 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Missing Becomes Structure: Intent-Preserving Policy Completion from Financial KOL Discourse
Apr 15, 2026Key Opinion Leader (KOL) discourse on social media is widely consumed as investment guidance, yet turning it into executable trading strategies without injecting assumptions about unspecified execution decisions remains an open problem. We observe that the gaps in KOL statements are not random deficiencies but a structured separation: KOLs express directional intent (what to buy or sell and why) while leaving execution decisions (when, how much, how long) systematically unspecified. Building on this observation, we propose an intent-preserving policy completion framework that treats KOL discourse as a partial trading policy and uses offline reinforcement learning to complete the missing execution decisions around the KOL-expressed intent. Experiments on multimodal KOL discourse from YouTube and X (2022-2025) show that KICL achieves the best return and Sharpe ratio on both platforms while maintaining zero unsupported entries and zero directional reversals, and ablations confirm that the full framework yields an 18.9% return improvement over the KOL-aligned baseline.
Enhancing LLM Reliability via Explicit Knowledge Boundary Modeling
Mar 04, 2025Large language models (LLMs) frequently hallucinate due to misaligned self-awareness, generating erroneous outputs when addressing queries beyond their knowledge boundaries. While existing approaches mitigate hallucinations via uncertainty estimation or query rejection, they suffer from computational inefficiency or sacrificed helpfulness. To address these issues, we propose the Explicit Knowledge Boundary Modeling (EKBM) framework, integrating fast and slow reasoning systems to harmonize reliability and usability. The framework first employs a fast-thinking model to generate confidence-labeled responses, enabling immediate use of high-confidence outputs. For uncertain predictions, a slow refinement model conducts targeted reasoning to improve accuracy. To align model behavior with our proposed object, we propose a hybrid training pipeline, enhancing self-awareness without degrading task performance. Evaluations on dialogue state tracking tasks demonstrate that EKBM achieves superior model reliability over uncertainty-based baselines. Further analysis reveals that refinement substantially boosts accuracy while maintaining low computational overhead. Our work establishes a scalable paradigm for advancing LLM reliability and balancing accuracy and practical utility in error-sensitive applications.
FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
Dec 14, 2024



Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs' ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8\% compared to existing methods.
OPAL: Ontology-Aware Pretrained Language Model for End-to-End Task-Oriented Dialogue
Sep 10, 2022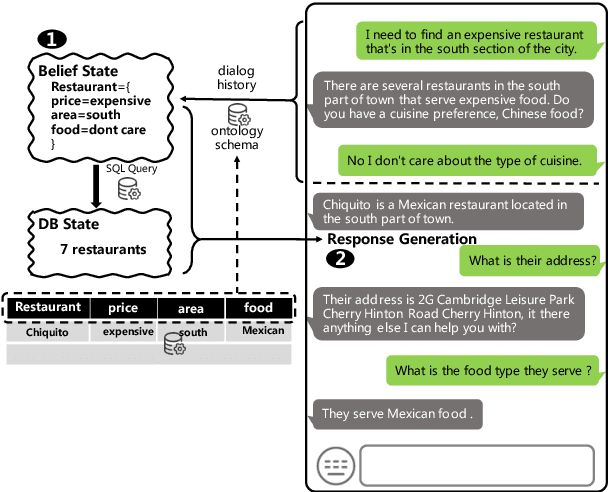

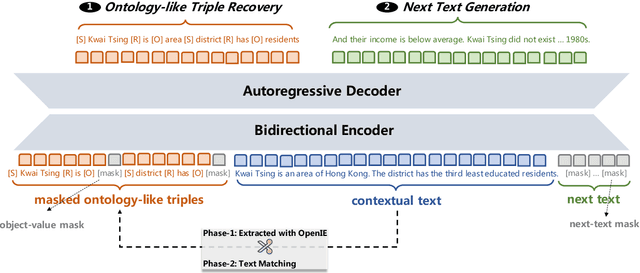

This paper presents an ontology-aware pretrained language model (OPAL) for end-to-end task-oriented dialogue (TOD). Unlike chit-chat dialogue models, task-oriented dialogue models fulfill at least two task-specific modules: dialogue state tracker (DST) and response generator (RG). The dialogue state consists of the domain-slot-value triples, which are regarded as the user's constraints to search the domain-related databases. The large-scale task-oriented dialogue data with the annotated structured dialogue state usually are inaccessible. It prevents the development of the pretrained language model for the task-oriented dialogue. We propose a simple yet effective pretraining method to alleviate this problem, which consists of two pretraining phases. The first phase is to pretrain on large-scale contextual text data, where the structured information of the text is extracted by the information extracting tool. To bridge the gap between the pretraining method and downstream tasks, we design two pretraining tasks: ontology-like triple recovery and next-text generation, which simulates the DST and RG, respectively. The second phase is to fine-tune the pretrained model on the TOD data. The experimental results show that our proposed method achieves an exciting boost and get competitive performance even without any TOD data on CamRest676 and MultiWOZ benchmarks.
DialogZoo: Large-Scale Dialog-Oriented Task Learning
May 25, 2022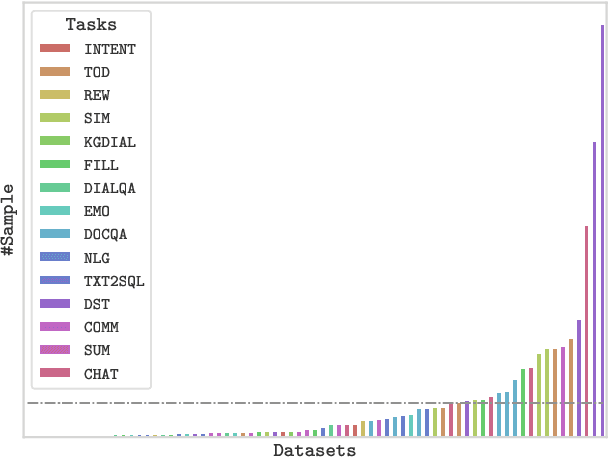
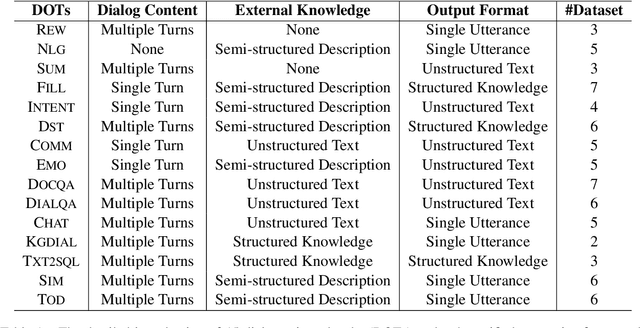
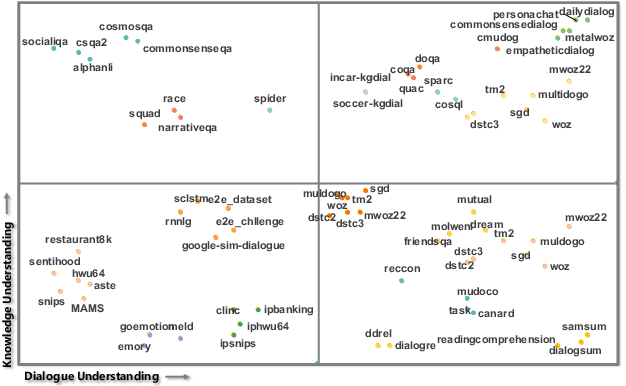
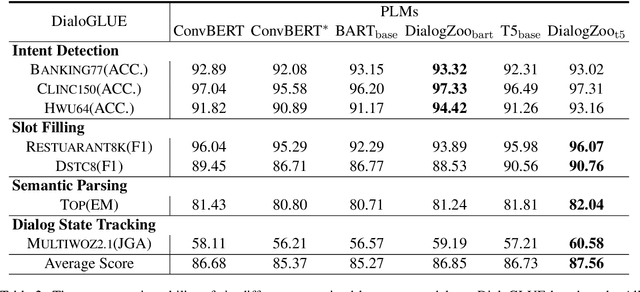
Building unified conversational agents has been a long-standing goal of the dialogue research community. Most previous works only focus on a subset of various dialogue tasks. In this work, we aim to build a unified foundation model which can solve massive diverse dialogue tasks. To achieve this goal, we first collect a large-scale well-labeled dialogue dataset from 73 publicly available datasets. In addition to this dataset, we further propose two dialogue-oriented self-supervised tasks, and finally use the mixture of supervised and self-supervised datasets to train our foundation model. The supervised examples make the model learn task-specific skills, while the self-supervised examples make the model learn more general skills. We evaluate our model on various downstream dialogue tasks. The experimental results show that our method not only improves the ability of dialogue generation and knowledge distillation, but also the representation ability of models.
UniDU: Towards A Unified Generative Dialogue Understanding Framework
Apr 10, 2022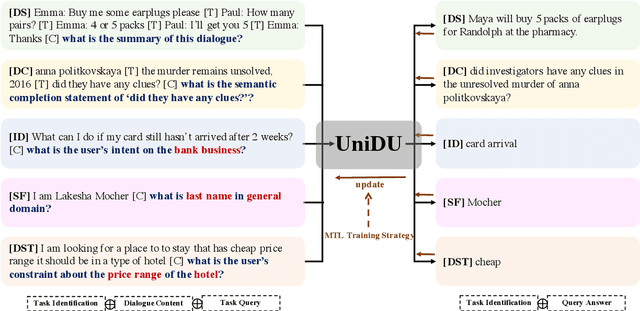
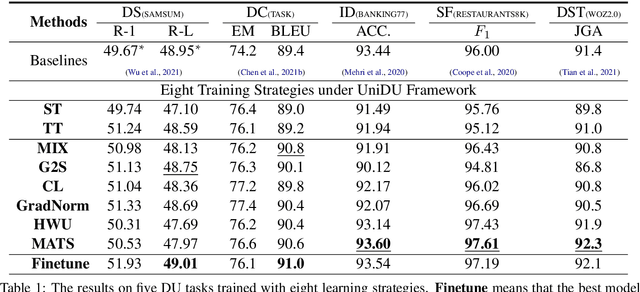

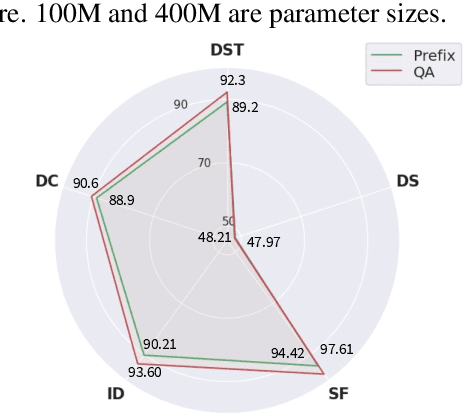
With the development of pre-trained language models, remarkable success has been witnessed in dialogue understanding (DU) direction. However, the current DU approaches just employ an individual model for each DU task, independently, without considering the shared knowledge across different DU tasks. In this paper, we investigate a unified generative dialogue understanding framework, namely UniDU, to achieve information exchange among DU tasks. Specifically, we reformulate the DU tasks into unified generative paradigm. In addition, to consider different training data for each task, we further introduce model-agnostic training strategy to optimize unified model in a balanced manner. We conduct the experiments on ten dialogue understanding datasets, which span five fundamental tasks: dialogue summary, dialogue completion, slot filling, intent detection and dialogue state tracking. The proposed UniDU framework outperforms task-specific well-designed methods on all 5 tasks. We further conduct comprehensive analysis experiments to study the effect factors. The experimental results also show that the proposed method obtains promising performance on unseen dialogue domain.
An Investigation on Different Underlying Quantization Schemes for Pre-trained Language Models
Oct 14, 2020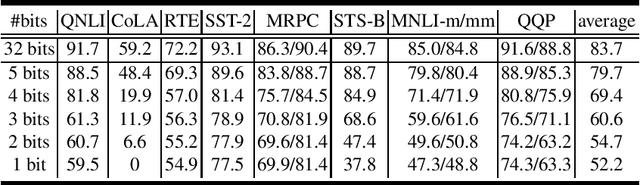
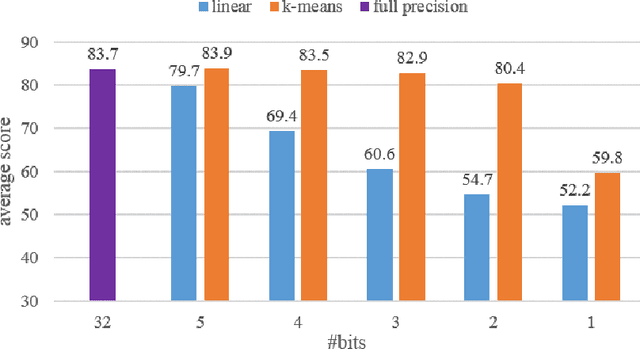
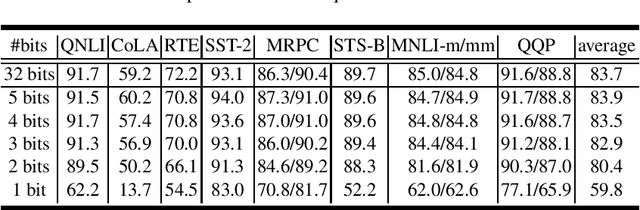
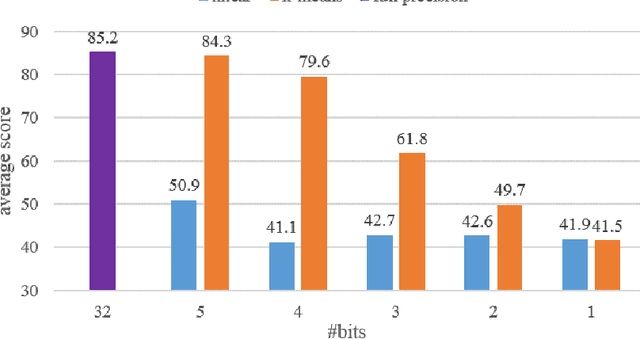
Recently, pre-trained language models like BERT have shown promising performance on multiple natural language processing tasks. However, the application of these models has been limited due to their huge size. To reduce its size, a popular and efficient way is quantization. Nevertheless, most of the works focusing on BERT quantization adapted primary linear clustering as the quantization scheme, and few works try to upgrade it. That limits the performance of quantization significantly. In this paper, we implement k-means quantization and compare its performance on the fix-precision quantization of BERT with linear quantization. Through the comparison, we verify that the effect of the underlying quantization scheme upgrading is underestimated and there is a huge development potential of k-means quantization. Besides, we also compare the two quantization schemes on ALBERT models to explore the robustness differences between different pre-trained models.