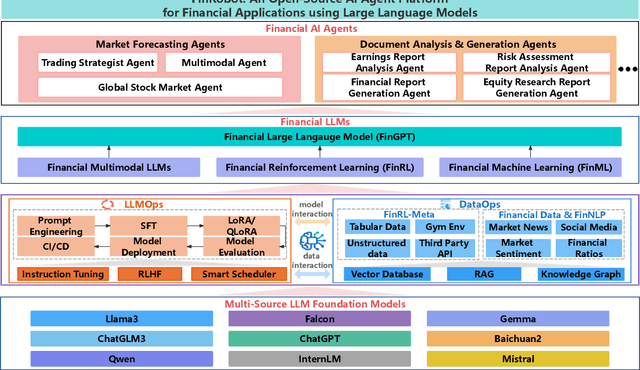
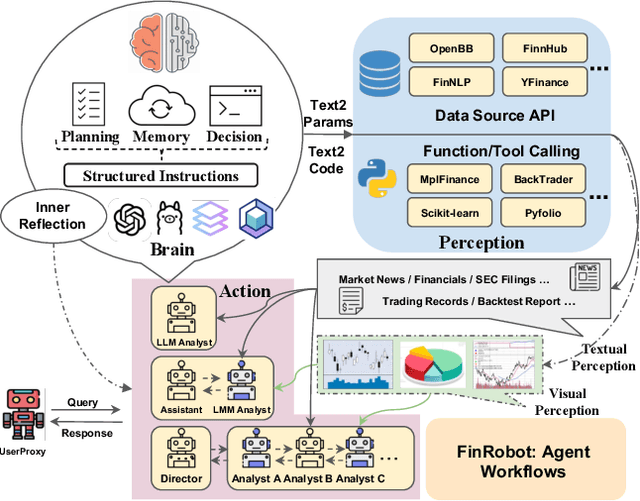
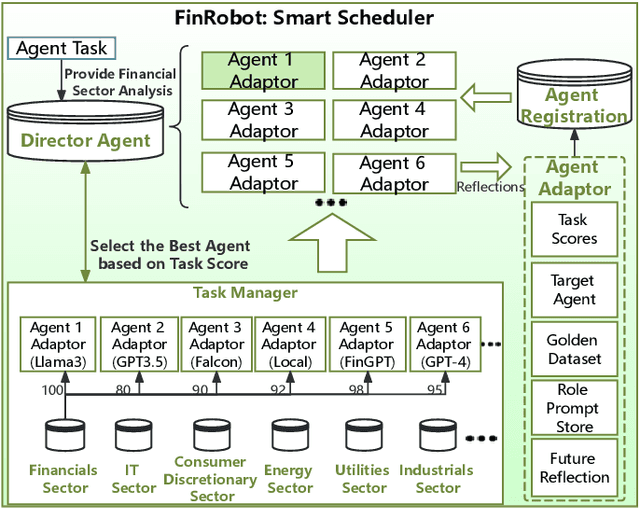

As financial institutions and professionals increasingly incorporate Large Language Models (LLMs) into their workflows, substantial barriers, including proprietary data and specialized knowledge, persist between the finance sector and the AI community. These challenges impede the AI community's ability to enhance financial tasks effectively. Acknowledging financial analysis's critical role, we aim to devise financial-specialized LLM-based toolchains and democratize access to them through open-source initiatives, promoting wider AI adoption in financial decision-making. In this paper, we introduce FinRobot, a novel open-source AI agent platform supporting multiple financially specialized AI agents, each powered by LLM. Specifically, the platform consists of four major layers: 1) the Financial AI Agents layer that formulates Financial Chain-of-Thought (CoT) by breaking sophisticated financial problems down into logical sequences; 2) the Financial LLM Algorithms layer dynamically configures appropriate model application strategies for specific tasks; 3) the LLMOps and DataOps layer produces accurate models by applying training/fine-tuning techniques and using task-relevant data; 4) the Multi-source LLM Foundation Models layer that integrates various LLMs and enables the above layers to access them directly. Finally, FinRobot provides hands-on for both professional-grade analysts and laypersons to utilize powerful AI techniques for advanced financial analysis. We open-source FinRobot at \url{https://github.com/AI4Finance-Foundation/FinRobot}.
FinGPT: Instruction Tuning Benchmark for Open-Source Large Language Models in Financial Datasets
Oct 07, 2023



In the swiftly expanding domain of Natural Language Processing (NLP), the potential of GPT-based models for the financial sector is increasingly evident. However, the integration of these models with financial datasets presents challenges, notably in determining their adeptness and relevance. This paper introduces a distinctive approach anchored in the Instruction Tuning paradigm for open-source large language models, specifically adapted for financial contexts. Through this methodology, we capitalize on the interoperability of open-source models, ensuring a seamless and transparent integration. We begin by explaining the Instruction Tuning paradigm, highlighting its effectiveness for immediate integration. The paper presents a benchmarking scheme designed for end-to-end training and testing, employing a cost-effective progression. Firstly, we assess basic competencies and fundamental tasks, such as Named Entity Recognition (NER) and sentiment analysis to enhance specialization. Next, we delve into a comprehensive model, executing multi-task operations by amalgamating all instructional tunings to examine versatility. Finally, we explore the zero-shot capabilities by earmarking unseen tasks and incorporating novel datasets to understand adaptability in uncharted terrains. Such a paradigm fortifies the principles of openness and reproducibility, laying a robust foundation for future investigations in open-source financial large language models (FinLLMs).
Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models
Oct 06, 2023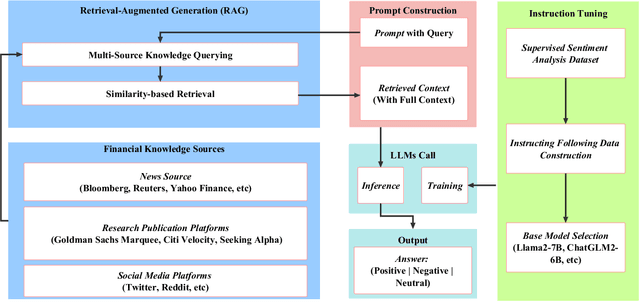

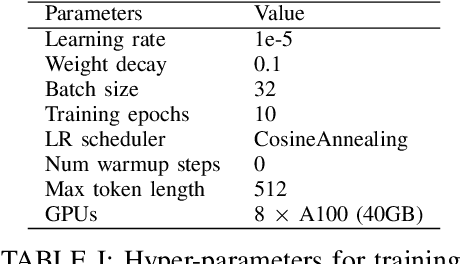
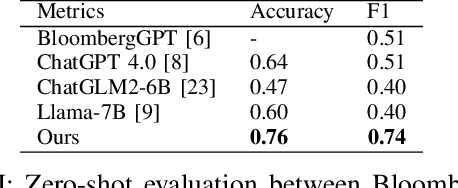
Financial sentiment analysis is critical for valuation and investment decision-making. Traditional NLP models, however, are limited by their parameter size and the scope of their training datasets, which hampers their generalization capabilities and effectiveness in this field. Recently, Large Language Models (LLMs) pre-trained on extensive corpora have demonstrated superior performance across various NLP tasks due to their commendable zero-shot abilities. Yet, directly applying LLMs to financial sentiment analysis presents challenges: The discrepancy between the pre-training objective of LLMs and predicting the sentiment label can compromise their predictive performance. Furthermore, the succinct nature of financial news, often devoid of sufficient context, can significantly diminish the reliability of LLMs' sentiment analysis. To address these challenges, we introduce a retrieval-augmented LLMs framework for financial sentiment analysis. This framework includes an instruction-tuned LLMs module, which ensures LLMs behave as predictors of sentiment labels, and a retrieval-augmentation module which retrieves additional context from reliable external sources. Benchmarked against traditional models and LLMs like ChatGPT and LLaMA, our approach achieves 15\% to 48\% performance gain in accuracy and F1 score.
Instruct-FinGPT: Financial Sentiment Analysis by Instruction Tuning of General-Purpose Large Language Models
Jun 22, 2023Sentiment analysis is a vital tool for uncovering insights from financial articles, news, and social media, shaping our understanding of market movements. Despite the impressive capabilities of large language models (LLMs) in financial natural language processing (NLP), they still struggle with accurately interpreting numerical values and grasping financial context, limiting their effectiveness in predicting financial sentiment. In this paper, we introduce a simple yet effective instruction tuning approach to address these issues. By transforming a small portion of supervised financial sentiment analysis data into instruction data and fine-tuning a general-purpose LLM with this method, we achieve remarkable advancements in financial sentiment analysis. In the experiment, our approach outperforms state-of-the-art supervised sentiment analysis models, as well as widely used LLMs like ChatGPT and LLaMAs, particularly in scenarios where numerical understanding and contextual comprehension are vital.
FinGPT: Open-Source Financial Large Language Models
Jun 09, 2023
Large language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). While proprietary models like BloombergGPT have taken advantage of their unique data accumulation, such privileged access calls for an open-source alternative to democratize Internet-scale financial data. In this paper, we present an open-source large language model, FinGPT, for the finance sector. Unlike proprietary models, FinGPT takes a data-centric approach, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. We highlight the importance of an automatic data curation pipeline and the lightweight low-rank adaptation technique in building FinGPT. Furthermore, we showcase several potential applications as stepping stones for users, such as robo-advising, algorithmic trading, and low-code development. Through collaborative efforts within the open-source AI4Finance community, FinGPT aims to stimulate innovation, democratize FinLLMs, and unlock new opportunities in open finance. Two associated code repos are \url{https://github.com/AI4Finance-Foundation/FinGPT} and \url{https://github.com/AI4Finance-Foundation/FinNLP}
Dynamic Datasets and Market Environments for Financial Reinforcement Learning
Apr 25, 2023



The financial market is a particularly challenging playground for deep reinforcement learning due to its unique feature of dynamic datasets. Building high-quality market environments for training financial reinforcement learning (FinRL) agents is difficult due to major factors such as the low signal-to-noise ratio of financial data, survivorship bias of historical data, and model overfitting. In this paper, we present FinRL-Meta, a data-centric and openly accessible library that processes dynamic datasets from real-world markets into gym-style market environments and has been actively maintained by the AI4Finance community. First, following a DataOps paradigm, we provide hundreds of market environments through an automatic data curation pipeline. Second, we provide homegrown examples and reproduce popular research papers as stepping stones for users to design new trading strategies. We also deploy the library on cloud platforms so that users can visualize their own results and assess the relative performance via community-wise competitions. Third, we provide dozens of Jupyter/Python demos organized into a curriculum and a documentation website to serve the rapidly growing community. The open-source codes for the data curation pipeline are available at https://github.com/AI4Finance-Foundation/FinRL-Meta